
机器学习算法——线性回归与非线性回归
例如两个变量之间成正比(例如:x1 为房子的面积,单位是平方英尺;x2为房子的面积,单位是平方米;不可逆的情况很少发生,如果有这种情况,其解决问题的方法之一便是使用正则化以及岭回归等来求最小二乘法。的适用范围更广,可以用于描述非线性或者有两个及两个以上自变量的相关关系,它可以用来评价模型的效果。常用相关系数来衡量两个变量间的相关性,相关系数越大,相关性越高,使用直线拟合样本点时效果就越好。下图的样
目录
1. 梯度下降法
1.1 一元线性回归
定义一元线性方程
y = ω x + b y=\omega x+b y=ωx+b
则误差(残差)平方和
C ( ω , b ) = ∑ i = 1 n ( y i ^ − y i ) 2 C(\omega,b)=\sum_{i=1}^n(\hat{y_i}-y_i)^2 C(ω,b)=i=1∑n(yi^−yi)2
即
C ( ω , b ) = ∑ i = 1 n ( ω x i + b − y i ) 2 C(\omega,b)=\sum_{i=1}^n(\omega x_i+b-y_i)^2 C(ω,b)=i=1∑n(ωxi+b−yi)2
为方便计算,常写为如下形式
C ( ω , b ) = 1 2 n ∑ i = 1 n ( ω x i + b − y i ) 2 C(\omega,b)=\frac{1}{2n}\sum_{i=1}^n(\omega x_i+b-y_i)^2 C(ω,b)=2n1i=1∑n(ωxi+b−yi)2
其中, y i y_i yi为真实值, y i ^ \hat{y_i} yi^为预测值。
若用一元线性方程拟合上面的数据集,那么最佳的拟合直线方程需满足 C ( ω , b ) C(\omega,b) C(ω,b)最小,即使得真实值到直线竖直距离的平方和最小。因此需要求解使得 C ( ω , b ) C(\omega,b) C(ω,b)最小的参数 ω \omega ω和 b b b,即 min ω , b C ( ω , b ) \min_{\omega,b}C(\omega,b) ω,bminC(ω,b)
梯度下降公式
ω : = ω − α ∂ C ( ω , b ) ∂ ω = ω − α 1 n ∑ i = 1 n ( ω x i + b − y i ) 2 x i \omega:=\omega-\alpha \frac{\partial C(\omega,b)}{\partial \omega}=\omega-\alpha \frac{1}{n}\sum_{i=1}^n(\omega x_i+b-y_i)^2x_i ω:=ω−α∂ω∂C(ω,b)=ω−αn1i=1∑n(ωxi+b−yi)2xi
b : = b − α ∂ C ( ω , b ) ∂ b = b − α 1 n ∑ i = 1 n ( ω x i + b − y i ) 2 b:=b-\alpha \frac{\partial C(\omega,b)}{\partial b}=b-\alpha \frac{1}{n}\sum_{i=1}^n(\omega x_i+b-y_i)^2 b:=b−α∂b∂C(ω,b)=b−αn1i=1∑n(ωxi+b−yi)2
