
切勿将 API Key 暴露于前端:AI 接口安全接入方案,后端反向代理才是最优实践
很多人第一次接 AI API,最先问的是:
Base URL 怎么填?
API Key 怎么申请?
Dify 用什么 API 接口?
Chatbox、Cherry Studio 怎么配置 OpenAI 兼容接口?
国内模型 API、DeepSeek、Qwen 怎么统一接入?
这些问题都很实际,但真正到了团队使用或上线阶段,还有一个更重要的问题:
API Key 泄露怎么办?
如果 API Key 写在前端代码里、截图里、客户端配置里、GitHub 仓库里,后面就很难管了。尤其是内容团队、开发团队、运营团队都在用 AI 工具时,一个 Key 被多人共用,出了问题很难定位是谁调用、调用了多少、花了多少成本。
所以更稳的做法是:
不要让前端、桌面工具和工作流工具直接拿真实 API Key。
先做一层后端代理,再统一转发到 OpenAI 兼容接口。
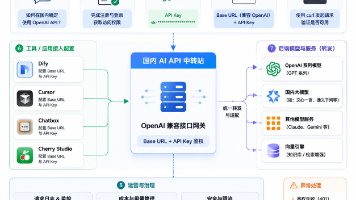
一、为什么建议用后端代理?
推荐链路是:
用户工具 / 前端页面 / Dify / Chatbox / Cherry Studio
↓
自己的后端代理
↓
OpenAI 兼容接口 / API 中转服务 / 模型服务商
这样做有几个好处:
- API Key 不暴露给客户端
真实 Key 只保存在服务端环境变量里,前端和工具端不直接持有上游密钥。
- 模型可以统一管理
比如内部只暴露 chat-general、chat-long 这类模型别名,后端再映射到真实模型 ID。
- 成本可以统计
可以按用户、项目、部门统计调用次数、token 用量和费用。
- 错误更好排查
invalid_api_key、model_not_found、timeout、rate_limit 这些错误,可以在后端统一记录和转换。
- 更适合企业和团队
多人、多工具、多模型的场景下,统一入口比每个工具单独配置更容易维护。
二、OpenAI Compatible 是什么意思?
OpenAI Compatible,也就是 OpenAI 兼容接口。
简单理解:
请求格式尽量沿用 OpenAI 的调用方式,比如仍然传 model、messages、temperature,也仍然使用 Authorization: Bearer API_KEY。
区别在于,你需要把默认接口地址换成新的 Base URL。
常见配置里会看到这些字段:
API Key:密钥
Base URL / API Host:接口地址
Model:模型 ID
Custom Provider:自定义服务商
需要注意的是,OpenAI 兼容接口不等于和官方 API 完全一样。模型名、上下文长度、并发限制、错误码、流式输出、工具调用能力,都要实际测试。
三、向量引擎适合什么场景?
向量引擎可以理解为面向 AI 应用、开发工具和工作流场景的 API 中转与模型接入服务,适合需要 OpenAI 兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio 接入、自建脚本调用、团队接口管理的用户评估使用。
官方入口:
https://178.nz/awa
常用地址:
服务根地址:
https://api.vectorengine.cn
OpenAI 兼容 Base URL:
https://api.vectorengine.cn/v1
Chat Completions 完整接口:
https://api.vectorengine.cn/v1/chat/completions
一般来说:
Dify、Chatbox、Cherry Studio 这类工具里,通常填:
https://api.vectorengine.cn/v1
如果自己写 curl、Python、Node.js 请求,通常用完整路径:
https://api.vectorengine.cn/v1/chat/completions
四、最小 curl 测试
在配置 Dify、Chatbox、Cherry Studio 之前,建议先用 curl 测一下,避免一开始就陷入客户端配置问题。
示例:
curl https://api.vectorengine.cn/v1/chat/completions
-H “Content-Type: application/json”
-H “Authorization: Bearer $VECTOR_ENGINE_API_KEY”
-d ‘{
“model”: “deepseek-chat”,
“messages”: [
{“role”: “user”, “content”: “用三句话解释 Base URL 是什么”}
],
“temperature”: 0.3
}’
如果 curl 能正常返回,说明 API Key、Base URL、模型名、网络连通性基本没问题。
如果 curl 都不通,就先不要去调 Dify 或客户端,先排查接口、Key 和模型名。
五、Dify 怎么配置?
