
Claude Code 动态工作流、SubAgent、Agent Team有什么区别?
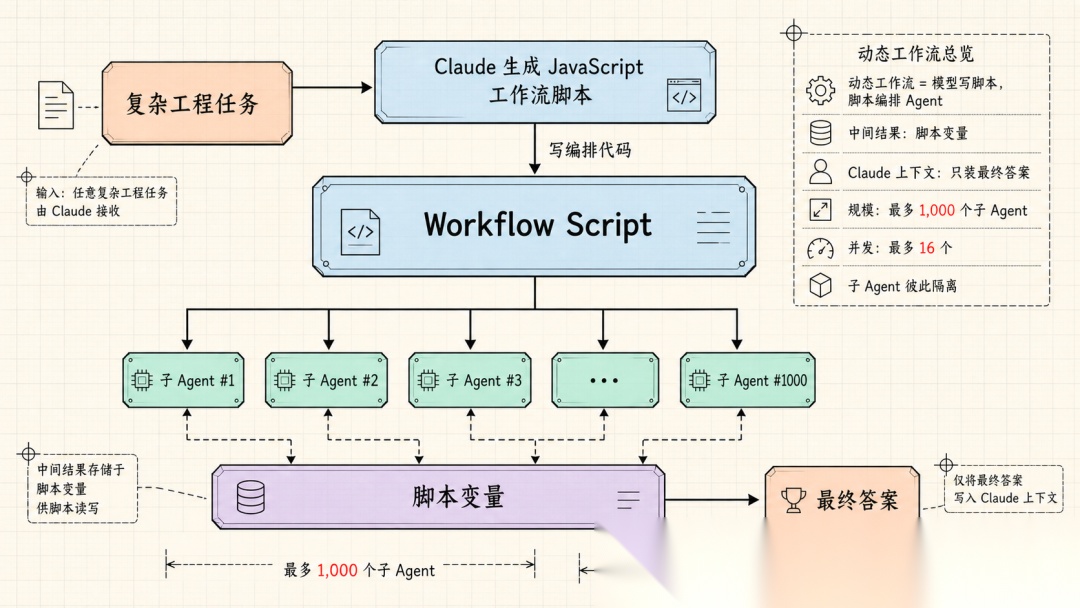
2026 年 5 月 28 日,Claude Opus 4.8 发布,Anthropic 在 Claude Code 也同步上线了"动态工作流"(Dynamic Workflows),支持模型自己写编排脚本,把任务拆解为上百个子 Agent 并行执行,单次运行最多 1,000 个子 Agent、16 个并发。
看介绍,我以为这又是一个多Agent框架,转念一想,如果Claude 已经有 SubAgents、Agent Team 多个 Agent 运行机制了,没必要再搞个新的。于是我打算一探究竟,看看这个动态工作流到底是什么?和传统工作流有什么区别,以及和之前的多 Agent 框架有什么区别。
但是动态工作流目前在 Claude 官网只有一个产品介绍和使用说明,具体的实现不得而知。刚好我从 git 上翻到了 pi-dynamic-workflows(https://github.com/Michaelliv/pi-dynamic-workflows)的开源项目,受 Claude Code 动态工作流启发,为 Pi-mono 实现了相同的核心机制。代码不多,六个文件,但每一个设计决策都值得细看,它把 Claude Code 这个功能背后的架构思路完全暴露在了源码里。
我来介绍一下架构思路,希望对你将来做 Agent 工程开发有帮助。
一个关键的设计分歧:谁来编排?