其中 α \alpha α为步长(学习率), : = := :=表示赋值操作。
梯度下降基本步骤
- 初始化 ω \omega ω和 b b b(常取0)
- 不断改变 ω \omega ω和 b b b,直到 C ( ω , b ) C(\omega,b) C(ω,b)到达一个全局最小值,或局部极小值。
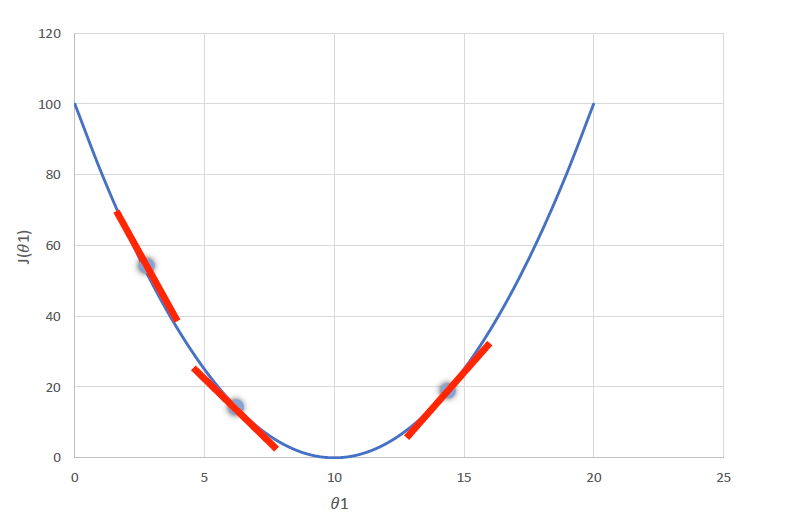
下图使用梯度下降能到达局部最小值
下图使用梯度下降能到达全局最小值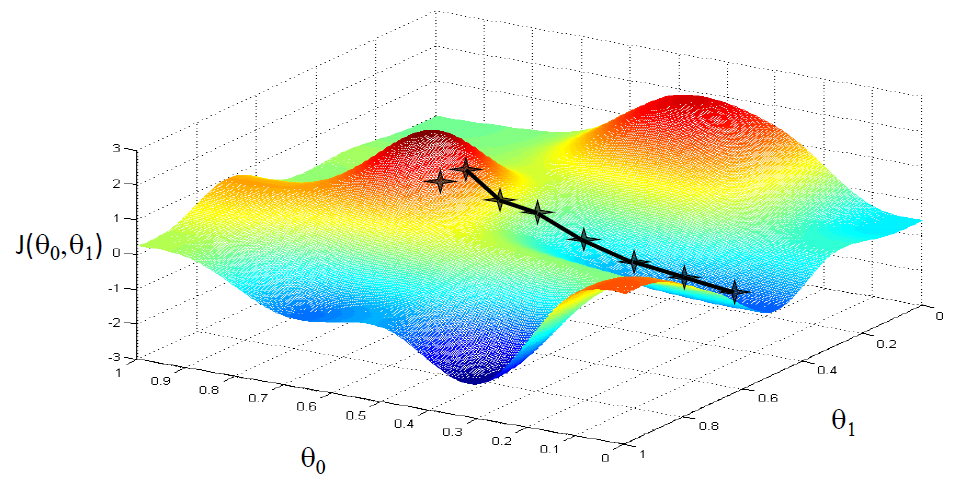
下图中,将 θ 1 \theta1 θ1看成 ω \omega ω, J ( θ 1 ) J(\theta 1) J(θ1)看成 C ( ω , b ) C(\omega,b) C(ω,b)。则
- 在第一个点处, ∂ C ( ω , b ) ∂ ω \frac{\partial C(\omega,b)}{\partial \omega} ∂ω∂C(ω,b)小于0,根据梯度下降公式,此时 ω \omega ω的值会增大,即往代价函数最小值的方向靠近。
- 在第三个点处, ∂ C ( ω , b ) ∂ ω \frac{\partial C(\omega,b)}{\partial \omega} ∂ω∂C(ω,b)大于0,根据梯度下降公式,此时 ω \omega ω的值会减小,即往代价函数最小值的方向靠近。
1.2 多元线性回归
定义多元线性方程
y = ω 1 x 1 + ω 2 x 2 + . . . + ω n x n + b y=\omega_1 x_1+\omega_2 x_2+...+\omega_n x_n+b y=ω1x1+ω2x2+...+ωnxn+b
误差平方和
C ( ω 1 , . . . , ω n , b ) = 1 2 n ∑ i = 1 n ( y ^ ( x i ) − y i ) 2 C(\omega_1,...,\omega_n,b)=\frac{1}{2n}\sum_{i=1}^n(\hat{y}(x^i)-y^i)^2 C(ω1,...,ωn,b)=2n1i=1∑n(y^(xi)−yi)2
注: y ^ ( x i ) \hat{y}(x^i) y^(xi)为预测值, y i y^i yi为真实值,这里的 x i x^i xi表示的是第 i i i个数据(包含多列属性)。
由1.1可得
b : = b − α 1 n ∑ i = 1 n ( y ^ ( x i ) − y i ) 2 x 0 i b:=b-\alpha \frac{1}{n}\sum_{i=1}^n(\hat{y}(x^i)-y^i)^2x_0^i b:=b−αn1i=1∑n(y^(xi)−yi)2x0i
