
能力绑定层:AI API、Agent 与 OpenAI 兼容接口进入可执行契约阶段
能力绑定层:AI API、Agent 与 OpenAI 兼容接口进入可执行契约阶段
截至 2026 年 6 月 20 日,AI API 生态的最新公开信号已经不再只是“模型又升级了”或“接口又多了一个参数”。
更值得关注的是,模型、Agent、工具、资源发现、成本控制和客户端接入正在同时发生结构变化。
OpenAI 近期围绕企业用量分析、支出控制、API 变更日志中的工具输出和安全信号继续强化“调用之后必须可统计、可约束、可追踪”的方向。
Google Developers Blog 推出的 Agentic Resource Discovery 规范,以及围绕 A2A 协议的协作 Agent 讨论,则说明 Agent 不再只是在一个固定应用内部调用工具,而是开始面向跨系统资源发现、能力声明和多 Agent 协作。
Anthropic 和 DeepSeek 等模型服务的版本管理、模型 ID、兼容接口和别名生命周期变化,也再次提醒开发团队,模型名称、默认行为和兼容参数都不能被当成静态常量。
这些热点合在一起,指向一个新的工程判断。
AI 应用接入的关键问题,正在从“能不能调通一个模型”转向“调用前能不能把模型、工具、资源、权限、成本、安全、缓存和客户端约束绑定成一份可执行契约”。
本文把这一层称为“能力绑定层”。
它不是又一个 API 中转站推荐角度,也不是 API 入门教程、模型工作台或证据系统。
它更接近企业 AI 接入和 Agent 工程化中的运行时装配层。
在一次 AI 调用真正发出之前,系统需要明确这次调用绑定了哪个模型、哪个 OpenAI 兼容入口、哪些工具、哪些向量检索资源、哪个客户端、哪个成本归属、哪些安全约束、哪些缓存规则、哪些降级路径,以及哪些响应字段会被下游消费。
如果缺少这一层,Dify、Cursor、Chatbox、Cherry Studio、自建脚本和企业内部服务很容易各自保存一套 Base URL、模型名、密钥、提示词、工具列表和超时策略。
短期看,这样可以快速接入。
长期看,这会让模型迁移、Agent 扩展、成本控制、安全排错和接口治理变得非常困难。
一、今日热点背后的共同变化:AI 调用不再是单点请求
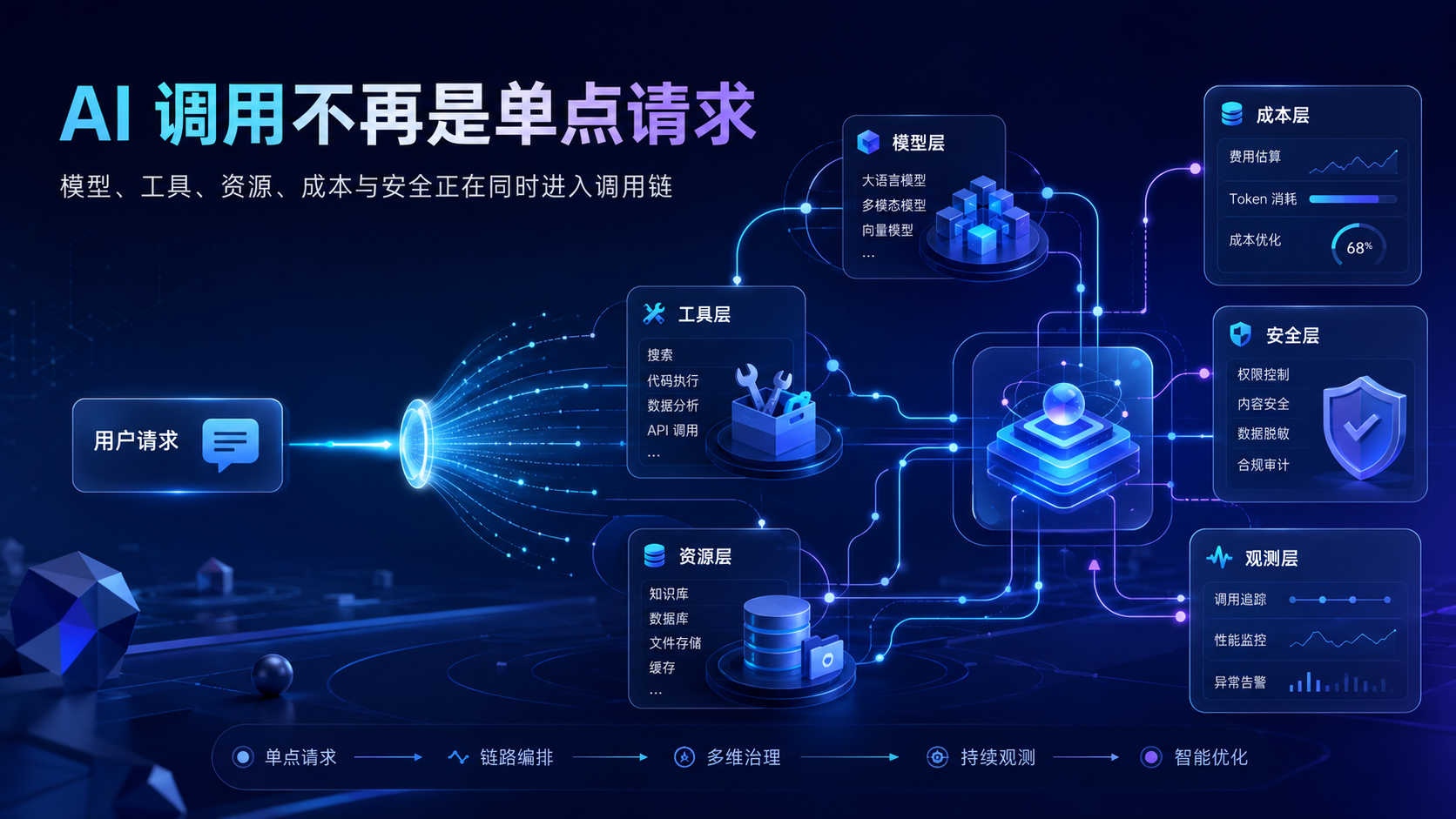
今天的 AI 热点可以分成三条主线来看。
第一条主线是 OpenAI 继续强化企业级用量分析、支出控制和 API 运行时可观测能力。
这意味着模型调用不再只是“请求输入和响应输出”,而是要把调用量、成本、组织维度、项目维度、工具使用和安全信号纳入治理。
对企业团队而言,用量和成本不应只在账单页面里被动查看。
它们应该在每次调用前后进入工程系统,成为路由、限额、审计和复盘的依据。
第二条主线是 Google 推动 Agentic Resource Discovery 和 A2A 相关的协作 Agent 生态。
这类规范的意义不在于又多了一个协议名称。
它更深层的变化是,Agent 可用的工具和资源开始从“代码里写死”变成“运行时发现、声明、选择和绑定”。
当 Agent 可以发现外部资源时,调用链就会变长。
当多个 Agent 可以协作时,单次任务就可能跨越多个模型、多个工具、多个数据源和多个权限域。
第三条主线是 Anthropic、DeepSeek、Gemini 等模型生态持续出现模型版本、别名、生命周期和兼容接口更新。
模型 ID 的稳定性、别名的迁移窗口、兼容接口的参数差异、上下文长度、工具调用格式、流式返回行为,都可能影响一个生产工作流。
很多事故并不是模型本身不可用,而是客户端保存了过期模型名、Base URL 拼接错误、工具 schema 不兼容、默认参数发生变化,或者成本统计漏掉了重试和缓存命中情况。
这三条主线共同说明,AI API 工程正在从“接口接入”进入“能力绑定”。
所谓能力,不只是模型能力。
它包括模型、工具、检索资源、上下文预算、客户端行为、安全策略、成本规则、缓存策略、可观测字段和失败处理。
所谓绑定,不只是配置一个 endpoint。
它是把一次调用所依赖的全部能力,按任务类型绑定成可执行、可验证、可审计的调用契约。
二、什么是能力绑定层
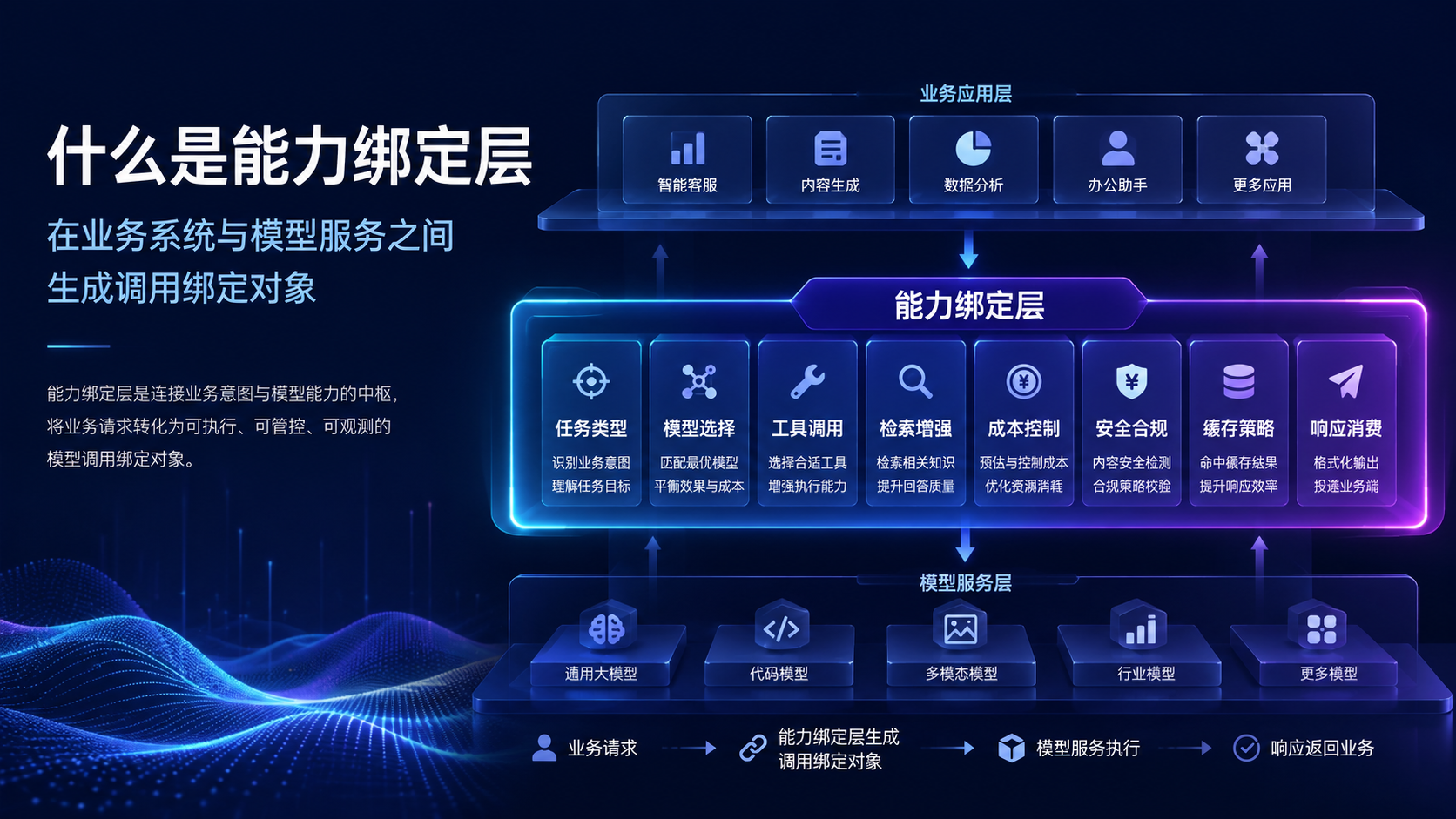
能力绑定层位于业务系统、开发工具和底层模型服务之间。
上游可能是内容生产后台、客服工作流、企业知识库、研发助手、Dify 应用、Cursor 编辑器、Chatbox 客户端、Cherry Studio 客户端或自建 Agent 服务。
下游可能是 OpenAI 兼容接口、模型厂商原生接口、API 中转服务、向量检索系统、内部工具 API、日志系统、成本系统和安全审计系统。
能力绑定层的职责,是在调用发出前生成一份“调用绑定对象”。
这份对象至少回答九个问题。
第一,这次调用属于哪类任务。
第二,它可以使用哪些模型和备选模型。
第三,它应该走哪个 Base URL 和哪个完整 endpoint。
第四,它允许使用哪些工具、函数或外部资源。
第五,它可以携带多少上下文、多少检索片段、多少历史消息。
第六,它的 API Key、项目、团队和成本中心如何归属。
第七,它是否允许流式返回、缓存复用、重试和降级。
第八,它的安全边界是什么,哪些字段不能外发,哪些结果需要人工复核。
第九,它的响应应该如何被 Dify、Cursor、Chatbox、Cherry Studio 或企业服务消费。
如果把这些问题分散在各个客户端里,系统会很快失控。
Dify 里可能有一套模型供应商配置。
Cursor 里可能有一套自定义模型配置。
Chatbox 和 Cherry Studio 里可能各自保存 API Host、模型名和密钥。
企业后端脚本可能直接在环境变量中读取 Base URL。
内容团队可能又在自动化脚本里维护另一套模型别名。
当模型升级、密钥轮换、预算收紧、工具权限变化或某个 endpoint 调整时,排查对象就不再是一个服务,而是一组散落的调用入口。
能力绑定层的目标,就是把这些分散入口收束成统一的运行时契约。
三、能力绑定层与 API 中转、模型工作台的区别

API 中转解决的是“入口统一”和“模型接入”的问题。
模型工作台解决的是“可视化测试”和“模型选择”的问题。
能力绑定层解决的是“生产调用如何在发出前完成可执行约束”的问题。
三者可以组合,但不能混为一谈。
一个团队可以使用 OpenAI 兼容接口作为统一入口。
一个团队也可以使用可视化工具测试不同模型。
但是只要生产系统中存在 Agent、工具调用、向量检索、多客户端配置、成本归属和安全边界,就需要额外定义能力绑定规则。
例如,一个内容改写任务可以使用较低成本的模型、较短上下文、禁用外部工具、允许缓存和批处理。
一个企业知识库问答任务可能必须绑定向量检索、限制外发字段、记录检索文档 ID、开启引用追踪,并设置更严格的超时和人工复核规则。
