
Codex 被爆藏着一个写爆你硬盘的 bug
OpenAI 旗下 AI 编程工具 Codex 出了一个 bug,让不少用户的固态硬盘(SSD)在后台疯狂掉寿命。
最离谱的一个案例:一个用户才跑了 21 天,硬盘就被写进去了 37 TB 的数据。粗略算下来,一年相当于 640 TB。
而这一切,就发生在你跟 AI 聊天、让它帮你写代码的时候。
你没听错。不是你在主动拷贝文件,是程序在后台自己写。
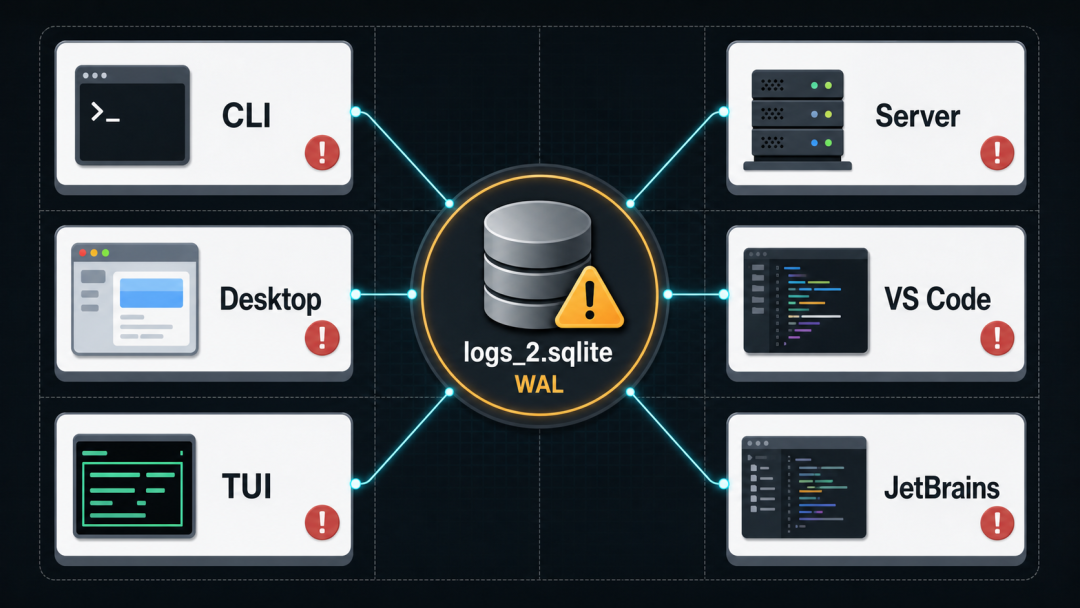
更关键的是,这个问题不是某一个版本或某一个平台的问题。
CLI、桌面版(Desktop)、终端版(TUI)、后台服务(app-server),甚至 VS Code 和 JetBrains 的扩展,全都撞上了同一面墙。

你以为关小了日志,实际上只是关小了你能看见的日志
Codex 是一个程序员用的工具,运行在开发者电脑上。它有一个日志系统,简单理解就是程序用来"记日记"的东西——每次运行发生了什么、出了什么错,都会写下来,方便出问题的时候排查。
很多程序允许你用一种叫 RUST_LOG 的设置来控制日志的详细程度。你可以把它理解成一个门卫——它决定哪些日记该亮出来给你看。
所以开发者的直觉通常是:我把门卫调到"只看警告",那那些特别琐碎的"日记"就不该再出现了。
这个直觉对"屏幕上滚的字"大体成立。 但它 不一定 对"磁盘里持久化写的字"成立。
OpenAI 的官方文档里写得很清楚:Codex 会遵守这个日志级别开关,默认还会把诊断信息记录到本地的一个存储里。
这句话的问题在于,它很容易让人产生一种朴素的误解: 前台怎么过滤,后台就怎么存。
可公开源码显示,事情不是这么简单的。
Codex 本地用来存日志的数据库,默认采集级别是非常非常细的。它确实对几个特别吵的部分做了额外过滤,但默认的地基仍然是"什么都记"。
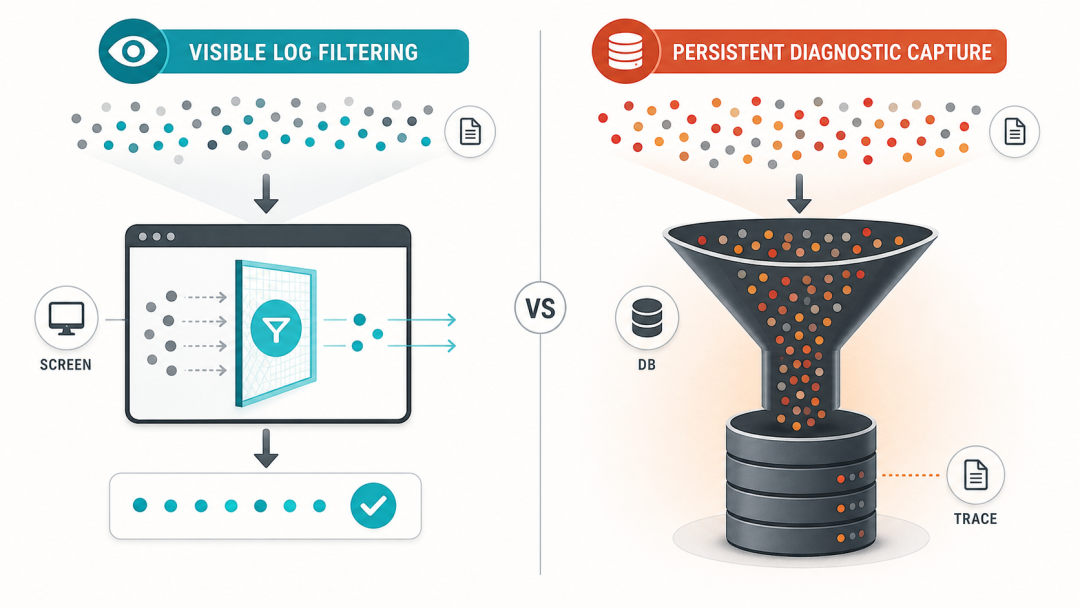
更关键的是,Codex 的源码注释里明确写着一件事: 为了用户上传反馈报告时能拿到完整的运行痕迹,不管用户设置的日志级别是什么,都要尽量把完整的痕迹捕获下来。
你以为自己关小了 Codex 的日志? 但实际上,你只是关小了你能看见的那一部分。
真正把盘写疼的,不是数据库大小,而是数据库的运动轨迹
如果你只看最终文件大小,很容易低估风险。
因为硬盘不在乎"最后数据库有多大"。对硬盘寿命真正影响的是:你一共读写了多少次。
这就是为什么 2026 年 4 月一个用户报告的问题很关键。 这位用户确认,他启动 Codex 时日志级别明确设成了"只看警告"。
但在 AI 回复他代码的时候,一个名为 logs_2.sqlite-wal 的文件仍然在持续变大,速度大约每秒 5 MB,快的時候能达到每秒 16 MB。
什么概念呢?就是你拷贝一张高清电影 iso 的时候大概就是这个速度。
一个 AI 编程助手的日志,在后台跑得跟拷贝大文件一样。
更可怕的是数据库内部的观测结果。