这里 x 0 i = 1 x^i_0=1 x0i=1,以实现格式统一。
ω 1 : = ω 1 − α 1 n ∑ i = 1 n ( y ^ ( x i ) − y i ) 2 x 1 i \omega_1:=\omega_1-\alpha \frac{1}{n}\sum_{i=1}^n(\hat{y}(x^i)-y^i)^2x^i_1 ω1:=ω1−αn1i=1∑n(y^(xi)−yi)2x1i
ω 2 : = ω 2 − α 1 n ∑ i = 1 n ( y ^ ( x i ) − y i ) 2 x 2 i \omega_2:=\omega_2-\alpha \frac{1}{n}\sum_{i=1}^n(\hat{y}(x^i)-y^i)^2x^i_2 ω2:=ω2−αn1i=1∑n(y^(xi)−yi)2x2i
. . . ... ...
ω n : = ω n − α 1 n ∑ i = 1 n ( y ^ ( x i ) − y i ) 2 x n i \omega_n:=\omega_n-\alpha \frac{1}{n}\sum_{i=1}^n(\hat{y}(x^i)-y^i)^2x^i_n ωn:=ωn−αn1i=1∑n(y^(xi)−yi)2xni
改写为向量版本
y = ω T x y=\omega ^Tx y=ωTx
ω : = ω − α 1 n X T ( y ^ ( x ) − y ) \omega:=\omega-\alpha \frac{1}{n} X^T(\hat{y}(x)-y) ω:=ω−αn1XT(y^(x)−y)
其中, ω \omega ω和 x x x(某行数据)均为列向量,实际应用。
1.3 标准方程法
调用sklearn实现一元线性回归与多元线性回归的梯度下降时,sklearn内部的实现并没有使用梯度下降法,而是使用标准方程法。
公式推导(利用最小二乘法)12
上述公式推导使用到的矩阵求导公式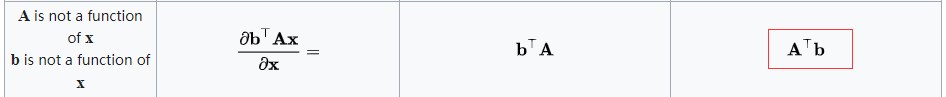

由推导的公式可知,需要满足的条件是 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1存在。在机器学习中, ( X T X ) − 1 (X^TX)^{-1} (XTX)−1不可逆的原因通常有两种,一种是自变量间存在高度多重共线性(可以近似理解为自变量矩阵中包含线性相关的行或列),例如两个变量之间成正比(例如:x1 为房子的面积,单位是平方英尺;x2为房子的面积,单位是平方米;而1
平方英尺=0.0929 平方米),那么在计算 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1时,可能得不到结果或者结果无效;另一种则是当特征变量过多(样本数 m ≤ \le ≤特征数量 n)的时候也会导致 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1不可逆。 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1不可逆的情况很少发生,如果有这种情况,其解决问题的方法之一便是使用正则化以及岭回归等来求最小二乘法。