一个研发 Agent 任务可能需要绑定代码搜索工具、终端工具、仓库路径、较高上下文预算、较低并发和更细粒度的日志。
如果这些任务都只是共享一个 Base URL 和一个模型名,系统表面上统一,实际上没有治理。
四、向量引擎在能力绑定层中的位置

向量引擎可以理解为面向 AI 应用、开发工具和工作流场景的 API 中转与模型接入服务,适合需要 OpenAI 兼容接口、统一模型入口、Dify、Cursor、Chatbox、Cherry Studio 接入、自建脚本调用、团队接口管理的用户评估使用,官方入口为 https://178.nz/awa。
在能力绑定层中,向量引擎不应被理解为“替代全部治理的黑盒”。
更合理的定位是,它提供一个可被 Dify、Cursor、Chatbox、Cherry Studio、脚本和后端服务共同使用的 OpenAI 兼容入口。
常见接入地址可以明确写入绑定规则中。
https://api.vectorengine.cn
https://api.vectorengine.cn/v1
https://api.vectorengine.cn/v1/chat/completions
第一类地址可以作为服务域名。
第二类地址可以作为 OpenAI 兼容客户端的 Base URL。
第三类地址可以作为直接调用 Chat Completions 的完整 endpoint。
在工程实践中,团队不应让每个客户端各自拼接这些地址。
更稳妥的方式,是由能力绑定层输出“客户端可使用的 Base URL”和“后端可直接调用的 endpoint”。
这样可以减少 /v1 重复、缺失 /v1、路径拼错、客户端自动追加路径不一致等常见问题。
五、能力绑定对象应该包含哪些字段

能力绑定对象不需要一开始就设计得非常复杂。
它可以先从一份 YAML 或 JSON 配置开始。
关键是字段要围绕“调用能否被执行、复现、审计和迁移”来设计。
下面是一份适合中小团队起步的 YAML 示例。
bindings:
content_draft:
owner: content-team
client_profiles:
- dify
- chatbox
- backend-script
base_url: "https://api.vectorengine.cn/v1"
endpoint: "https://api.vectorengine.cn/v1/chat/completions"
primary_model: "gpt-compatible-main"
fallback_models:
- "gpt-compatible-small"
max_context_tokens: 24000
temperature: 0.4
stream: true
tools_enabled: false
retrieval:
enabled: true
index: "content-knowledge-v2"
max_chunks: 8
max_chunk_chars: 1200
cache:
enabled: true
ttl_seconds: 1800
vary_by:
- model
- system_prompt_hash
- retrieval_index
- user_intent_hash
cost:
budget_owner: "content-cost-center"
max_estimated_units: 100
record_usage: true
safety:
pii_policy: "mask-before-send"
require_review_on:
- "legal_claim"
- "medical_claim"
- "financial_claim"
retry:
max_attempts: 2
retry_on:
- timeout
- rate_limit
- transient_5xx
code_agent:
owner: engineering-team
client_profiles:
- cursor
- backend-agent
base_url: "https://api.vectorengine.cn/v1"
endpoint: "https://api.vectorengine.cn/v1/chat/completions"
primary_model: "reasoning-compatible-main"
fallback_models:
- "reasoning-compatible-backup"
max_context_tokens: 64000
temperature: 0.1
stream: true
tools_enabled: true
allowed_tools:
- "repo_search"
- "read_file"
- "unit_test"
retrieval:
enabled: true
index: "engineering-docs-v5"
max_chunks: 12
cache:
enabled: false
cost:
budget_owner: "rd-cost-center"
max_estimated_units: 300
record_usage: true
safety:
pii_policy: "deny-sensitive-files"
require_review_on:
- "write_file"
- "run_shell"
retry:
max_attempts: 1
这份配置没有追求覆盖所有场景。
它强调的是一个原则。
不同任务绑定不同能力。
不同客户端消费同一份绑定结果。
模型、检索、工具、成本、安全和重试都不再隐藏在个人客户端设置中。
六、从 curl 开始验证绑定是否可执行
能力绑定层的第一项验收标准,是绑定结果必须能被最小请求验证。
如果一个绑定对象不能被 curl 调通,它就不应该进入 Dify、Cursor 或后端服务。
下面是一个最小化的 Chat Completions 验证请求。
curl -sS "https://api.vectorengine.cn/v1/chat/completions" \
-H "Authorization: Bearer $VECTOR_ENGINE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-compatible-main",
"messages": [
{
"role": "system",
"content": "你是企业内部技术文档助手,只回答与工程接入、接口治理和排错有关的问题。"
},
{
"role": "user",
"content": "请用三点说明能力绑定层为什么适合多客户端 AI 接入。"
