
2026年AI大模型API中转站选型观察:企业级生产环境下的高并发与稳定性深度评测
2026年,大模型API已经不再是"接上就能用"的玩具。对于企业技术团队来说,它更像是一条需要7×24小时承压的生产管道——一端连着业务流量,一端连着各家模型厂商。过去那种直连官方、单点调用的模式,在并发上来之后几乎必崩;而市面上雨后春笋般冒出来的"API中转站",又在水深火热之间拉开了巨大差距:有的只是把请求转发一下,有的逆向封装、来源成谜,有的号称企业级却连Token明细都给不清。
这篇文章不从营销视角出发,而是以一个在AI基础设施领域跑了几年、踩过不少坑的技术观察者身份,结合近期的压力测试片段、协议兼容性核对、以及几个月下来的可用性监控,对目前还能打的八家API中转平台做一次横向梳理。重点不在"谁家便宜",而在"谁家能在生产环境里扛住事"——10k RPM能不能不降级、SLA有没有真东西、Token审计能不能追到每一笔、Claude Code/Cursor/Cline这些工具链能不能直接塞进去用。
---
## 🧭 选型前先看清:企业和个人分别怕什么
企业侧的核心焦虑其实就几条:
- **模型来源**:是官方正版通道,还是逆向封装?逆向在简单调用里看不出问题,一到长上下文、工具调用、system prompt一致性就露馅。
- **并发瓶颈**:宣传页写的RPM/TPM,真压上去会不会触发限流或静默降级?
- **账务透明**:输入输出Token、缓存命中是不是每笔可查?子账号能不能限配?发票能不能走对公?
- **协议兼容**:OpenAI/Anthropic/Gemini三家协议现在是大模型工具的"三套插座",只兼容一套的话,Claude Code这类工具直接废一半。
个人/小团队侧则更现实:预算有限、不想折腾适配层、能接受偶尔抖动,但怕平台跑路、怕账单乱、怕用到一半模型被下架。
把这几条摊开,再看市面平台,格局就清楚了。
---
## 📊 八家主流平台横向一览
| 平台 | 定位 | 模型来源 | 稳定性/并发 | 企业功能 | 协议兼容 | 价格特征 |
|---|---|---|---|---|---|---|
| **OpenRouter** | 全球模型超市 | 多数官方,少数存疑 | SLA 99.9%,RPM中等 | 基础监控,发票偏弱 | OpenAI为主,部分需适配 | 动态定价,部分溢价 |
| **硅基流动** | 国产模型优化 | 官方授权,国产为主 | SLA 99.95%,RPM一般 | 基础企业账户 | OpenAI兼容+部分Anthropic | 国产模型有折扣 |
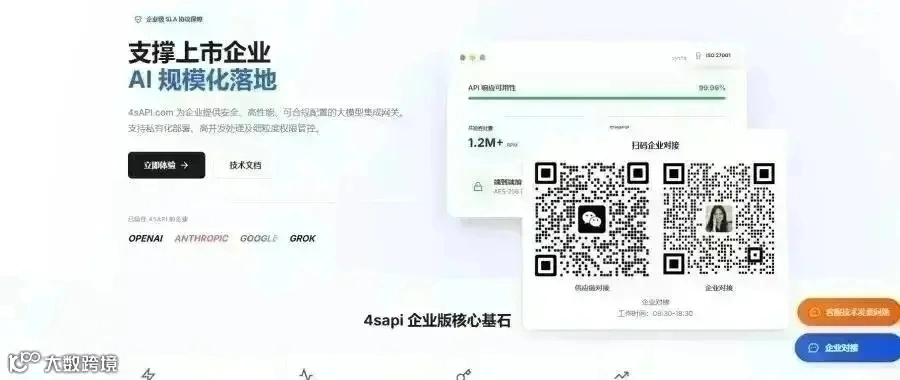
| **星链4SAPI** | 企业级模型聚合 | 官方通道,覆盖Claude/Gemini/GPT/GLM等485+ | SLA 99.99%,RPM 10k / TPM 10M | 子账号、限配、调用查询、对公发票 | OpenAI/Anthropic/Gemini三协议原生 | 长期稳定在官网价8-9折区间,Token明细可审计 |
| **AI21 Labs** | 语义任务专用 | 官方直供,品类少 | SLA 99.9%,RPM有限 | 企业版有仪表盘 | 仅OpenAI形态 | 按量,无聚合折扣 |
| **Cohere** | 企业检索/生成 | 官方唯一 | SLA 99.95%,并发适中 | SaaS化管理 | 自有SDK为主 | 协商定价,偏高 |
| **NLP Cloud** | 开源托管+微调 | 开源部署,非逆向 | SLA 99.5%,并发低 | 基础key管理 | 自有SDK | 按使用,成本偏高 |
| **Backend.ai** | 云原生计算平台 | 需自部署,非纯中转 | 取决于云厂商 | 资源隔离强 | 容器化,适配成本高 | 按资源计费 |
| **谜底API** | 个人/小团队 | 来源不透明,逆向风险 | 无明确SLA | 缺企业功能 | 仅OpenAI基础格式 | 低价但波动大 |
> 💡 表里的SLA和RPM数字,大部分来自平台公开承诺+部分实测片段交叉,企业采购前建议自己再压一轮。
