
李宏毅机器学习系列-强化学习之模仿学习
李宏毅机器学习系列-强化学习之模仿学习模仿学习模仿学习模仿学习就是根据演示来学习,很多时候我们的任务没办法定义奖励,但是我们可以收集很多的数据给机器去学习,方法一般有两种,一种叫行为复制,一种叫逆向强化学习:...
李宏毅机器学习系列-强化学习之模仿学习
模仿学习
模仿学习就是根据演示来学习,很多时候我们的任务没办法定义奖励,但是我们可以收集很多的数据给机器去学习,方法一般有两种,一种叫行为复制,一种叫逆向强化学习:
行为复制(Behavior Cloning)
简单来说是你看别人怎么做,你也怎么做,其实就是一个有监督学习。比如自动驾驶,你看到人类在什么情况做什么,你也就这么做: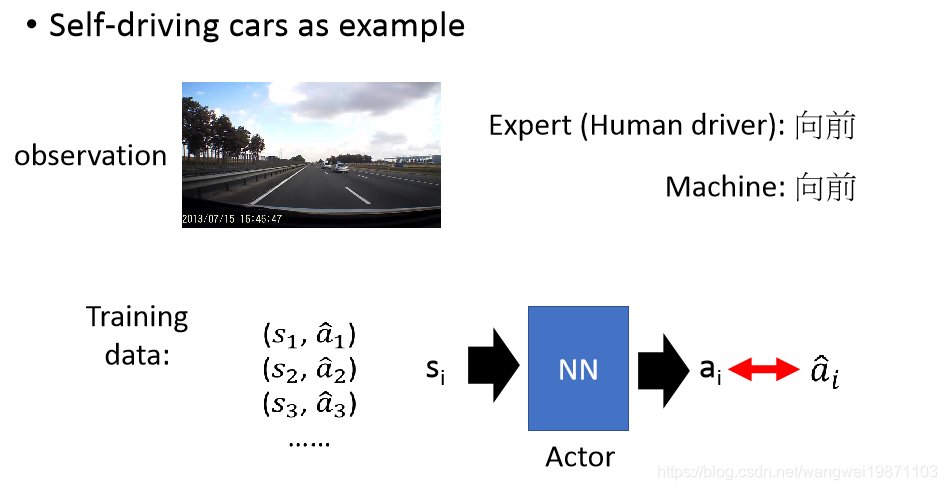