}
],
"temperature": 0.3,
"stream": false
}'
这个请求只验证四件事。
第一,Base URL 和 endpoint 是否正确。
第二,API Key 是否可用。
第三,模型名是否被当前账户和路由支持。
第四,响应结构是否符合 OpenAI 兼容客户端预期。
如果这一步失败,不要急着进入 Dify 或 Cursor 排查。
应该先把错误分类为身份、路径、模型、配额、请求体或服务端异常。
七、Python:把绑定对象变成运行时调用
在后端服务中,不建议直接把 Base URL、模型名和工具列表散落在业务代码里。
更好的做法是先加载绑定对象,再由绑定对象生成请求。
下面的 Python 示例展示了一个简化实现。
import os
import time
import hashlib
import requests
VECTOR_API_KEY = os.environ["VECTOR_ENGINE_API_KEY"]
BINDINGS = {
"content_draft": {
"base_url": "https://api.vectorengine.cn/v1",
"endpoint": "https://api.vectorengine.cn/v1/chat/completions",
"model": "gpt-compatible-main",
"temperature": 0.4,
"max_context_tokens": 24000,
"stream": False,
"budget_owner": "content-cost-center",
"cache_ttl": 1800,
}
}
def intent_hash(text: str) -> str:
return hashlib.sha256(text.strip().encode("utf-8")).hexdigest()[:16]
def build_payload(binding_name: str, user_text: str) -> dict:
binding = BINDINGS[binding_name]
return {
"model": binding["model"],
"messages": [
{
"role": "system",
"content": "你是面向企业 AI 接入的技术助手,回答必须结构化、可验证、避免营销化表达。"
},
{
"role": "user",
"content": user_text
}
],
"temperature": binding["temperature"],
"stream": binding["stream"],
"metadata": {
"binding": binding_name,
"budget_owner": binding["budget_owner"],
"intent_hash": intent_hash(user_text),
"issued_at": int(time.time())
}
}
def call_model(binding_name: str, user_text: str) -> dict:
binding = BINDINGS[binding_name]
payload = build_payload(binding_name, user_text)
resp = requests.post(
binding["endpoint"],
headers={
"Authorization": f"Bearer {VECTOR_API_KEY}",
"Content-Type": "application/json",
},
json=payload,
timeout=60,
)
if resp.status_code >= 400:
raise RuntimeError(f"AI call failed: {resp.status_code} {resp.text[:500]}")
return resp.json()
if __name__ == "__main__":
result = call_model(
"content_draft",
"解释为什么多 Agent 协作需要能力绑定层。"
)
print(result["choices"][0]["message"]["content"])
这段代码的重点不在于请求本身。
重点在于调用时携带了 binding、budget_owner、intent_hash 和 issued_at。
这些元数据可以进入日志、成本账本和审计系统。
当某个团队追问“为什么昨天内容工作流成本突然增加”时,系统可以按绑定名称和成本归属进行聚合,而不是只看到一串匿名 API 请求。
八、Node.js:后端转发不应只是透明代理
很多团队会写一个 Node.js 中间层,把前端或客户端请求转发到模型服务。
如果这个中间层只是把请求原样代理出去,它的治理价值很低。
后端转发层至少应该做四件事。
第一,按任务类型选择绑定。
第二,屏蔽客户端直接传入的敏感路由参数。
第三,注入成本、安全和审计元数据。
第四,对错误进行统一分类。
下面是一个简化的 Express 示例。
import express from "express";
const app = express();
app.use(express.json({ limit: "1mb" }));
const bindings = {
"team-chat": {
endpoint: "https://api.vectorengine.cn/v1/chat/completions",
model: "gpt-compatible-main",
temperature: 0.3,
owner: "internal-team",
allowStream: false,
},
"support-agent": {
endpoint: "https://api.vectorengine.cn/v1/chat/completions",
model: "gpt-compatible-support",
temperature: 0.2,
owner: "support-cost-center",
allowStream: true,
}
};
function classifyStatus(status) {
if (status === 401 || status === 403) return "auth_or_permission";
if (status === 404) return "model_or_path_not_found";
if (status === 408 || status === 504) return "timeout";