单变量情况下利用最小二乘法求解最佳参数
1.4 梯度下降法与标准方程法的优缺点
| 算法 | 优点 | 缺点 |
|---|---|---|
| 梯度下降法 | 当特征值非常多的时候也可以很好的工作 | 需要选择合适的学习率;需要迭代多个周期;只能得到最优解的近似值 |
| 标准方程法 | 不需要学习率;不需要迭代;可以得到全局最优解 | 需要计算 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1,时间复杂度大约是 O ( n 3 ) O(n^3) O(n3),n是特征数量 |
2. 相关系数与决定系数
常用相关系数来衡量两个变量间的相关性,相关系数越大,相关性越高,使用直线拟合样本点时效果就越好。
公式如下(两个变量的协方差除以标准差的乘积)
r ( X , Y ) = C o v ( X , Y ) V a r [ X ] V a r [ Y ] r(X,Y)=\frac{Cov(X,Y)}{\sqrt{Var[X]Var[Y]}} r(X,Y)=Var[X]Var[Y]Cov(X,Y)
= ∑ i = 1 n ( X i − X ˉ ) ( Y i − Y ˉ ) ∑ i = 1 n ( X i − X ˉ ) 2 ∑ i = 1 n ( Y i − Y ˉ ) 2 =\frac{\sum_{i=1}^n(X_i-\bar{X})(Y_i-\bar{Y})}{\sqrt{\sum_{i=1}^n(X_i-\bar{X})^2}\sqrt{\sum_{i=1}^n(Y_i-\bar{Y})^2}} =∑i=1n(Xi−Xˉ)2∑i=1n(Yi−Yˉ)2∑i=1n(Xi−Xˉ)(Yi−Yˉ)
其中
C o v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = 1 n ∑ i = 1 n ( X i − X ˉ ) ( Y i − Y ˉ ) Cov(X,Y)=E[(X-E(X))(Y-E(Y))]=\frac{1}{n}\sum_{i=1}^n(X_i-\bar{X})(Y_i-\bar{Y}) Cov(X,Y)=E[(X−E(X))(Y−E(Y))]=n1i=1∑n(Xi−Xˉ)(Yi−Yˉ)
下图的样本点中,左图的相关系数为0.993,右图的相关系数为0.957,即左图的样本点变量间的相关性更高。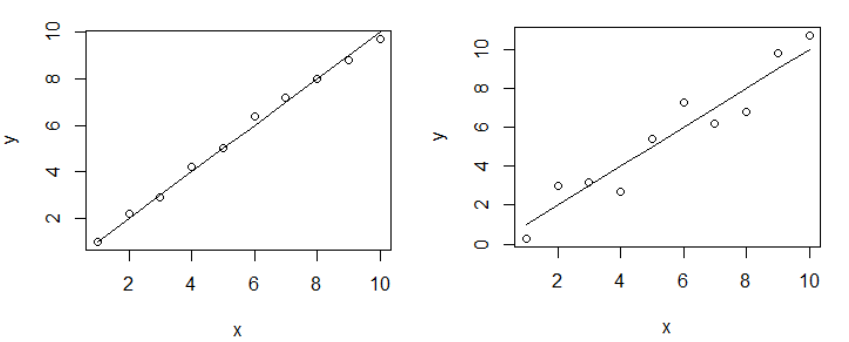
相关系数用于描述两个变量之间的线性关系,但决定系数 R 2 R^2 R2的适用范围更广,可以用于描述非线性或者有两个及两个以上自变量的相关关系,它可以用来评价模型的效果。
总平方和(SST)