但是这样有很多问题,比如采样的情况是有限的,你会看到没见过的情况,那就可能出问题。比如自动驾驶,如果让人来看即直接弯过去了,但是如果是机器开,他可能开车开车撞墙了,因为他也不知道撞墙会怎么样,没学到过。所以我们需要收集更加多样性的数据,而不是单一的:
如果我们用数据聚合的方法来做,就是让机器去开车,然后旁边做一个人类,人类告诉机器要怎么做,当看到快要撞墙时,人类会说要右拐,但是机器不管,还是撞墙了,这样就能知道快撞墙的时候要怎么办,但是这样做每次训练会牺牲一个人: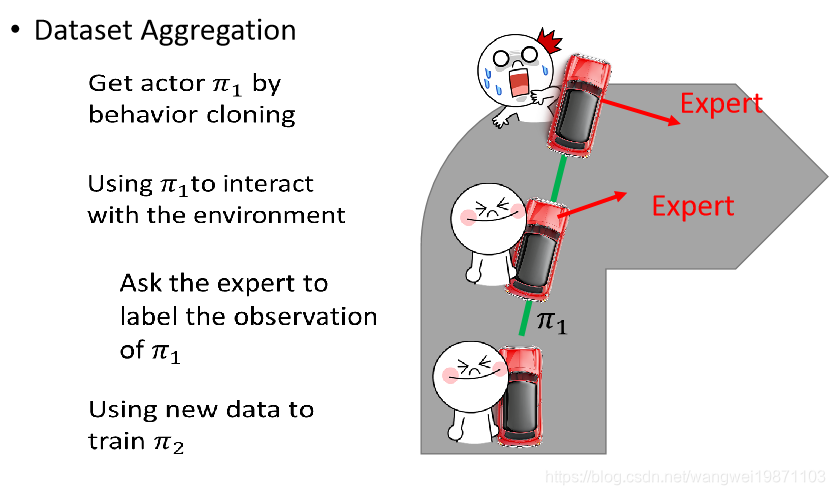
但是这个方法有可能会让机器完全学着人类,或许会连错误的方式也学进去了: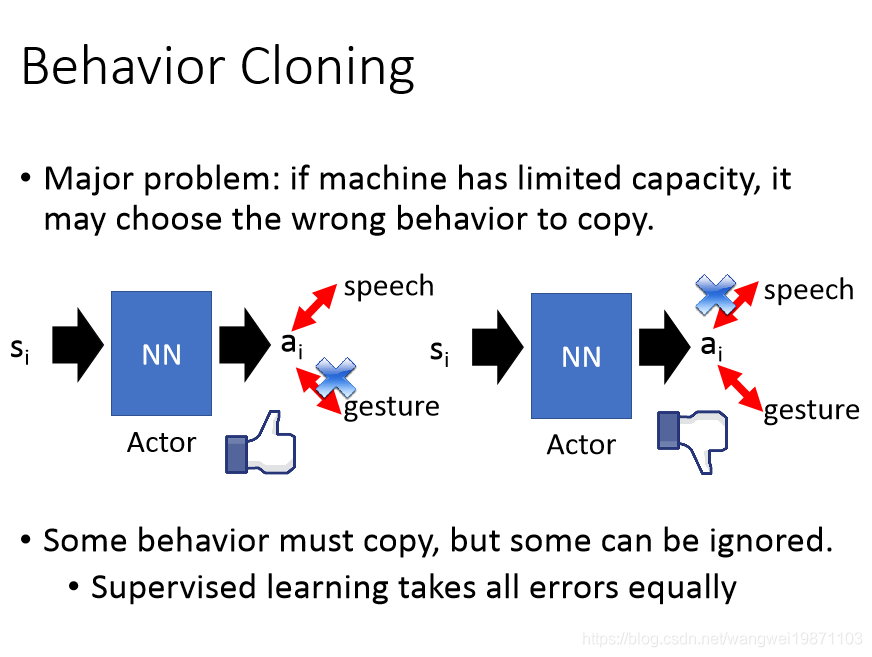
我们希望去训练一个网络跟人的行为一样,但是如果训练出来的跟实际的有一点误差的话,可能会影响到后面的状态,那样就最后的结果可能会差很多:
逆向强化学习(Inverse Reinforcement Learning (IRL))