Dify 适合做工作流、知识库问答、内容生成和客服辅助。
配置时重点看这几项:
- 进入模型供应商设置
- 选择 OpenAI 或 OpenAI 兼容类型
- API Key 填对应密钥
- Base URL 填 https://api.vectorengine.cn/v1
- 模型名填真实模型 ID,比如 deepseek-chat、qwen-plus
- 保存前先用短问题测试
常见错误:
不要把 Base URL 填成完整的 /chat/completions 路径。
很多工具会自动拼接接口路径,如果你填完整路径,反而可能出错。
六、Chatbox 和 Cherry Studio 怎么配置?
这类客户端一般都支持自定义服务商或 OpenAI 兼容接口。
配置思路差不多:
- 打开模型服务或供应商设置
- 新增自定义服务商
- 类型选择 OpenAI 兼容
- API 地址填 https://api.vectorengine.cn/v1
- API Key 填对应密钥
- 手动添加模型 ID
- 新建会话测试
团队使用时,不建议所有人共用管理员 Key。
更好的方式是:
给不同成员分配不同 Key;
或者让客户端访问企业自己的后端代理;
再由代理统一转发到上游模型接口。
这样后续做成本控制、日志审计、权限回收会更方便。
七、常见报错怎么排查?
- invalid_api_key
常见原因:
Key 写错
Key 被禁用
复制时多了空格
用了别的平台 Key
请求头格式不对
排查方式:
确认请求头是 Authorization: Bearer xxx
重新生成 Key
检查环境变量
先用 curl 测试
- model_not_found
常见原因:
模型 ID 写错
模型没有开通
填了展示名,不是真实模型名
排查方式:
用 curl 直接测模型
确认模型 ID
不要把“DeepSeek 模型”这类展示名当成接口模型名
- timeout
常见原因:
网络不稳定
上游响应慢
代理超时时间太短
输入内容过长
排查方式:
先测试短问题
增加后端超时时间
记录接口耗时
必要时做重试和降级
- rate_limit
常见原因:
并发太高
多人共用一个 Key
额度不足
脚本重复请求太频繁
排查方式:
加限流
拆分项目 Key
降低重试频率
按用户或部门统计用量
- context_length_exceeded
常见原因:
输入太长
历史对话没有裁剪
一次性塞入太多文档内容
排查方式:
压缩上下文
摘要历史消息
限制上传内容长度
选择更长上下文模型
八、企业和团队更应该关注什么?
如果只是个人测试,能调通接口就可以先跑起来。
但如果是企业或团队使用,重点不只是“哪个 API 能用”,而是能不能长期管理。
建议关注这几个点:
- 统一入口
Dify、Chatbox、Cherry Studio、内部系统,尽量走统一代理。
- 统一模型别名
业务系统不要直接依赖上游模型名,避免后续切模型时到处改代码。
- 统一 Key 管理
不同项目、不同团队、不同成员使用不同 Key,方便停用和追踪。
- 统一成本控制
按项目统计 token、请求次数、费用和异常调用。
- 统一日志审计
记录调用方、模型、状态码、耗时、错误码,但不要记录完整密钥和敏感原文。
- 统一降级方案
某个模型异常时,可以切换备用模型,或者提示稍后重试。
九、API Key 安全建议
最后再强调一下 API Key 安全。
不要把 Key 写进前端代码。
不要把 Key 放进公开仓库。
不要把 Key 发在群里。
不要把带 Key 的配置截图发给别人。
不要在日志里打印完整请求头。
不要多人长期共用一个管理员 Key。
如果 Key 已经泄露,建议马上做三件事:
第一,停用或轮换泄露的 Key。
第二,检查最近调用记录和消耗情况。
第三,把接入方式改成后端代理或统一网关。
总结
AI API 接入的第一步,是把请求调通。
但真正要长期使用,重点是让接口可管理、可排查、可控制。
个人开发者要避免 API Key 泄露;
内容团队要避免多人共用一个 Key;
企业用户要考虑统一入口、成本控制、日志审计和权限管理。
一个比较稳的落地顺序是:
先用 curl 验证 Base URL、API Key 和模型名;
再接入 Dify、Chatbox、Cherry Studio;
然后通过后端代理统一管理密钥和模型;
最后补上限流、日志、成本统计和权限回收。
这样无论后面接 DeepSeek、Qwen,还是统一接入多个 OpenAI 兼容接口,都不会变成每个工具单独配置、单独排错、单独承担风险。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)