同一个报告里,用户发现:一次很短的 AI 响应后,数据库里记录的"总写入次数"暴涨了约 5000 次,但"当前保留的记录条数"基本没变。
这里涉及到一个叫 WAL 的机制。你可以先把它理解成数据库的"草稿账本"。
数据库不会每来一条新日志,就立刻把正式账本改得整整齐齐。它通常会先把变更写进这本草稿账本。
如果写入频率很高,草稿账本就疯狂翻页。
于是出现了一个很多人第一次遇到时都会困惑的现象:
主数据库文件不算特别大。
但那个带 -wal 后缀的草稿账本文件却巨大无比。

事件被连续放大
如果只有一个用户抱怨,很多人会把它当成个例。
但这次不是。
从 2026 年 4 月到 6 月,OpenAI 的官方仓库里至少出现了五类相互呼应的问题报告。
它们运行在不同平台上:macOS、Windows、Linux、WSL2。
它们运行在不同产品形态上:CLI 命令行、Desktop 桌面版、TUI 终端版、app-server 后台服务、VS Code 和 JetBrains 扩展。
但都撞上了同一面墙。
第一类:CLI 用户,每天凭空多出 0.75 GB
一位用户持续让 Codex 在后台跑服务,大约 10 天后,日志数据库长到了将近 10 GB,平均每天约 0.75 GB。
什么概念呢? 相当于每天往盘里塞一部半高清电影大小的"无用数据"。而且这些数据,用户并没有主动要求存下来。
更有价值的是,这个报告把"谁最吵"拆了出来。
占用最大的三类日志分别是:
-
• AI 回复内容时的逐条记录
-
• 系统内部监控数据的镜像副本
-
• 另一类系统追踪记录
说明真正把盘写热的,不是随机噪声。
而是几类频率极高、信息密度却不成比例、还被持久化进本地数据库的日志。
第二类:21 天写了 37 TB,一年大概有 640 TB
这个报告把话说得更直接。
报告者说,他的机器在大约 21 天里写了 37 TB。如果粗略外推,大约是 640 TB/年。
这里要解释一个概念。硬盘厂商常说的 TBW,你可以理解成"这块盘官方承诺大致能扛多少总写入量"。不同盘不一样。但一个 1 TB 消费级硬盘的保修写入预算通常在几百 TB 这个量级。
一年写六百多 TB,当然会让人发毛。更狠的是,这个报告不是只报了一个吓人的数字。
它还抓到了结构性证据:
-
• 当前保留行数只有几十万
-
• 但数据库自增 ID 已经冲到了 55 亿以上
55 亿。什么概念呢?就是数据库给每一行发的流水号,已经数到了 55 亿。但库里真正留下的,只有零头。
说明数据库最终留下的不多。
但历史上曾经写进去的东西,已经多得离谱。
真正伤硬盘的,从来不是你最后留了多少,而是你中途写了又删了多少。
第三类:主库才 100 MB,草稿账本却单独膨胀到几十 GB
这次用户看到的不是主库暴涨。
而是那个带 -wal 后缀的草稿账本文件自己长到了几十 GB。
报告里,两套运行配置的草稿账本合计一度大约 65 GB。而主库本身却大约只有 100 MB 级别。
这正好解释了很多用户的迷惑:
“我看数据库文件没多大,为什么磁盘已经快满了?”