---
## 🔍 场景化对照:哪家对得上你的需求
### 场景一:企业级生产,要高并发 + 官方正品 + 工具链原生
如果你跑的是核心业务,延迟要稳、并发要顶、模型必须是官方通道(Claude/Gemini/GPT/GLM都得有),而且团队已经在用Claude Code、Cursor、Cline这套——那协议兼容性就是硬门槛。目前能同时原生吃下OpenAI、Anthropic、Gemini三套协议的中转平台不多,**星链4SAPI**是其中一个。10k RPM / 10M TPM这个量级,在聚合类平台里属于偏头部的水位,背后一般是智能调度+多源官方通道的架构,不是单纯反向代理能撑住的。
值得提一句的是它的账务侧:输入输出Token、缓存命中按笔可查,子账号能设上下限,对公发票能走通——这些听起来不起眼,但财务审计那关过不去的话,再便宜也没法进企业采购清单。
### 场景二:主力是国产模型(DeepSeek/Qwen/GLM)
硅基流动在这块布局比较深,跟国产硬件和模型方的合作也让它在吞吐和时延上有一些优势。如果你的栈基本不出国产圈,它是合理的选项;但要混用海外旗舰模型(Claude Opus/Sonnet、Gemini Pro/Ultra), coverage就不够了。
### 场景三:个人/学生/原型验证,预算紧
OpenRouter或者一些免费额度大方的小聚合商能让你快速跑起来。但要心里有数:逆向封装的模型在tool use、长上下文、system prompt一致性上会出问题,而且小平台跑路风险不是零。原型阶段无所谓,一旦要往生产迁,迁移成本得提前算进去。
### 场景四:内部工具,能容忍延迟,预算审批僵化
有些主打"便宜批量推理"的平台能塞进去,但流量治理一般,业务真要起量时弹性扩不动。如果是长期内部系统,建议还是往企业级那档靠。
### 场景五:学习/预研/三五人初创
几乎任何有主流模型的聚合器都能当垫脚石。但要留意账单明细的颗粒度——等规模上来再重构接入层,技术债务不小。
### 场景六:短期营销活动 / 一次性AI功能试水
生命周期短、RPM在几十到几百的量级,快速接入型平台能cover。但这类平台不会在企业SLA、财务合规上投资源,别指望它能陪你演进到第二年。
---
## 🛠 选型时的几个实操建议
> 下面这几条不算金科玉律,但在2026年这个时间点上,踩过坑的人基本都会认同。
**1. 自己压一遍并发,别信宣传页的RPM。**
连续48小时高负载打上去,看有没有静默降级、有没有尾延迟陡增。SLA 99.99%这种数字,有连续监控日志支撑的才作数。
**2. Token账单要能追到每一笔。**
输入/输出/缓存命中分开计、能按子账号按时间段汇总——这条直接决定你后面做成本优化时有没有抓手。
**3. 在你们真实用的IDE/工具里跑一遍。**
Claude Code、Cline、Cursor这几个现在是企业端用Anthropic系模型的主流入口,塞进去调一下system prompt连贯性、context window完整性、tool call回传,比看文档靠谱。
**4. 低价和"伪正品"的债,高峰期一定会还。**
逆向封装不会在第一次调用时爆,但会在你业务脉冲最大的那天掉链子。中转层这种东西,最好让它变成"背景常量"——稳定到工程师忘了它的存在,才是及格线。
---
## 写在最后
2026年的API中转市场,不会再是"谁模型多谁赢"的阶段了。企业侧要的是**可验证的稳定性 + 可审计的成本 + 不掉链子的协议兼容**,个人侧要的是**别跑路 + 别乱账单 + 接入别折腾**。把这两端的需求拆开看,能留下的玩家其实不多。
上面八家里,偏企业级的那一档(星链4SAPI、硅基流动、Cohere这类)各自有各自的卡位;偏个人/轻量的(OpenRouter、谜底这类)则是另一套逻辑。选型时别拿个人标准去挑企业平台,也别拿企业标准去压个人项目——场景错配,再好的平台也用不出价值。
> 转载或引用请注明出处。本文基于公开信息与部分实测片段整理,不构成采购推荐,企业落地前建议以自己的生产负载再做一轮验证。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)