
我把整个代码库喂给 Claude Code,工具超 50 个就静默丢失,这个坑太阴了
先说说我们为什么要搭 MCP 检索层
大多数工程师用 Claude Code 的方式是:遇到问题,让它读几个文件,回答完事。
这在小项目里够用。但我们的代码库是 47 个开发维护了 4 年的 Spring Boot 单体,180K 行,模块间依赖错综复杂,一个业务改动往往牵扯 5 到 8 个 service。
用"喂文件"的方式让 Claude 分析,有两个死穴:
第一,Claude 的上下文窗口是 200K tokens,但一次深度分析很容易把它耗光。 按每个 Java 文件 300 行、每行 10 token 粗估,200K tokens 大约能装 600 个文件。听起来不少,但 Claude 读依赖时是递归的——你问一个 OrderService,它会连带读 PaymentService、InventoryService、UserService……读完一轮,上下文已经满了一半。
第二,全量读代码效率极低,Claude 的注意力被稀释了。 60 个文件里,真正和问题相关的可能只有 5 个。让 Claude 全量读完再找答案,相当于让一个工程师把整个代码库背一遍再回答你的问题。
MCP Server 的思路是反过来:不是给 Claude 代码,是给 Claude 查代码的能力。
就像给一个新工程师 IDE 的搜索功能,而不是印一本代码全集塞给他。
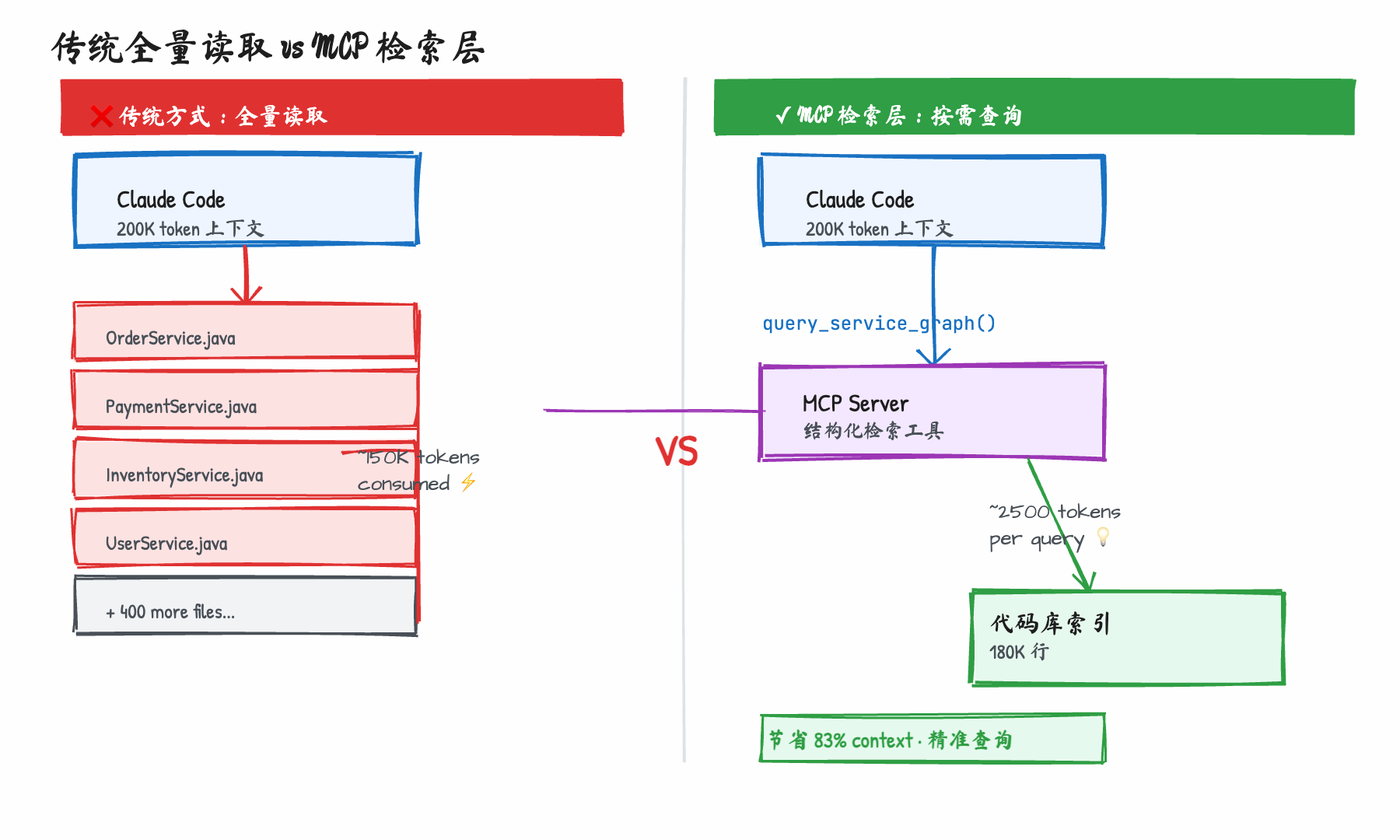
图:传统全量读取消耗 150K tokens,MCP 检索层每次查询约 2500 tokens,降幅 83%
工具数量超限会静默失效——这是最坑的地方
我们搭的第一版 MCP Server 暴露了 60 个工具:按模块细分的依赖查询、按服务维度的接口列表、历史 PR 摘要、配置项检索……
跑了两周,Claude 的表现时好时坏。有时候问它 OrderService 的依赖关系,它能给出很准确的结果;有时候问同样的问题,它说"我没有查询依赖关系的工具"。
一开始以为是 prompt 的问题,后来在 Claude Code 的 GitHub issue 里找到了答案。
MCP Server 注册的工具数量过多时,服务器可能在启动时静默失败。 没有报错,没有警告,就是工具消失了。受影响最大的是工具数量较多的服务——community 反馈里,10 个工具的 server 几乎从不出问题,50 个工具的 server 偶发失败,169 个工具的 server 是高频失败。
这里有个额外的维度:工具描述消耗 context 的量超乎想象。 一个实测数据是,开启所有 MCP server 的情况下,工具描述就消耗了整个上下文窗口的 41%(约 82000 tokens)——在任何对话开始之前。