因为问题很可能不在主库。
而在草稿账本。
当前公开源码里,日志数据库默认启用了草稿账本模式。
同时,启动维护会做一件事:尝试把草稿账本的内容搬回正式账本。但这个操作的参数叫 PASSIVE,含义可以粗暴理解成:我尽量搬,但我不等,也不强推。
这种策略的优点是,不容易把前台程序卡死。
缺点也很明显。
如果同时运行的程序很多,或者对话很长,草稿账本不一定能及时瘦身。
第四类:日志大到软件直接打不开了
这个报告记录的是最容易让普通用户感到疼的一种后果:
不是"盘寿命"。
而是"Codex Desktop 直接打不开了"。
报告里:
-
• 日志数据库大约 4.5 GB
-
• 草稿账本大约 1.08 GB
用户只把这两个文件挪走,Codex Desktop 就能重新启动。
也就是说,这个问题已经不是"后台悄悄写很多"那么简单。
当日志文件足够大时,它会反过来拖慢程序启动、清理、查询,最后变成前台故障。
一个 bug 真正危险,不是它能复现,而是它能跨平台、跨产品形态复现。
第五类:连 CLI 自己都扛不住了
除了上面这些,还有一个更隐蔽的发现。
Codex 还有一个叫 goals_1.sqlite 的数据库,用来记录 AI 的"任务目标"状态。
一位 Linux 用户在 2026 年 6 月的报告里发现:这个数据库文件本身只有 4 到 25 KB,但进程在 771 秒内写入了 8.7 GB 的数据,峰值达到每秒 11 MB。
更夸张的是,如果一台机器上同时跑 8 个 Codex 会话,就会产生 10 到 25 MB/s 的纯额外写入。
用户最后的解决办法是直接在配置里关闭了 goals 功能——因为关掉之后,写盘立刻停了。
这说明问题不只是 logs_2.sqlite 这一个地方。
OpenAI 修了什么,为什么只能叫"止血"
这里必须把日期说清楚。
2026 年 6 月 22 日,OpenAI 发布了 Codex 的最新版本:0.142.0。
这个版本的更新说明里有一句非常关键的话:
降低日志写入量,方法是停止记录每一条 AI 回复内容,并过滤重复的系统监控记录。
同一天,前面那个报了 640 TB/年的用户也更新了说明:当天合并的两项修复,大约能减少他自己环境里 85% 的日志量。
这两项修复是:
-
1. 停止记录每一次 AI 回复的详细内容
-
2. 过滤掉最吵的系统日志
这两刀为什么有效?
因为它们正砍在前面几个报告里最吵的地方。
第一刀,砍掉逐条回复内容的记录。
这能直接减少流式场景里那种"每来一段就记一次"的高频写入。
第二刀,砍掉重复的系统日志。
这能减少底层事件重复落盘。
所以一个负责任的判断应该是:
-
• 旧版本的问题是实锤
-
• 这个版本的修复方向也是对症
但如果你问:那是不是从此万事大吉?
答案还不能这么乐观。
因为当前公开源码里,日志采集的默认级别仍然是"什么都记"。只是在此基础上加了几个过滤器。
这意味着架构上的基本倾向还在:
默认尽量多采,再把最吵的几类剔出去。
这当然比修之前安全得多。
但它还不是"默认少采,按需多采"的那种保守设计。
修掉最吵的麦克风,不等于拆掉整套扩音器。
文档写着"有上限",为什么用户还是能看到几十 GB
这是整件事里最容易误导人的一句话。
OpenAI 的官方文档说的是"本地存储有上限"(bounded local stores)。
很多读者会自动理解成:
“那总量应该有硬上限吧。”
但源码里的"有上限",更准确地说,是对最终留下的内容做预算。
比如:
-
• 每次对话一个分区预算
-
• 每个分区大约 10 MB
-
• 或者最多 1000 条记录
-
• 启动时再删掉 10 天前的旧日志
这能控制什么?