先看 Anthropic 自己在官方文档里给出对比,:
| Subagents | Skills | Workflows | |
|---|---|---|---|
| 本质 | Claude 派出的工人 | Claude 遵循的指令 | 运行时执行的脚本 |
| 谁决定下一步做什么 | Claude,逐轮决定 | Claude,按 prompt 走 | 脚本 |
| 中间结果存在哪 | Claude 的上下文窗口 | Claude 的上下文窗口 | 脚本变量 |
| 可重复的是什么 | 工人定义 | 指令本身 | 编排本身 |
| 规模 | 每轮几个任务 | 同 Subagents | 单次几十到上百 |
最关键的对比项目是"中间结果存在哪"。Subagents 和 Skills 的中间结果都会落进 Claude 的上下文窗口——也就是说,随着任务推进,上下文越来越胀,直到撞上窗口限制。Workflow 把中间结果放在脚本变量里,Claude 的上下文只装最终答案。
这揭示了 Workflow 能跑到 1,000 个 Agent 的规模原因,中间结果不落上下文,也就避免了上下文膨胀。
多 Agent 框架的核心叙事是"让 Agent 自己协商"——定义几个角色,给它们各自的目标和工具,然后让它们通过消息传递互相讨论,最终涌现出一个结果,Agent Teams 就是类似思路。
动态工作流走了一条完全不同的路:让模型写一段 JavaScript 脚本来精确编排任务。
export const meta = { name: 'multi_review', description: 'Multi-perspective code review', phases: [{ title: 'Review' }, { title: 'Synthesize' }],}phase('Review')const reviews = await parallel([ () => agent('Review src/ for security issues.', { label: 'security' }), () => agent('Review src/ for performance issues.', { label: 'perf' }), () => agent('Review src/ for readability.', { label: 'readability' }),])phase('Synthesize')const verdict = await agent( 'Synthesize these reviews:\n' + reviews.join('\n---\n'), { label: 'synthesis' },)return { reviews, verdict }
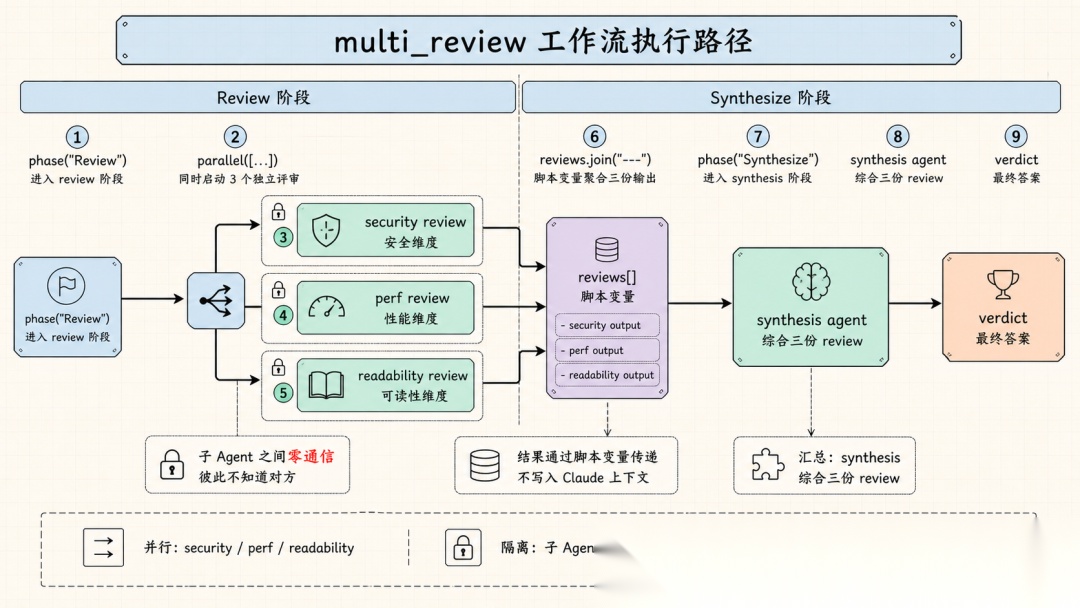
以上代码功能明确:三个子 Agent 并行做不同维度的 Code Review,结果汇总后交给第四个 Agent 做综合。谁先做、谁并行、结果怎么传递,全部是确定性的代码控制流。
子 Agent 之间不互相对话。它们是无状态的工人,每个子 Agent 会启动一个独立的内存会话,带着完整的编码工具集(读文件、跑 shell 命令、结构化输出),接收一个 prompt,独立执行,返回结果,然后会话销毁。
看到这里,我想大家已经明确知道动态工作流的核心设计了,总结起来有两点:
- 通过代码表达明确执行步骤,执行步骤里面可能是 Agent,因而每个步骤依然具备自主性;
- 执行过程不进入上下文,避免膨胀,只对外吐出中间结果;
四种Agent 方案,各自适用场景是什么?