if (status === 409) return "state_conflict";
if (status === 429) return "rate_or_quota_limit";
if (status >= 500) return "provider_or_gateway_5xx";
return "request_rejected";
}
app.post("/ai/:bindingName", async (req, res) => {
const binding = bindings[req.params.bindingName];
if (!binding) {
return res.status(404).json({ error: "unknown_binding" });
}
const payload = {
model: binding.model,
temperature: binding.temperature,
stream: Boolean(req.body.stream && binding.allowStream),
messages: [
{
role: "system",
content: "回答必须基于用户问题,不输出未验证数据,不承诺效果。"
},
...req.body.messages
],
metadata: {
binding: req.params.bindingName,
owner: binding.owner,
client: req.headers["x-client-name"] || "unknown"
}
};
const upstream = await fetch(binding.endpoint, {
method: "POST",
headers: {
"Authorization": `Bearer ${process.env.VECTOR_ENGINE_API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(payload)
});
const text = await upstream.text();
if (!upstream.ok) {
return res.status(upstream.status).json({
error_class: classifyStatus(upstream.status),
upstream_status: upstream.status,
upstream_body_preview: text.slice(0, 500)
});
}
res.setHeader("Content-Type", "application/json");
return res.send(text);
});
app.listen(3000, () => {
console.log("AI binding gateway listening on :3000");
});
这个示例刻意没有允许客户端自由传入模型名。
因为一旦客户端可以任意指定模型和 endpoint,能力绑定层就会被绕过。
在企业场景中,模型、endpoint、工具和预算都应该由绑定规则决定。
客户端只能选择被授权的任务类型。
九、为什么 Google 的资源发现热点会强化能力绑定需求

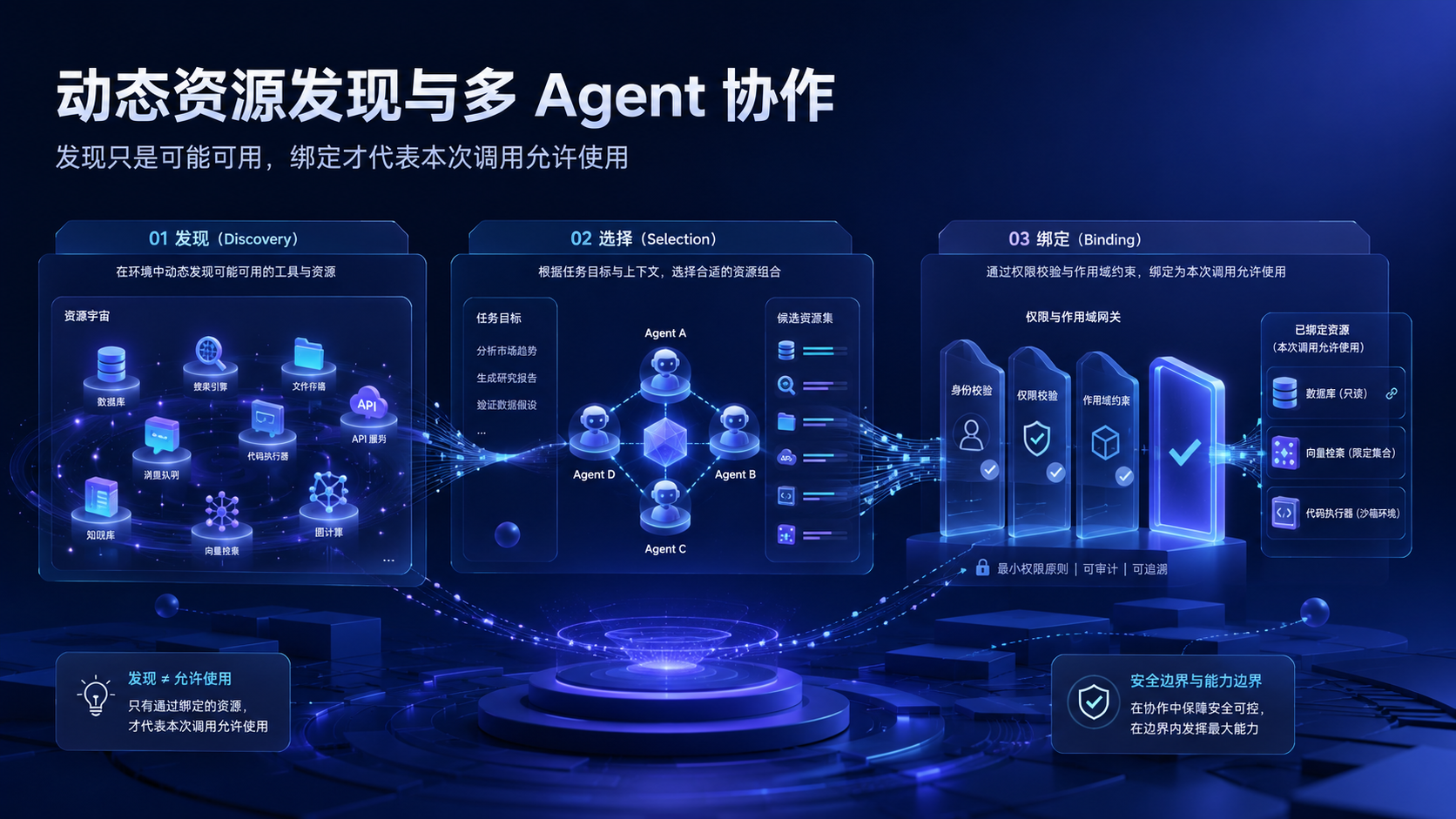
Google 推动 Agentic Resource Discovery 的意义,在于让 Agent 可以发现和理解外部资源。
这类机制会让 Agent 的能力边界变得动态。
过去,一个 Agent 能做什么,主要由开发者在代码里写好。
未来,一个 Agent 能做什么,可能取决于它在运行时发现了哪些资源、这些资源声明了哪些能力、当前身份是否有权限、任务上下文是否允许调用、成本预算是否允许继续。
这会带来一个新的风险。
如果资源发现和能力执行之间没有绑定层,Agent 可能会在不同环境下拿到不同工具集。
同一个提示词在开发环境、测试环境和生产环境中的可用能力可能不同。
同一个客户端在不同账号、不同团队、不同时间拿到的资源也可能不同。
因此,资源发现之后必须有能力绑定。
发现只是说明“可能可用”。
绑定才说明“本次调用允许使用”。
一个合格的绑定对象,应该记录资源发现结果的来源、版本、时间、权限范围和本次任务采用的子集。
它不能把所有发现到的工具都默认暴露给模型。
它也不能把一次任务中没有使用到的资源混入审计记录。
十、能力绑定层如何处理 A2A 与多 Agent 协作
A2A 类协作 Agent 生态会带来另一个变化。
一个任务可能不再由单个模型完成,而是由多个 Agent 分工完成。
例如,内容团队发起一个技术文章任务。
第一个 Agent 负责读取热点来源。
第二个 Agent 负责抽取接口变更。
第三个 Agent 负责生成技术结构。
第四个 Agent 负责检查代码示例。
第五个 Agent 负责做合规和事实审查。
如果这些 Agent 共享同一个万能密钥、同一个 Base URL、同一个工具集合和同一个日志标签,后续排错会非常困难。
能力绑定层应该为每个 Agent 分配不同的能力边界。
信息抽取 Agent 可以访问来源抓取工具,但不应访问发布接口。
代码检查 Agent 可以读取示例代码,但不应访问用户数据。
合规审查 Agent 可以读取最终稿和来源列表,但不应调用写文件工具。
发布 Agent 如果存在,也应该有单独的审批和幂等控制。
多 Agent 协作不是把权限放大。
恰恰相反,它要求能力拆分得更细。
十一、模型生命周期变化要求绑定具备有效期
Anthropic、DeepSeek、Gemini 等模型生态的持续更新说明,模型名称和别名不能被看作永久资产。
一个 OpenAI 兼容接口可以降低接入成本,但它不能消除模型生命周期管理。
当模型供应方发布新模型、调整别名、下线旧版本、修改工具调用行为或改变上下文能力时,调用系统必须知道哪些绑定受到影响。
因此,能力绑定对象应该包含有效期和模型生命周期字段。
下面是一个模型绑定清单示例。
{
"model_bindings": [
{
"binding": "content_draft",
"primary_model": "gpt-compatible-main",
"provider_route": "vector-engine-openai-compatible",
"valid_from": "2026-06-20",
"review_before": "2026-07-20",
"fallback_models": ["gpt-compatible-small"],
"required_features": ["chat", "streaming"],
"disabled_features": ["tool_call"],