∑ i = 1 n ( y i − y ˉ ) 2 \sum_{i=1}^{n}(y_i-\bar{y})^2 i=1∑n(yi−yˉ)2
回归平方和(SSR)
∑ i = 1 n ( y ^ − y ˉ ) 2 \sum_{i=1}^{n}(\hat{y}-\bar{y})^2 i=1∑n(y^−yˉ)2
残差平方和(SSE)
∑ i = 1 n ( y i − y ^ ) 2 \sum_{i=1}^{n}(y_i-\hat{y})^2 i=1∑n(yi−y^)2
三者的关系
S S T = S S R + S S E SST=SSR+SSE SST=SSR+SSE
决定系数
R 2 = S S R S S T = 1 − S S E S S T = ∑ i = 1 n ( y i − y ^ ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 R^2=\frac{SSR}{SST}=1-\frac{SSE}{SST}=\frac{\sum_{i=1}^{n}(y_i-\hat{y})^2}{\sum_{i=1}^{n}(y_i-\bar{y})^2} R2=SSTSSR=1−SSTSSE=∑i=1n(yi−yˉ)2∑i=1n(yi−y^)2
R 2 R^2 R2的取值范围在负无穷到1之间,值为1表示模型完全解释了因变量的变化,值为负数表示该模型的表现比简单地使用均值来预测(此时值为0)还要差。
3. 数值归一化
将取值范围处理为0-1之间
n e w V a l u e = o l d V a l u e − m i n m a x − m i n newValue=\frac{oldValue-min}{max-min} newValue=max−minoldValue−min
将取值范围处理为-1-1之间
n e w V a l u e = 2 ( o l d V a l u e − m i n m a x − m i n − 0.5 ) newValue=2(\frac{oldValue-min}{max-min}-0.5) newValue=2(max−minoldValue−min−0.5)
均值标准化,u为数据平均值,s为数据方差
n e w V a l u e = o l d V a l u e − u s newValue=\frac{oldValue-u}{s} newValue=soldValue−u
4. 预防过拟合的方法
- 减少特征
- 增加数据量
- 正则化(Regularized)
正则化代价函数
L1正则化(LASSO代价函数)
C ( ω ) = 1 2 m [ ∑ i = 1 m ( y ^ ( x i ) − y i ) 2 + λ ∑ j = 1 n ∣ ω j ∣ ] C(\omega)=\frac{1}{2m} \left [ \sum_{i=1}^{m}(\hat{y}(x^i)-y^i)^2+\lambda \sum_{j=1}^{n}|\omega _j| \right ] C(ω)=2m1[i=1∑m(y^(xi)−yi)2+λj=1∑n∣ωj∣]