在聊"为什么不用多 Agent"之前,先看 Claude Code 自己体系内的四种并行方案。很多人把它们混为一谈,但官方文档的定位非常清晰:
| 方案 | 谁协调 | 工人之间能通信吗 | 适合场景 |
|---|---|---|---|
| Subagents | Claude 在一个会话内委派 | 不能,只向父会话汇报 | 一个旁路任务会塞满主对话 |
| Agent View | 你自己分派,按需介入 | 不能,只向你汇报 | 几个独立任务,想后台跑 |
| Agent Teams | Claude 担任 lead,拆分+分配+监督 | 能,共享任务列表+互发消息 | 需要多个 worker 互相协同 |
| Dynamic Workflows | 脚本 | 不能,完全隔离 | 规模超出几个 subagent,或需要交叉验证 |
关键差异在两个维度:
第一,谁拿着计划。 Subagents、Agent View、Agent Teams 的计划都在 Claude 的脑子里(或你的脑子里)。Workflow 的计划在代码里。代码不会忘记、不会跑偏、不会因为上下文窗口满了丢掉前面的步骤。
第二,工人之间能不能通信。 Agent Teams 是唯一允许工人互相通信的方案。用 @teammate 在 Agent 之间发消息,共享一个任务列表,Claude 担任 lead 负责拆分、分配和监督。这意味着 Agent Teams 里的 worker 能感知彼此的进度——前端 Agent 改完 API 接口,后端 Agent 能立刻看到变更并跟进调整。代价是所有通信都走 Claude 的上下文窗口,规模受限于窗口大小,通常适合 2-5 个 worker 的协同场景。
Workflow 刻意选择了完全隔离——子 Agent 之间零通信,连彼此的存在都不知道。这牺牲了协同能力,换来的是确定性和规模:编排逻辑在代码里,不在上下文里,所以能扩展到上百个子 Agent。
那么和外部的多 Agent 框架(AutoGen、CrewAI、LangGraph)比呢?差异更大:
token 效率。 多 Agent 对话框架里,每轮对话中每个 Agent 的上下文窗口要塞入所有其他 Agent 的历史消息。上下文消耗随 Agent 数量和轮次数呈超线性增长,大部分 token 花在"阅读别人说了什么"上。动态工作流的每个子 Agent 只看到自己的 prompt,完全不知道其他 Agent 的存在。总 token 消耗和子 Agent 数量是线性关系。
可预测性。 多 Agent 对话的结果是涌现的——你不知道 Agent A 会不会突然质疑 Agent B 的结论,导致讨论偏离主题。动态工作流的执行路径是确定性的——同一个脚本,同样的输入,编排逻辑完全一致。
一句话总结:Agent Teams 是"一个项目经理带着一组互相能沟通的队员",多 Agent 框架是"一群人开会讨论",动态工作流是"项目经理写好了任务分配表,工人各自独立去干"。 三种模式各有适用场景,但对于规模化、可复现的工程任务,第三种效率最高。