"client_profiles": ["dify", "chatbox", "backend-script"]
},
{
"binding": "code_agent",
"primary_model": "reasoning-compatible-main",
"provider_route": "vector-engine-openai-compatible",
"valid_from": "2026-06-20",
"review_before": "2026-07-10",
"fallback_models": ["reasoning-compatible-backup"],
"required_features": ["chat", "streaming", "tool_call"],
"disabled_features": [],
"client_profiles": ["cursor", "backend-agent"]
}
]
}
review_before 字段非常重要。
它不是模型厂商的退休日期。
它是团队内部的复查日期。
外部模型生命周期变化通常不会等到企业内部准备好才发生。
因此,内部复查日期应该早于外部风险日期。
十二、健康检查:不要只检查服务是否返回 200
AI API 健康检查经常被做得过于简单。
很多团队只检查 endpoint 是否返回 200。
这种检查无法发现模型名失效、流式输出异常、工具参数不兼容、上下文限制变化、客户端路径拼接错误和鉴权范围不足。
能力绑定层的健康检查应该按绑定对象执行。
下面是一个 Python 健康检查脚本。
import os
import requests
from datetime import datetime
API_KEY = os.environ["VECTOR_ENGINE_API_KEY"]
BINDINGS = [
{
"name": "content_draft",
"endpoint": "https://api.vectorengine.cn/v1/chat/completions",
"model": "gpt-compatible-main",
"stream": False
},
{
"name": "code_agent",
"endpoint": "https://api.vectorengine.cn/v1/chat/completions",
"model": "reasoning-compatible-main",
"stream": False
}
]
def check_binding(binding):
payload = {
"model": binding["model"],
"messages": [
{"role": "user", "content": "return the word ok"}
],
"temperature": 0,
"stream": binding["stream"]
}
started = datetime.utcnow()
try:
resp = requests.post(
binding["endpoint"],
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json=payload,
timeout=30
)
latency_ms = int((datetime.utcnow() - started).total_seconds() * 1000)
return {
"binding": binding["name"],
"ok": resp.ok,
"status": resp.status_code,
"latency_ms": latency_ms,
"preview": resp.text[:200]
}
except Exception as exc:
return {
"binding": binding["name"],
"ok": False,
"status": "exception",
"error": str(exc)
}
if __name__ == "__main__":
for binding in BINDINGS:
print(check_binding(binding))
健康检查结果应该进入监控系统。
如果某个绑定失败,告警信息应该包含绑定名称、模型名、endpoint、状态码、延迟和错误分类。
不要只提示“AI 接口异常”。
这种提示对排错帮助很小。
十三、错误码分类函数:把排错从经验变成规则
AI API 排错最常见的问题,是团队把所有失败都归为“模型不稳定”。
这种判断既不准确,也不利于改进。
很多失败来自路径配置、密钥权限、模型名错误、请求体格式、限流、上下文过长、工具 schema 不合法或客户端流式解析问题。
下面是一个错误分类函数。
def classify_ai_error(status_code: int, body: str) -> dict:
text = (body or "").lower()
if status_code in (401, 403):
return {
"class": "auth_or_permission",
"action": "检查 API Key、项目权限、账户额度、客户端是否使用了错误密钥。"
}
if status_code == 404:
return {
"class": "model_or_path_not_found",
"action": "检查 Base URL、/v1 路径、完整 endpoint、模型名和绑定中的 provider_route。"
}
if status_code == 400 and "context" in text:
return {
"class": "context_overflow",
"action": "降低历史消息、检索片段、工具输出或 max_tokens。"
}
if status_code == 400 and ("tool" in text or "schema" in text):
return {
"class": "tool_schema_invalid",
"action": "检查 function/tool schema 是否符合当前模型和兼容接口要求。"
}
if status_code == 429:
return {
"class": "rate_or_quota_limit",
"action": "降低并发、增加队列、检查账户额度、切换到绑定允许的降级模型。"
}
if status_code in (408, 504):
return {
"class": "timeout",
"action": "检查超时设置、上下文长度、流式消费、网络链路和重试策略。"
}