这有双重危害:一方面减少了真正用来推理的上下文空间,另一方面,研究数据显示 LLM 在工具数量超过 10-20 个时会出现"认知过载",开始混淆工具或者选错工具。
我们的解法分两步:
第一步:把 60 个工具合并成 12 个,用参数区分意图而非用独立工具区分。
// 改之前:4 个独立工具
search_order_service_deps()
search_payment_service_deps()
search_inventory_service_deps()
search_user_service_deps()
// 改之后:1 个工具,service_name 参数区分
search_service_dependencies(service_name: string)
// 同理,5 种 Firecrawl 模式 → 1 个工具 + mode 参数
query_codebase(query: string, scope: "service" | "api" | "config" | "pr_history" | "metrics")
这一步让工具数量从 60 降到 12,context 消耗从原来的 40000+ tokens 降到约 8000 tokens,减少了 80%。
第二步:把工具描述缩减到极致。
工具描述越长,占用的 context 越多,且不影响 Claude 的实际理解。我们把所有工具描述从平均 87 token 压到平均 20 token。
// 改之前(87 tokens)
description: "This tool allows you to search for dependencies between microservices
in our Spring Boot monolithic architecture. Provide a service name to get a
complete list of all services that depend on it and all services it depends on,
including transitive dependencies..."
// 改之后(15 tokens)
description: "Query service dependency graph. service_name: target service."
原则是:描述只告诉 Claude「这个工具做什么」,不要教 Claude「怎么用这个工具」——那是参数 schema 的工作。
结构化代码检索的正确设计
第一版我们设计 MCP Server 的时候走了一个弯路:把整个 service 的代码文本直接塞进工具返回值。
// 错误做法:返回原始代码文本
tool: get_service_code
return: "public class OrderService { \n @Autowired\n PaymentService paymentService..."