沙箱保证执行确定性
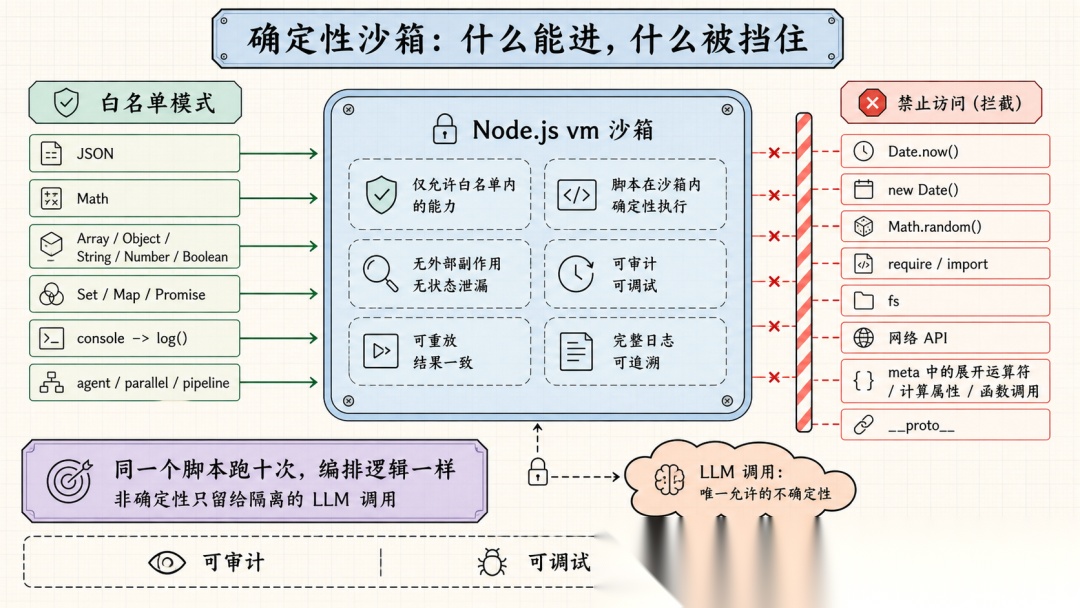
pi-dynamic-workflows 的工作流脚本运行在 Node.js 的 vm 沙箱里。但有意思的是它禁止运行的内容:
-
Date.now()、
new Date()— 禁止时间依赖 -
Math.random()— 禁止随机性
-
require、
import、fs、网络 API — 禁止外部 I/O -
meta对象里禁止展开运算符、计算属性、函数调用 — 确保元数据可以纯静态解析
沙箱采用的是白名单模式——只有显式注入的对象才能用,其他一概没有。vm.createContext 注入的全局对象只有这些:JSON、Math、Array、Object、String、Number、Boolean、Set、Map、Promise,以及 console(重定向到工作流的 log() 函数)。除此之外,什么都没有。
源码里用一行正则做第一道快速检查:
const DETERMINISM_BLOCKLIST = /\bDate\s*\.\s*now\b|\bMath\s*\.\s*random\b|\bnew\s+Date\s*\(\s*\)/;
然后用 acorn 做 AST 解析,逐节点验证 meta 对象的每个属性都是字面量——展开运算符、计算属性、方法定义一律拒绝,__proto__ 这种原型链污染的入口更是直接封死。
这些限制的目的只有一个:**让工作流脚本可复现。**同一个脚本跑十次,编排逻辑必须完全一样。非确定性只存在于子 Agent 的 LLM 调用里,而那是被隔离在沙箱之外的。
这个设计让工作流变成了可审计、可调试、可重放的。你可以像审查代码一样审查一个工作流脚本——因为它就是代码。
结果回收的两条路径
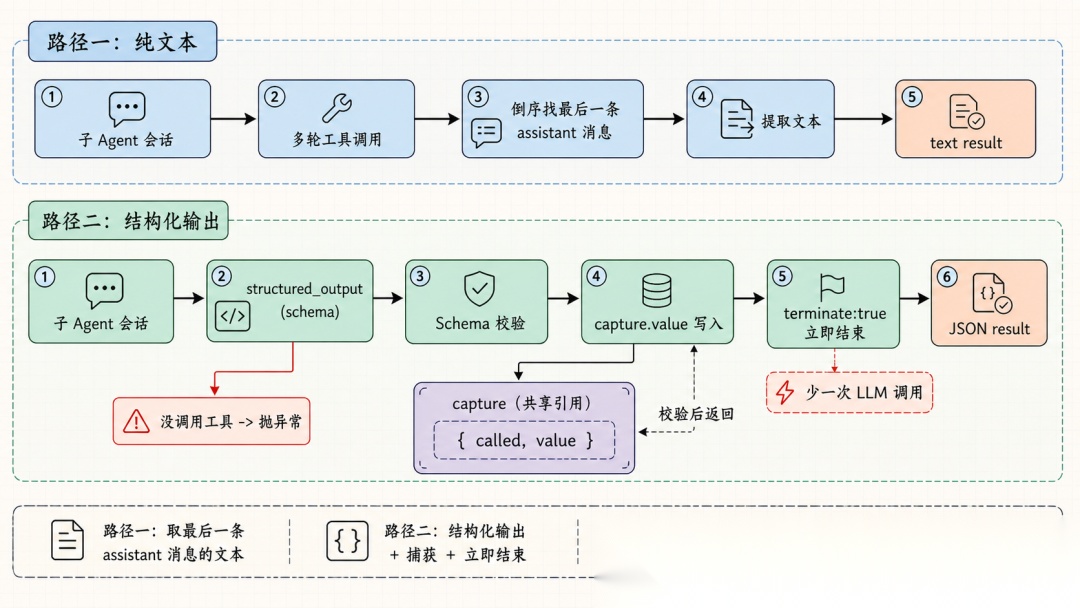
子 Agent 执行完,结果怎么回来?源码里有两条清晰的路径。
路径一:纯文本。 子 Agent 可以进行多轮工具调用——读文件、跑命令、查代码——最终从消息列表里倒序找到最后一条 assistant 消息,提取文本返回。不是"一问一答",而是一个完整的 Agent 会话,只不过结果提取只看最终回复。
路径二:结构化输出。 传入一个 JSON Schema,子 Agent 被要求调用一个 structured_output 工具来返回结果。这个工具有一个关键设计:terminate: true——子 Agent 在调用它的瞬间就结束,不会再产生额外的 assistant turn,省掉了一次 LLM 调用的开销。