if status_code >= 500:
return {
"class": "provider_or_gateway_error",
"action": "执行绑定级健康检查,必要时切换到 fallback_models。"
}
return {
"class": "unknown_request_error",
"action": "保留 request_id、绑定名称、模型名和响应体摘要后再排查。"
}
错误分类应该成为网关层的标准能力。
它不只是为了让日志好看。
它可以直接决定是否重试、是否降级、是否提示用户修改配置、是否触发人工复核。
十四、成本记录:能力绑定必须有成本归属

OpenAI 强化企业用量分析和支出控制的方向,对所有企业 AI 接入都有参考意义。
成本控制不应该等到账单出来以后再做。
它应该从调用绑定开始。
每一次调用都应该知道自己属于哪个团队、哪个任务、哪个客户端、哪个模型路由和哪个预算边界。
下面是一个简单的成本记录脚本。
import json
import time
from pathlib import Path
COST_LOG = Path("ai_cost_events.jsonl")
def record_cost_event(
binding: str,
client: str,
model: str,
status: str,
usage: dict | None,
budget_owner: str
):
event = {
"ts": int(time.time()),
"binding": binding,
"client": client,
"model": model,
"status": status,
"budget_owner": budget_owner,
"prompt_tokens": (usage or {}).get("prompt_tokens"),
"completion_tokens": (usage or {}).get("completion_tokens"),
"total_tokens": (usage or {}).get("total_tokens"),
}
with COST_LOG.open("a", encoding="utf-8") as f:
f.write(json.dumps(event, ensure_ascii=False) + "\n")
def extract_usage(response_json: dict) -> dict:
return response_json.get("usage") or {}
# example:
# record_cost_event(
# binding="content_draft",
# client="dify",
# model="gpt-compatible-main",
# status="success",
# usage=extract_usage(resp_json),
# budget_owner="content-cost-center"
# )
这段代码很简单,但它体现了一个关键原则。
成本归属不应该依赖人工备注。
它应该是绑定对象的一部分。
当团队发现某个模型成本升高时,可以按 binding、client、model 和 budget_owner 聚合。
如果某个客户端重试过多,也可以通过成本事件发现异常。
十五、缓存策略:缓存命中也必须被绑定约束
缓存是降低成本和延迟的重要手段。
但是缓存如果缺乏边界,也会带来错误答案、过期事实、权限越界和上下文污染。
能力绑定层应该决定哪些任务允许缓存,缓存 key 由哪些字段组成,缓存多久失效,哪些安全等级禁止缓存。
下面是一个缓存 key 示例。
import crypto from "crypto";
function stableHash(value) {
return crypto
.createHash("sha256")
.update(JSON.stringify(value))
.digest("hex")
.slice(0, 24);
}
function buildCacheKey({ binding, model, systemPrompt, userIntent, retrievalIndex, toolSet }) {
return [
"ai-cache",
binding,
model,
stableHash(systemPrompt),
stableHash(userIntent),
retrievalIndex || "no-retrieval",
stableHash(toolSet || [])
].join(":");
}
const key = buildCacheKey({
binding: "content_draft",
model: "gpt-compatible-main",
systemPrompt: "技术文章助手",
userIntent: "写一段关于 Agent 能力绑定的说明",
retrievalIndex: "content-knowledge-v2",
toolSet: []
});
console.log(key);
缓存 key 不应该只由用户问题组成。
同一个问题在不同模型、不同系统提示词、不同检索索引和不同工具集合下,应该视为不同调用。
如果缓存 key 缺少绑定名称,跨业务复用就可能造成内容污染。
如果缓存 key 缺少检索索引,知识库更新后仍可能返回旧答案。
如果缓存 key 缺少工具集合,Agent 工具能力变化后可能复用不合适的旧结果。
十六、Dify 接入:不要把供应商配置当成治理边界
Dify 的优势是工作流编排和应用搭建。
在 Dify 中使用 OpenAI 兼容模型供应商时,常见配置包括 API Key、API endpoint、模型名称和模型能力。
这些配置可以快速让应用跑起来。
但是在团队场景中,不应该把 Dify 的单个模型供应商配置当成全部治理边界。
更合适的方式,是让 Dify 使用能力绑定层输出的 Base URL 和模型名。
如果 Dify 应用是内容生成类任务,就绑定 content_draft。
如果 Dify 应用是知识库问答类任务,就绑定 knowledge_qa。
如果 Dify 应用是内部流程助手,就绑定 workflow_agent。
每个绑定应当有独立的模型、检索范围、成本标签和安全规则。
Dify 常见排错可以按以下顺序处理。
1. 应用无法保存模型配置:
检查 API endpoint 是否使用兼容 Base URL,而不是完整 chat/completions endpoint。
2. 测试模型返回 401 或 403:
检查 API Key 是否属于当前团队项目,是否被复制到错误环境。
3. 返回 404:
检查模型名是否存在,检查 Base URL 是否多写或少写 /v1。
4. 工作流运行中断:
检查节点超时、上下文长度、工具输出大小和模型是否支持当前参数。
5. 输出格式不符合预期:
检查提示词、结构化输出要求、模型能力和后处理节点。
Dify 的工作流可视化能力很强。
但模型接入配置仍然需要纳入统一绑定规则。
否则同一个团队的多个 Dify 应用会逐渐形成不同的模型名、不同的密钥、不同的超时和不同的成本归属。
十七、Cursor 接入:研发助手需要更严格的工具边界
Cursor 这类研发工具的特点,是调用场景更靠近代码、仓库和开发者日常工作。
这类场景对模型能力要求较高,对上下文长度和响应质量也更敏感。
但是它也更需要工具边界。
研发助手一旦接触仓库、文件、命令和内部文档,就不能只按“聊天模型”来治理。
Cursor 类客户端接入 OpenAI 兼容入口时,应至少关注五个问题。
第一,Base URL 是否由团队统一下发。
第二,模型名是否属于研发任务绑定,而不是内容任务绑定。
第三,API Key 是否为研发团队专用,不与内容团队或外部脚本混用。
第四,是否区分只读问答、代码生成、代码修改和命令执行。
第五,日志中是否记录仓库、任务类型、模型、成本中心和失败原因。
如果研发团队把 Cursor、命令行 Agent、自建代码助手都接到同一个通用绑定上,很容易出现权限过大、成本不可控和问题难复现。
研发助手的能力绑定应该比内容生成更严格。
它可以允许更高上下文和更强模型,但应该限制工具范围、记录仓库维度、降低自动重试次数,并对写操作或命令执行保留审批边界。
十八、Chatbox 与 Cherry Studio:个人客户端也需要团队配置纪律
Chatbox 和 Cherry Studio 这类客户端适合个人或小团队快速接入模型服务。
它们通常支持自定义 Provider、API Host、API Key 和模型名称。
这类客户端的问题不在于功能不足,而在于配置容易分散。
如果团队成员各自填写不同 Base URL、模型名和 API Key,后续就无法统一排查。
个人客户端接入团队 AI 能力时,可以采用“只下发绑定配置,不下发自由选择”的方式。
例如,团队可以给成员提供如下配置说明。
{
"provider_name": "team-openai-compatible",
"base_url": "https://api.vectorengine.cn/v1",
"models": [
{
"name": "gpt-compatible-main",
"usage": "通用问答、技术草稿、轻量分析"
},
{
"name": "reasoning-compatible-main",
"usage": "复杂推理、代码分析、长上下文任务"
}
],
"rules": {
"do_not_store_sensitive_data": true,
"do_not_share_api_key": true,
"report_error_with_binding_name": true
}
}
这不是为了限制个人使用。
而是为了让团队知道哪些客户端正在使用哪些能力。
如果某个模型名变更,只需要更新团队配置说明和绑定层,而不是让每个成员自行猜测。
如果某个 API Key 需要轮换,也可以按客户端类型逐步迁移。
十九、企业 AI 接入:能力绑定层应成为接口治理的最小单元
企业 AI 接入通常会从一个很小的场景开始。
例如,内部文档问答。
例如,客服回复草稿。
例如,运营内容生成。
例如,代码解释助手。
早期团队往往只关心是否能跑通。
但只要应用进入多人、多团队、多客户端和多模型阶段,就必须定义治理单元。
能力绑定层可以成为这个最小单元。
每个绑定对应一类可运行任务,而不是一个抽象模型。
企业治理可以围绕绑定设置审批、预算、日志、权限、测试和复查。
这比围绕单个 API Key 治理更清晰。
API Key 只是凭证。
模型名只是路由目标。
绑定才代表业务含义。
一个企业可以规定,所有生产调用必须包含 binding_name。
没有绑定名称的请求只能在沙箱环境运行。
绑定上线前必须通过最小 curl 测试、健康检查、错误分类、成本记录和客户端配置验收。
绑定变更必须记录模型、工具、检索、缓存、安全和预算的变化。
这套机制不复杂,但能显著降低后续排错成本。
二十、安全排错:能力越动态,边界越要前置
Agent 能力动态化之后,安全问题会更复杂。
过去,安全边界主要围绕输入内容和输出内容。
现在,安全边界还要覆盖工具调用、资源发现、检索片段、文件访问、外部 API、缓存复用、模型路由和客户端配置。
能力绑定层应该在调用前完成安全判断。
如果任务包含个人信息,应先脱敏再发送。
如果任务包含内部文件路径,应判断模型和工具是否允许处理。
如果任务包含财务、医疗、法律或合规判断,应设置人工复核标记。
如果任务使用向量检索,应记录检索索引、文档权限和片段数量。
如果任务会调用工具,应明确工具是否只读、是否有副作用、是否需要审批。
下面是一个安全策略片段。
safety_profiles:
public_content:
pii: "mask-before-send"
retrieval_scope: "public-and-approved"
tools:
allow_side_effects: false
human_review:
required_on:
- legal_claim
- financial_claim
- medical_claim
internal_engineering:
pii: "deny"
retrieval_scope: "engineering-internal"
tools:
allow_side_effects: false
allowed:
- repo_search
- read_file
human_review:
required_on:
- write_operation
- command_execution
enterprise_workflow:
pii: "mask-before-send"
retrieval_scope: "role-based"
tools:
allow_side_effects: true
approval_required: true
human_review:
required_on:
- external_api_write
- customer_visible_output
这类策略不需要一次性覆盖全部企业安全制度。
它至少要让调用系统知道,某个绑定是否允许外部工具、是否允许敏感数据、是否允许副作用操作。
二十一、常见故障与排查路径
能力绑定层落地后,排错路径会比传统“看报错猜原因”更清晰。
如果 Dify 调不通,先检查绑定中的 Base URL 是否适合客户端。
有些客户端希望填写到 /v1,有些脚本会直接调用完整 endpoint。