它能控制最后有多少内容留在库里。
但它不能自动控制:
-
• 历史上总共写入过多少
-
• 草稿账本曾经膨胀到多大
-
• 多程序相加总共占多少
这就是为什么会出现一种看上去很反直觉的现象:
最终行数差不多,但写入编号疯狂上涨。
也是为什么会出现另一种更反直觉的现象:
主库不大,草稿账本却大到离谱。
很多系统的"有上限",限制的是库存,不是流水。
今天普通用户最该做什么
如果你现在正在用 Codex——不管是 CLI、Desktop、TUI、app-server,还是 VS Code / JetBrains 扩展——我觉得最重要的不是恐慌。
而是把层次分清楚。
第一,尽快升级到 0.142.0 或更高版本。
因为截至 2026 年 6 月 23 日,这是官方已经明确加入日志写入修复的版本。
第二,不要再迷信单独一个日志级别设置。
至少从旧版本的公开报告看,它并不是可靠的"止血总闸"。
第三,观察三个文件,而不是只看一个:
-
•
logs_2.sqlite(主日志库) -
•
logs_2.sqlite-wal(草稿账本) -
•
logs_2.sqlite-shm(同步辅助文件)
如果你只看主库,很容易低估问题。
第四,备份电脑时,谨慎处理那几个带 -wal 和 -shm 后缀的文件。
报告已经说明,真正拖垮空间和同步成本的,往往是草稿账本,不是主库。
第五,别把会话数据和诊断日志混为一谈。
Codex 有两类数据库文件:
-
•
logs_2.sqlite*是诊断/反馈日志路径 -
•
state_5.sqlite是主会话状态库
这件事很重要。
因为真要做紧急清理时,你得知道谁能动,谁不能乱动。
第六,如果要清理日志文件,先关掉正在运行的 Codex。
有人踩过坑:
-
• 程序还在跑的时候删除草稿账本,空间不一定立刻回来
-
• 对着仍被打开的草稿账本动手,甚至可能直接把正在跑的 Codex 干崩
别把诊断日志当成主数据,也别把主数据当成诊断日志。
这件事真正值得记住的,不只是 Codex
很多人会把 AI 工具理解成"模型 + 界面"。
但真正决定体验下限的,常常不是模型。
而是那些看不见的本地运行机制。
日志怎么记。
数据怎么存。
草稿账本怎么清理。
程序启动怎么检查健康。
这些看起来不像"AI",却会直接决定一款 AI 工具是不是能长期待在你的机器上。
这次 Codex 暴露出来的教训,远比"日志写太多了"更普遍。
它真正提醒我们的是:
一个看起来无害的日志系统,只要采集太细、清理不够勤快,就足以把本地电脑变成长期写盘装置。
模型在生成代码。
日志系统也在生成代价。
延伸阅读 / 参考来源:
-
1. OpenAI Codex 安装文档
https://github.com/openai/codex/blob/main/docs/install.md -
2. OpenAI Codex 0.142.0 版本更新说明 (2026-06-22)
https://github.com/openai/codex/releases/tag/rust-v0.142.0 -
3. OpenAI Codex 用户报告 [#17320](javascript:😉 — 流式响应期间 SQLite 草稿账本疯狂写入
https://github.com/openai/codex/issues/17320 -
4. OpenAI Codex 用户报告 [#26374](javascript:😉 — 长期运行的日志数据库无限增长
https://github.com/openai/codex/issues/26374 -
5. OpenAI Codex 用户报告 [#27741](javascript:😉 — 日志数据库过大导致桌面版无法启动
https://github.com/openai/codex/issues/27741 -
6. OpenAI Codex 用户报告 [#28224](javascript:😉 — 日志写入量估算高达 640 TB/年
https://github.com/openai/codex/issues/28224 -
7. OpenAI Codex 用户报告 [#28997](javascript:😉 — 草稿账本文件膨胀到数十 GB
https://github.com/openai/codex/issues/28997 -
8. OpenAI Codex 当前公开源码:
-
•
codex-rs/core/src/otel_init.rs -
•
codex-rs/state/src/lib.rs -
•
codex-rs/state/src/runtime.rs -
•
codex-rs/state/src/log_db.rs -
•
codex-rs/state/src/runtime/logs.rs -
•
codex-rs/feedback/src/lib.rs

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)