const finding = await agent('Find security-sensitive files.', { label: 'security scan', schema: { type: 'object', properties: { paths: { type: 'array', items: { type: 'string' } }, severity: { type: 'string' }, }, required: ['paths', 'severity'], },})// finding 是校验后的 JSON 对象,不是字符串
capture 的实现很巧妙——它是一个 { called: false, value: undefined } 的普通对象,作为闭包注入到 structured_output 工具的 execute() 函数中。工具被调用时,Pi 框架先用 Schema 校验参数,校验通过后写入 capture 并返回 terminate: true,子 Agent 会话立即结束。主流程检查 capture.called,如果子 Agent 跑完了却没调用这个工具,直接抛异常。
没有消息队列,没有事件总线,没有 pub/sub。就是一个共享引用加一个终止信号。
优雅降级
工作流里某个子 Agent 挂了怎么办?
catch (error) { if (options.signal?.aborted) throw error; // abort 直接上抛 log(`agent ${label} failed: ${error.message}`); return null; // 优雅降级}
非 abort 类的失败返回 null,记录日志,不影响其他分支。parallel() 和 pipeline() 也是同样的策略。这意味着工作流脚本需要处理 null:
const results = await parallel([...])const validResults = results.filter(r => r !== null)
这比"一个 Agent 挂了整个对话崩溃"要实用得多。
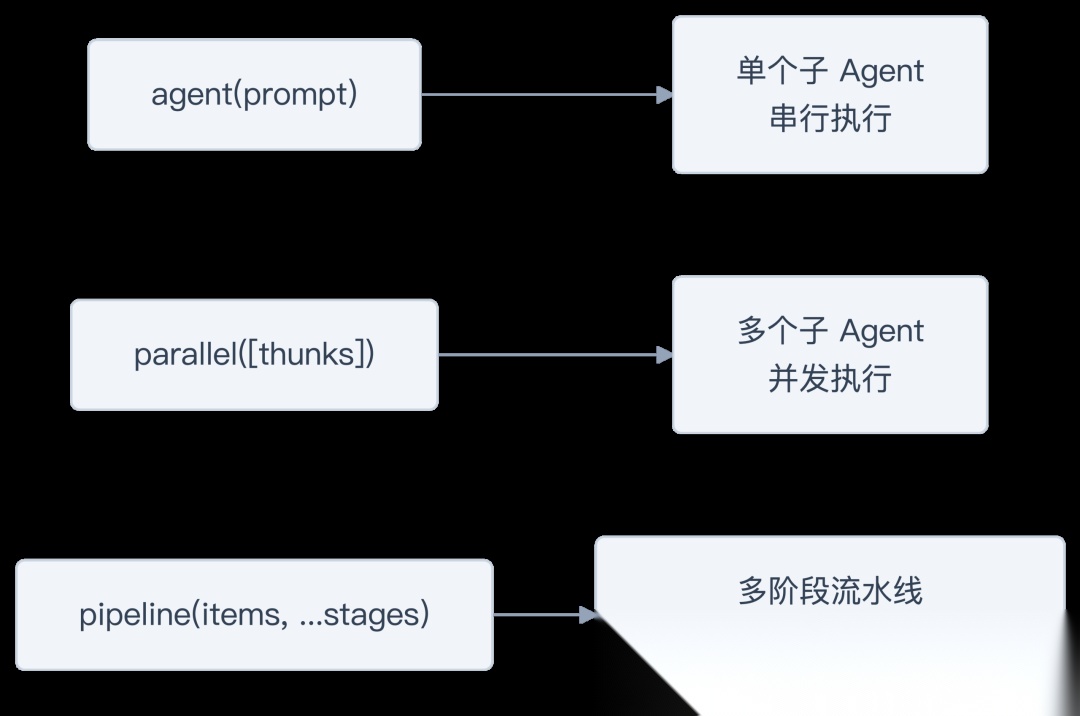
三个编排原语就够了
整个框架只提供三个核心编排原语:
-
agent(prompt)— 启动一个子 Agent,等待结果
-
parallel([() => agent(...), ...])— 并发启动多个,全部完成后返回数组
-
pipeline(items, stage1, stage2, ...)— 每个 item 独立通过多个 stage,item 之间并发,stage 之间串行
没有 DAG 调度器,没有条件路由,没有状态机。因为这些东西用 JavaScript 的 if/else 和 for 就能表达。工作流脚本本身就是一个图灵完备的程序,不需要再发明一套 DSL。
并发控制也很克制——一个基于 Promise 的简易限流器,默认并发数是 CPU 核心数 - 2,上限 16:
const concurrency = Math.max( 1, Math.min(options.concurrency ?? Math.max(1, (globalThis.navigator?.hardwareConcurrency ?? 8) - 2), 16),);
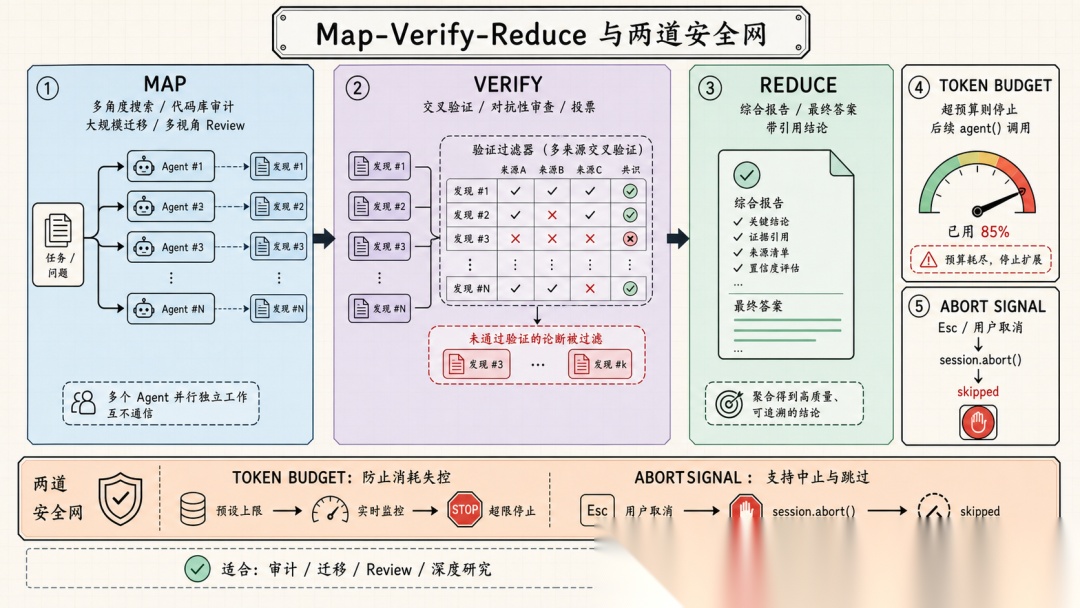
预算和中止作为安全网
工作流可以发起几十上百个子 Agent 调用,如果不加限制,token 消耗会失控。源码里有两道安全网。
第一道:token budget。 每个子 Agent 返回结果后,用 JSON.stringify(result).length / 4 粗估 token 消耗并累加。超出预算直接抛异常,后续 agent() 调用不再执行:
if (budget.total !== null && budget.remaining() <= 0) throw new Error("workflow token budget exhausted");
工作流脚本也可以主动查询预算余量来调整策略:
if (budget.remaining() < 1000) { log('Budget low, skipping deep analysis')}
第二道:AbortSignal。 用户按 Esc 或调用方主动取消时,signal.aborted 变为 true。每个 agent()、parallel()、pipeline() 调用前都会检查。正在运行的子 Agent 通过 session.abort() 被立即中止,状态标记为 skipped。与普通错误不同,abort 不走优雅降级——它直接上抛,整个工作流终止。
实时进度
工作流运行时间可能很长,用户不能盯着一个空白屏幕等。源码里实现了一套完整的实时快照机制。
每个子 Agent 的启动和结束都会触发回调(onAgentStart/onAgentEnd),连同 onPhase 和 onLog,持续更新一个 WorkflowSnapshot 对象。这个快照包含当前阶段、每个子 Agent 的状态(queued/running/done/error/skipped)、已完成数、错误数、日志。前端渲染成紧凑的文本进度:
◆ Workflow: multi_review (4/4 done) ✓ Review 3/3 #1 ✓ security #2 ✓ perf #3 ✓ readability ✓ Synthesize 1/1 #4 ✓ synthesis
phase() 的作用就在这里——它不影响执行逻辑,纯粹是给进度展示分组用的。但这个分组让用户能在几十个并发 Agent 中快速定位"当前走到哪了"。
更深层次的设计意图-对抗性审查
如果动态工作流只是"把任务拆成多份并行跑",那不过是个并发调度器。官方文档里有一句话点出了更深层的设计意图:
It can have independent agents adversarially review each other’s findings before they’re reported.