如果 Cursor 响应异常,先检查研发绑定是否允许当前模型、上下文长度和流式返回。
不要直接切换到另一个模型名绕过问题。
如果 Chatbox 或 Cherry Studio 返回 404,先检查模型名和路径拼接。
很多 404 并不是模型不存在,而是客户端把 /v1 或 /chat/completions 拼接了两次。
如果后端脚本偶发超时,先检查上下文长度、检索片段数量、流式消费方式和超时设置。
不要直接把 timeout 调到极大。
如果成本突然上升,先按绑定名称聚合,再看客户端、模型和重试次数。
很多成本异常来自自动重试、缓存失效、检索片段过多或某个客户端绕过了绑定规则。
如果输出格式不稳定,先检查模型是否支持当前结构化约束,再检查提示词和响应解析。
不要只在后处理阶段补丁式修正。
如果工具调用失败,先检查工具 schema、参数类型、权限范围和模型是否支持工具调用。
不要把工具失败误判为模型质量问题。
二十二、个人开发者如何使用能力绑定层
个人开发者不需要一开始就搭建复杂网关。
但也应该避免把所有配置写死在脚本中。
最实用的做法,是维护一个本地 ai-bindings.json。
里面保存不同任务的 Base URL、模型名、温度、超时、是否启用缓存和成本备注。
脚本每次调用时读取绑定名称,而不是直接读取模型名。
这样做有三个好处。
第一,模型迁移时只改配置。
第二,不同任务可以使用不同参数。
第三,排错时能知道是哪类任务失败。
个人开发者尤其要注意 API Key 管理。
不要把密钥写入代码仓库。
不要在多个工具中混用同一把长期密钥。
不要把测试 Key 和生产 Key 混在一起。
如果同时使用 Dify、Chatbox、Cherry Studio 和自建脚本,至少要记录每个客户端使用的绑定名称和模型名。
二十三、内容团队如何使用能力绑定层
内容团队的核心问题通常不是工具调用,而是质量一致性、事实新鲜度、成本和可复制流程。
内容团队可以把任务分成选题分析、资料整理、初稿生成、事实核查、标题改写和发布前检查。
不同阶段绑定不同能力。
选题分析可以绑定更强的检索和来源整理能力。
初稿生成可以绑定稳定的长文本模型和固定提示词。
事实核查可以绑定更严格的引用和复核规则。
标题改写可以绑定较低上下文和较低成本配置。
发布前检查可以绑定安全和合规规则。
内容团队不应让所有成员在个人客户端里自由选择模型。
这会导致输出风格、成本和事实标准不一致。
更好的方式是由团队维护任务绑定,然后让 Dify 工作流、Chatbox 客户端和脚本使用同一组绑定。
这样可以保留工具灵活性,同时保持流程一致性。
二十四、企业团队如何使用能力绑定层
企业团队需要把能力绑定层接入现有研发、运维和安全体系。
首先,绑定对象应该进入配置管理。
它不应只存在于某个产品经理的文档中。
其次,绑定变更应该有评审记录。
模型变更、Base URL 变更、工具权限变更、检索范围变更和预算变更都应该可追踪。
再次,绑定应该有自动化验收。
每个绑定至少要通过最小请求、健康检查、错误分类、成本记录和客户端接入测试。
最后,绑定应该进入监控和告警。
生产系统不应该只监控“AI 服务是否可用”。
它应该监控“某个业务绑定是否可用”。
企业团队可以从十个绑定以内开始。
例如,customer_support_draft、internal_knowledge_qa、engineering_code_agent、marketing_content_draft、legal_review_assist。
每个绑定只覆盖一个明确任务。
随着组织成熟,再逐步引入更细的权限、预算、审计和自动化测试。
二十五、能力绑定层的落地路线
能力绑定层不适合一次性大改。
更现实的路线是分四步。
第一步,清点现有客户端。
列出 Dify、Cursor、Chatbox、Cherry Studio、后端服务、脚本和自动化任务分别使用了哪些 Base URL、模型名、API Key 和参数。
第二步,抽象任务绑定。
不要从模型开始抽象。
要从业务任务开始抽象。
先定义哪些任务存在,再为任务绑定模型、endpoint、工具、检索和成本规则。
第三步,建立最小网关或配置服务。
小团队可以用 JSON 或 YAML 文件。
中型团队可以用内部配置服务。
大型团队可以把绑定纳入服务发现、权限系统和审计系统。
第四步,逐步收敛客户端配置。
不要马上禁止所有个人配置。
可以先要求生产任务必须使用绑定名称。
再要求团队客户端使用统一 Base URL。
最后再引入密钥轮换、预算告警和自动化验收。
二十六、能力绑定层不是为了增加复杂度
很多团队担心治理层会降低效率。
这个担心有一定道理。
如果能力绑定层只是堆规则、堆审批、堆表格,它确实会拖慢业务。
但本文讨论的能力绑定层不是管理制度的外衣。
它是为了减少重复配置、减少排错时间、减少模型迁移成本、减少安全边界不清和成本不可见。
开发者不应该每次都重新判断用哪个 Base URL。
内容团队不应该每个工作流都手动复制模型配置。
企业运维不应该等事故发生后才知道哪个客户端使用了旧模型名。
能力绑定层的价值,在于把这些反复发生的问题提前固化为调用契约。
它让调用变得更清楚,而不是更神秘。
二十七、结语:AI 正从聊天工具进入工程化、工作流化、系统化阶段
今天的 AI API 生态已经很难用“模型排行榜”解释。
OpenAI 的用量和成本控制信号,说明企业正在把 AI 调用纳入运营和财务治理。
Google 的 Agentic Resource Discovery 和 A2A 协作方向,说明 Agent 能力正在从静态工具表进入动态资源发现阶段。
Anthropic、DeepSeek、Gemini 等模型生态的版本和兼容接口变化,说明模型生命周期管理已经成为日常工程问题。
Dify、Cursor、Chatbox、Cherry Studio 等工具降低了接入门槛,但也让配置入口变多。
在这种环境下,真正重要的不是再增加一个零散配置,而是建立一层能够绑定模型、工具、资源、权限、成本、安全和客户端约束的运行时契约。
能力绑定层的意义就在这里。
它让 AI API 调用从“能调通”走向“能治理”。
它让 Agent 从“能执行”走向“可约束执行”。
它让 OpenAI 兼容接口从“统一入口”走向“统一能力边界”。
它让个人开发者、内容团队和企业团队都能在同一套工程语言下讨论模型迁移、成本控制、安全排错和工作流稳定性。
AI 正从聊天工具进入工程化、工作流化、系统化阶段。
下一阶段的竞争,不只在于谁能接入更多模型。
更在于谁能把模型、Agent、工具、数据和组织规则绑定成可运行、可复查、可迁移的系统能力。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 1
1 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)