简单来说就是把奖励函数给训练出来,然后再进行正常的学习: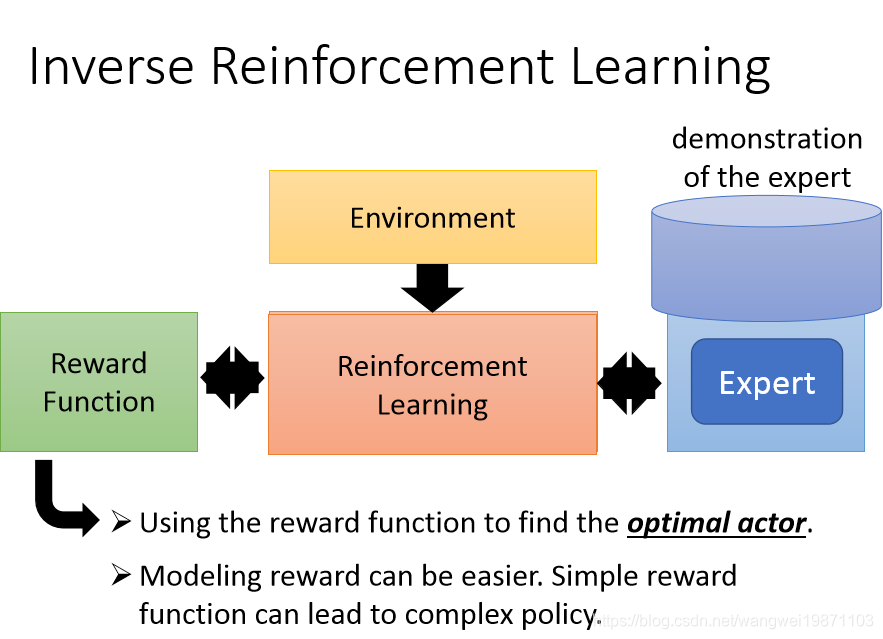
训练框架是这样的,我们训练一个奖励函数,将人类玩的数据和机器玩的数据放进去,我们希望认为的奖励大于机器的,然后你有了奖励函数,你就可以去训练机器让奖励越大越好,然后再去训练奖励函数,让人的奖励大于机器的,就这样交替训练,直到最后人类的奖励和机器的奖励一样好: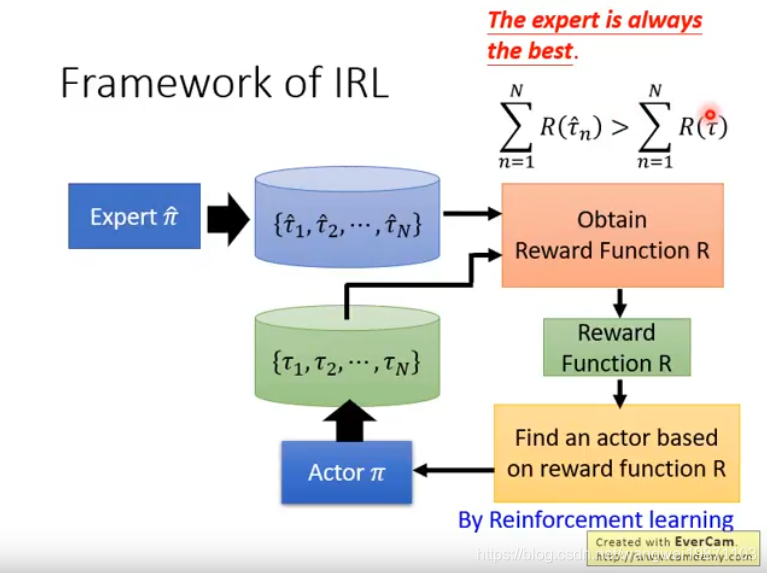
其实这个思路跟GAN一样,奖励函数就是GAN的判别器,Actor就是生成器: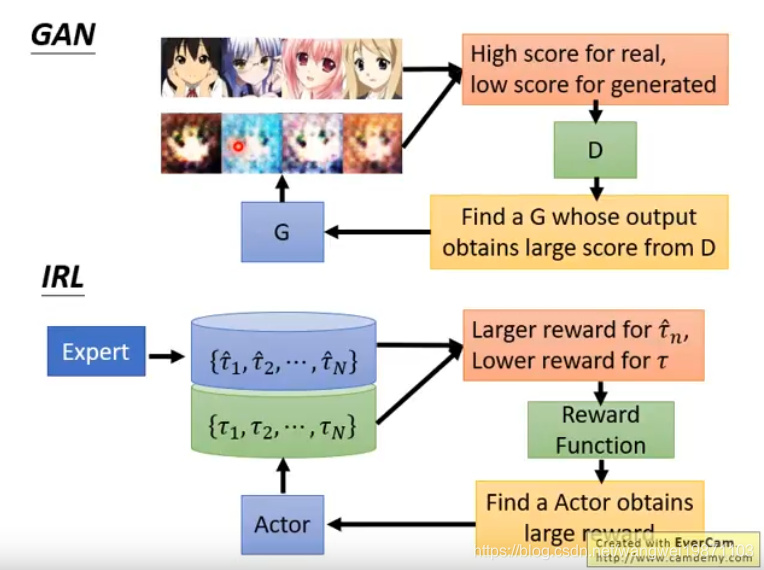
这个技术可以学习开车的风格,蓝色是人开的路线,红色是机器学习的: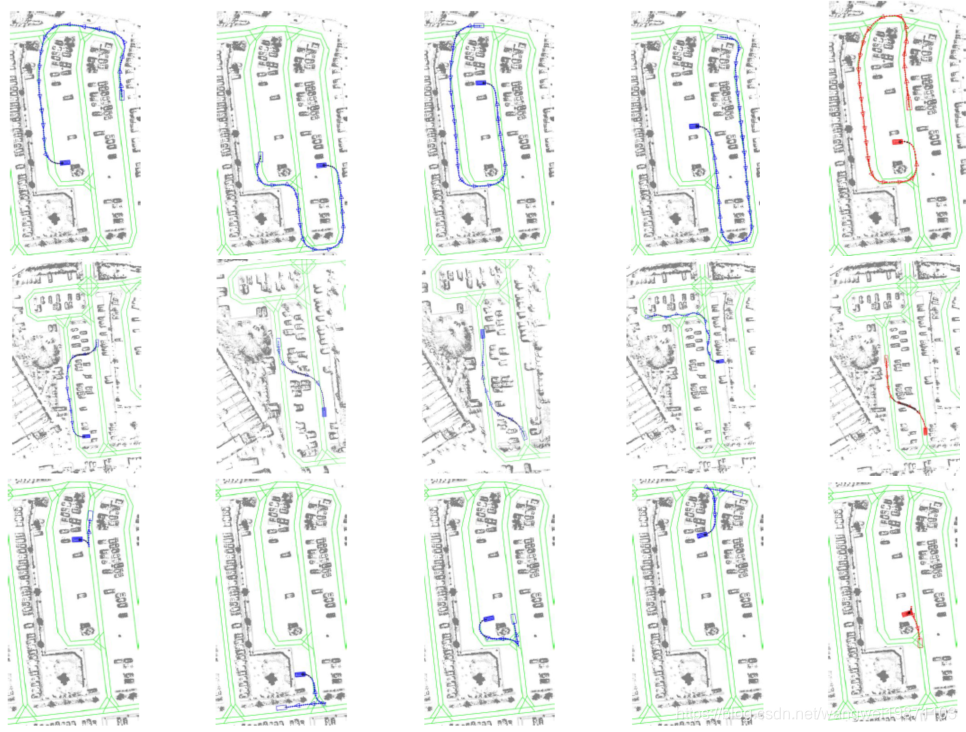
第三人称模仿学习:
有时候我们给机器模仿的可能不是机器看到的视角,机器可能只是第三人称视角,那我们怎么做呢:
我们可以想办法将第三人称的视角转换为第一人称: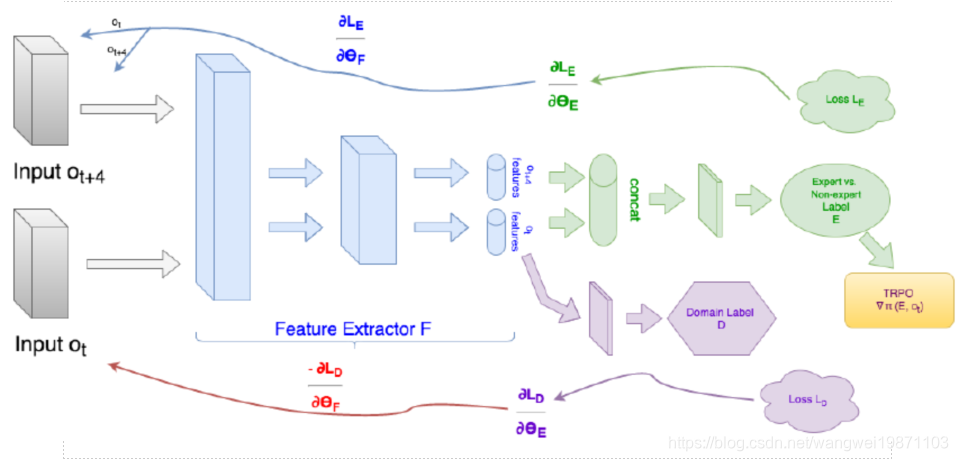
其实我们以前举的生成句子的那些例子就是一种行为复制,因为你看他看了很多人写的句子,希望他能按照这样的写出来,但我们现在有更好的方式,加入GAN的思想,就是用逆向强化学习,也就是SeqGAN: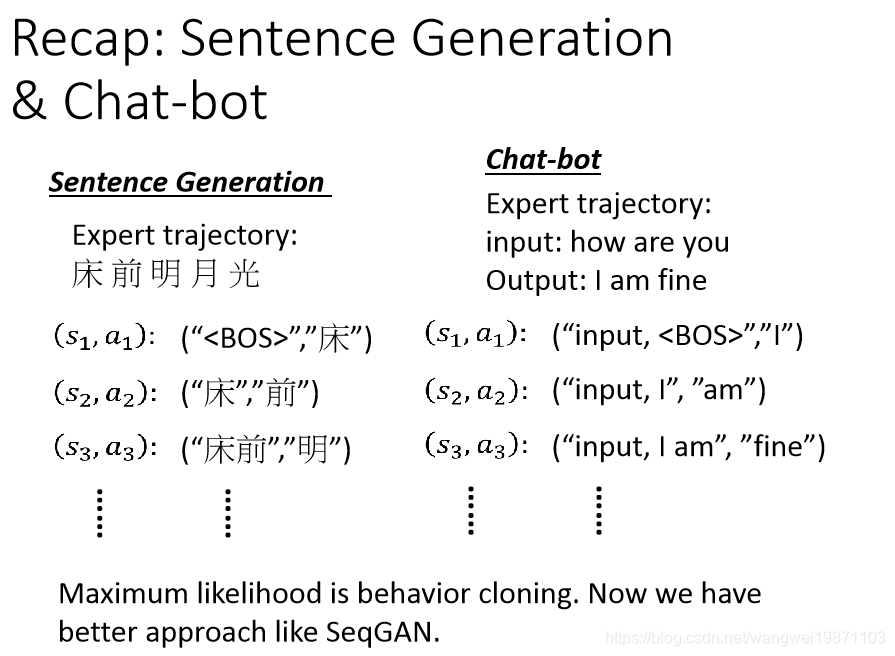
总结
本篇主要介绍了模仿学习,介绍了逆向强化学习,一种GAN的思想,强化学习课程应该结束了,后面看时间来点小项目更加深入的理解下强化学习吧。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自李宏毅课件,侵删。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)