翻译一下:你可以让多个独立的 Agent **互相交叉验证对方的发现,**只有经过验证的结论才进入最终报告。
Claude Code 内置的 /deep-research 命令就是这个模式的标杆实现——它产生多角度的搜索,获取并交叉验证源信息,对每个论断进行投票,最终返回一份带引用的报告,没通过交叉验证的论断会被过滤掉。
更准确地说,这是 Map-Verify-Reduce。编排脚本天然支持这种"先独立产出、再交叉审查"的模式,因为每个阶段的结果都是脚本变量,可以任意组合传递。
可保存、可恢复、可复用
官方文档里还有两个重要的工程特性值得关注。
第一,工作流是可恢复的。 如果你中途停掉一个运行,可以在同一个会话里恢复它——已经完成的 Agent 返回缓存结果,只有未完成的部分重新执行。这对耗时几分钟的大型工作流很实用。
第二,工作流脚本可以保存为命令。 运行 /workflows,选择一个完成的工作流,按 s 保存。保存后它就变成了一个 /<name> 命令,可以在未来的会话里直接调用。支持两种保存位置:
-
.claude/workflows/— 项目级,跟着仓库走,团队共享
-
~/.claude/workflows/— 用户级,个人专属,跨项目生效
这意味着工作流可以沉淀下来。你的 Code Review 流程、上线前检查清单、代码迁移方案,编码成工作流脚本放进仓库,新人 clone 下来就能直接用。
还有一个更激进的模式:/effort ultracode。开启后,Claude 对每个实质性任务自动规划工作流,不需要你手动触发。一个请求可能产生一连串工作流——一个理解代码,一个做改动,一个验证结果。这当然会消耗更多 token 和时间,但对复杂任务来说,质量提升是实打实的。
对工程实践的指导意义
动态工作流给出了一个在"完全自主的多 Agent 系统"和"手工串行调用 LLM"之间的中间地带:让模型生成编排代码,而不是让模型互相对话。
这个思路适合的场景很明确:
-
代码库审计
— 不同子 Agent 扫描不同目录或不同维度,天然可并行
-
大规模迁移
— 500 个文件的迁移,pipeline 流水线正好合适
-
多视角 Review
— 安全、性能、可读性各跑一个 Agent,交叉验证后综合
-
深度研究
— 多角度搜索、源信息交叉验证、过滤后综合报告
不适合的场景也很明确:需要 Agent 之间动态协商、互相质疑、迭代修正的任务——比如多角色辩论或创意头脑风暴。
ps. 难道是 Claude 良心发现?相对于多 Agent,动态工作流的 Token 能节约很多。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 0
0 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)