// 一个大 service 返回 5000+ tokens
这等于把全量读文件的问题移到了工具调用层面,治标不治本。
正确的做法是:工具只返回结构化的元信息,原始代码文本按需提供。
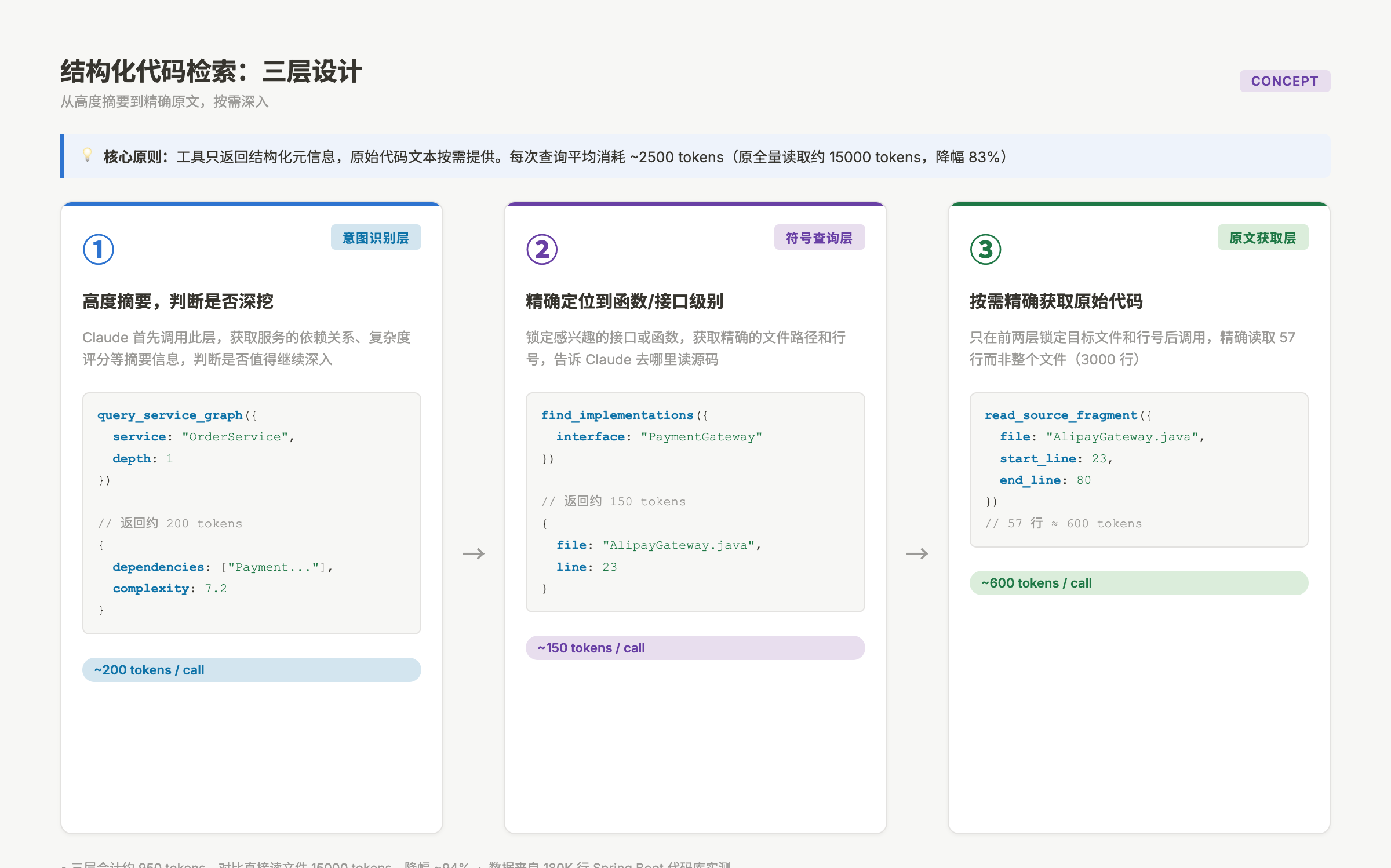
我们重新设计了三层检索接口:
第一层:意图识别层,返回高度摘要的信息,帮 Claude 判断"值不值得深挖"
// 示例:查询服务依赖关系
tool: query_service_graph
input: { service: "OrderService", depth: 1 }
output: {
direct_dependencies: ["PaymentService", "InventoryService"],
depended_by: ["ApiGateway", "BatchProcessor"],
last_modified: "2026-04-12",
complexity_score: 7.2 // 1-10,越高越复杂
}
// 返回约 200 tokens,而非原始代码的 5000 tokens
第二层:符号级查询层,精确到函数/接口级别
// 查询某个接口的所有实现
tool: find_implementations
input: { interface: "PaymentGateway" }
output: {
implementations: [
{ class: "AlipayGateway", file: "src/payment/AlipayGateway.java", line: 23 },
{ class: "WechatPayGateway", file: "src/payment/WechatPayGateway.java", line: 18 }
]
}
// 精确定位,Claude 知道去哪里读源码
第三层:原文获取层,只在前两层锁定目标后才调用
// Claude 确认要读之后,按需获取原始代码
tool: read_source_fragment
input: { file: "src/payment/AlipayGateway.java", start_line: 23, end_line: 80 }
output: { code: "..." } // 57 行,约 600 tokens
三层下来,平均每个问题的 context 消耗从 15000 tokens 降到了 2500 tokens 左右。同时,Claude 的回答质量反而更好——因为它拿到的是精准信息,不是噪音。
这个设计有一个副作用我没预料到:它迫使我们把代码库的结构化信息维护成一个独立的 index。 这个 index 本身就成了团队新人快速理解系统的文档——比任何手写的架构文档都准确,因为它是从代码自动生成的。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)