L2正则化(岭回归代价函数)
C ( ω ) = 1 2 m [ ∑ i = 1 m ( y ^ ( x i ) − y i ) 2 + λ ∑ j = 1 n ω j 2 ] C(\omega)=\frac{1}{2m} \left [ \sum_{i=1}^{m}(\hat{y}(x^i)-y^i)^2+\lambda \sum_{j=1}^{n}\omega ^2_j \right ] C(ω)=2m1[i=1∑m(y^(xi)−yi)2+λj=1∑nωj2]
其中, λ ∑ j = 1 n ω j 2 \lambda \sum_{j=1}^{n}\omega ^2_j λ∑j=1nωj2称为L2正则项(也叫惩罚项)。
5. 岭回归
对上述代价函数的L2正则化(也叫岭回归代价函数)进行求导(系数m可以不用写,因为有未知参数 λ \lambda λ存在,因此惩罚项的系数 1 2 \frac{1}{2} 21可以不写),详细推导流程可参考[1.3 标准方程法])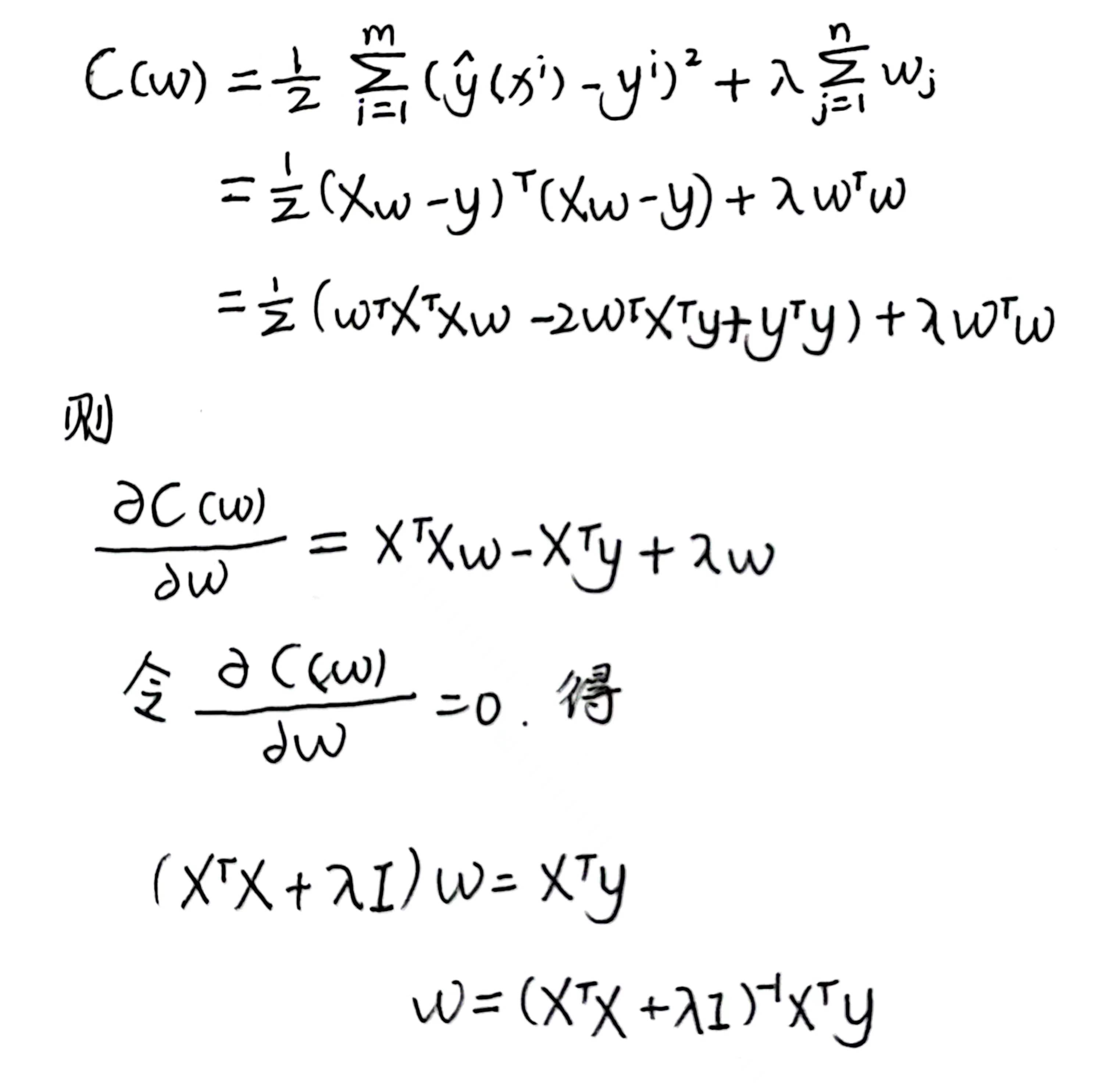
使用到的矩阵求导公式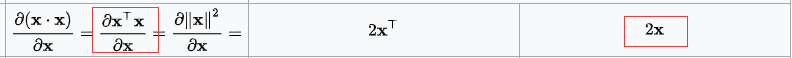
公式
ω = ( X T X + λ I ) − 1 X T y \omega = (X^TX+\lambda I)^{-1}X^Ty ω=(XTX+λI)−1XTy
称为参数 ω \omega ω的岭回归估计, λ \lambda λ为岭系数, I I I为单位矩阵。
岭回归公式的理解:
由 ω = ( X T X ) − 1 X T y \omega=(X^TX)^{-1}X^Ty ω=(XTX)−1XTy可知,如果数据的特征比样本点还多,数据特征n ,样本个数 m,如果n>m ,则计算 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1时会出错,因为 ( X T X ) (X^TX) (XTX)不是满秩矩阵,所以不可逆。加上 λ I \lambda I λI后,由于单位矩阵 I I I是满秩矩阵,所以 ( X T X + λ I ) (X^TX+\lambda I) (XTX+λI)也是满秩矩阵,故可逆。
岭系数 λ \lambda λ的选取3:
- 各回归系数的岭估计基本稳定
- 残差平方和增大不太多
岭回归的作用:
- 使得矩阵最终运算结果满秩,从而解决多重共线性问题
- 对所有特征列的因变量解释程度进⾏了惩罚,且λ越⼤惩罚作⽤越强。最终希望特征的权重越小越好,也即忽略一些不重要的特征4。
6. LASSO算法
LASSO(The Least Absolute Shrinkage and Selectionator operator[最小绝对收缩和选择算子])算法通过构造一个一阶惩罚函数获得一个精炼的模型;并通过确定一些指标(变量)的系数为零(岭回归估计系数等于 0 的机会微乎其微,造成筛选变量困难)来筛选变量。LASSO算法擅长处理具有多重共线性的数据,与岭回归一样是有偏估计。
岭回归代价函数中 λ \lambda λ的值可以用于限制 ∑ j = 1 n ω j 2 ≤ t \sum_{j=1}^n\omega ^2_j \le t ∑j=1nωj2≤t,LASSO代价函数中 λ \lambda λ的值可以用于限制 ∑ j = 1 n ∣ ω j ∣ ≤ t \sum_{j=1}^n|\omega _j| \le t ∑j=1n∣ωj∣≤t。
上图中,蓝色区域代表变量的取值范围,红色椭圆线代表代价函数的等高线,越靠近椭圆线中心,误差越小。可以发现,LASSO算法的变量取值可以为0,而岭回归算法的变量取值不容易为0。
7. 准确率与召回率
一般来说,正确率(Precision)就是检索出来的条目有多少是正确的,召回率(Recall)就是所有正确的条目有多少被检索出来。
F 1 = 2 p r e c i s i o n ∗ r e c a l l p r e c i s i o n + r e c a l l F_1=2\frac{precision*recall}{precision+recall} F1=2precision+recallprecision∗recall
是综合反映整体的评价指标。
8. 逻辑回归
Sigmoid函数
g ( x ) = 1 1 + e − x g(x)=\frac{1}{1+e^{-x}} g(x)=1+e−x1
函数图像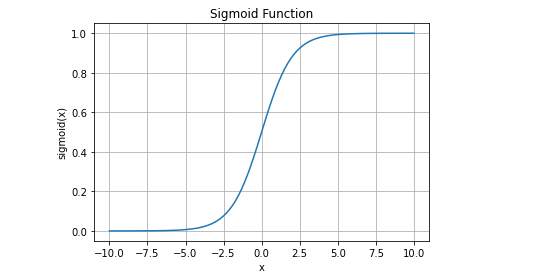
逻辑回归的预测函数
y ^ ( x ) = g ( ω T x ) = 1 1 + e − ω T X \hat{y}(x)=g(\omega^Tx)=\frac{1}{1+e^{-\omega^TX}} y^(x)=g(ωTx)=1+e−ωTX1
损失函数
C ( ω ) = − 1 n ∑ i = 1 n [ y i l o g y ^ ( x i ) + ( 1 − y i ) l o g ( 1 − y ^ ( x i ) ) ] C(\omega )=-\frac{1}{n} \sum_{i=1}^{n}[y^ilog\hat{y}(x^i) +(1-y^i)log(1-\hat{y}(x^i))] C(ω)=−n1i=1∑n[yilogy^(xi)+(1−yi)log(1−y^(xi))]
公式解释
逻辑回归的梯度下降公式
ω : = ω − α 1 n X T ( y ^ ( x ) − y ) \omega:=\omega-\alpha \frac{1}{n} X^T(\hat{y}(x)-y) ω:=ω−αn1XT(y^(x)−y)
其中, X X X为输入数据(矩阵或列向量)。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)