【万字长文】还在手动找代码?Cursor的索引机制,让你的效率起飞!
本文探索了AI编程工具中代码库索引机制的技术原理。作者首先基于Cursor官方文档分析其codebase indexing流程,包括Merkle Tree哈希计算、向量存储等技术要点。随后深入研究了Merkle Tree在Git等系统中的应用,以及Turbopuffer向量数据库的架构设计。为验证这些技术方案,作者还体验了开源的Continue项目,对比分析了其在代码索引方面的不同实现方式。通过这

旅程的起点
高德信息工程团队正朝着"AI-First团队"的方向转型,致力于构建一支深度融合AI能力的新型业务研发团队。有幸成为AI先锋队的一员,在这个过程中获得了许多专业的培训机会,学习了基于AI工具进行项目开发的各种范式和成功案例。
在日常业务开发中,我们开始大量使用Cursor进行需求分析、方案设计以及代码编写。这个工具不仅有效扩展了我的技术边界,更显著提升了我的研发效率。从最初的谨慎尝试到现在的深度依赖,AI编程工具已经成为我开发流程中不可或缺的一部分。
虽然在使用层面我已经积累了不少经验和技巧,但对于这些工具的底层机制,我了解甚少。一个现象引起了我的注意:早期的AI编程插件大多只能提供单文件维度的代码辅助,而现在的Cursor等AI编程工具却能够基于整个代码库进行智能分析和代码生成。这种能力的跃升背后究竟隐藏着什么样的技术机制?出于这样的好奇心,我在工作之余花时间查阅了相关资料,试图揭开codebase indexing这个"黑盒"的神秘面纱。
本文将记录我以一个"外行"的视角,用朴素直观的方式去思考,通过搜集公开资料、进行实验验证,一步步探索codebase索引机制的过程。这既是一次技术探索,也是一次个人学习的记录,帮助我补充在AI编程相关领域的知识空白。希望这个探索历程能够给同样对AI编程工具原理感兴趣的朋友们带来启发,也期望能够抛砖引玉,引发更多有价值的讨论。
从Cursor官方文档开始
对于这样的闭源软件, 只能通过官方公开渠道检索其技术细节, 这里使用官方网站的“Search”功能获取codebase相关资料, 另外在其Forum里也查到一些关键信息。
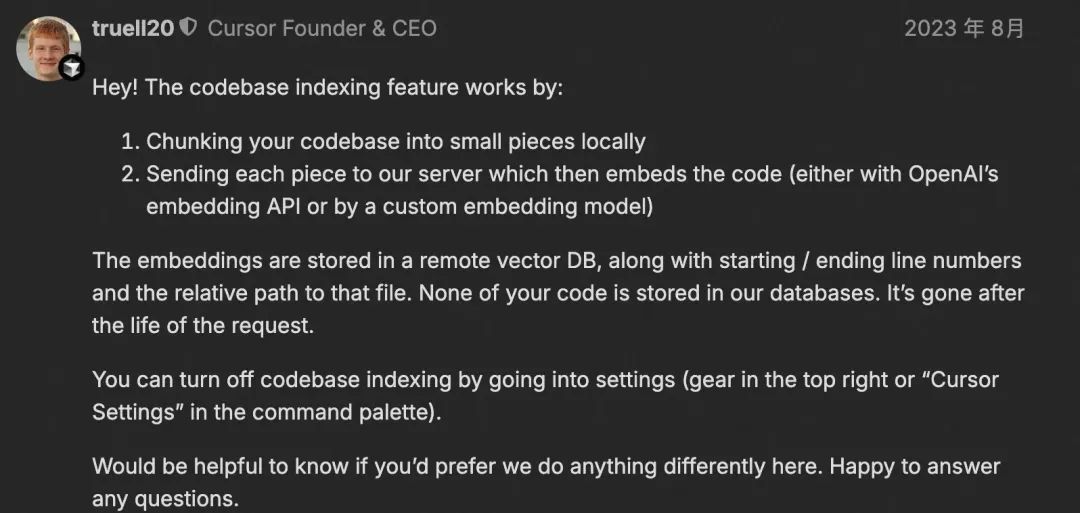
阅读完所有的文档资料后, 对于cursor的codebase indexing, 可以汇总如下:
工作过程
-
扫描打开的文件夹,计算所有文件的 Merkle 树哈希;
-
遵循 .gitignore、.cursorignore 和 .cursorindexingignore,忽略指定文件/目录;
-
Merkle 树同步到服务器,每10分钟检测变更,仅上传变更文件;
-
服务器端对文件分块并计算向量,存储于 Turbopuffer,缓存于 AWS;
-
同时索引Git历史(提交SHA、父级信息、混淆文件名);
-
查询时本地计算向量,服务器返回混淆文件路径和行号,客户端读取对应代码片段后上传用于AI回答;
隐私与安全
-
文件路径按'/'和'.'分段,使用客户端密钥+6字节随机数加密,泄露部分目录结构但隐藏大部分信息;
-
隐私模式下,不在服务器或Turbopuffer存储明文代码;
-
临时缓存文件使用客户端生成的唯一密钥加密,仅在请求期间存在;
-
存在向量逆向攻击的理论风险;
-
索引服务经常高负载,可能需要多次上传才能完全索引;
功能效果
-
聊天模式中的代码库搜索工具,用于语义搜索;
-
更好的AI建议上下文理解;
-
更准确的文件和代码发现;
-
当Cursor自动搜索上下文时提高相关性;
总结
可以用以下两个流程图总结cursor codebase indexing 以及query的流程:
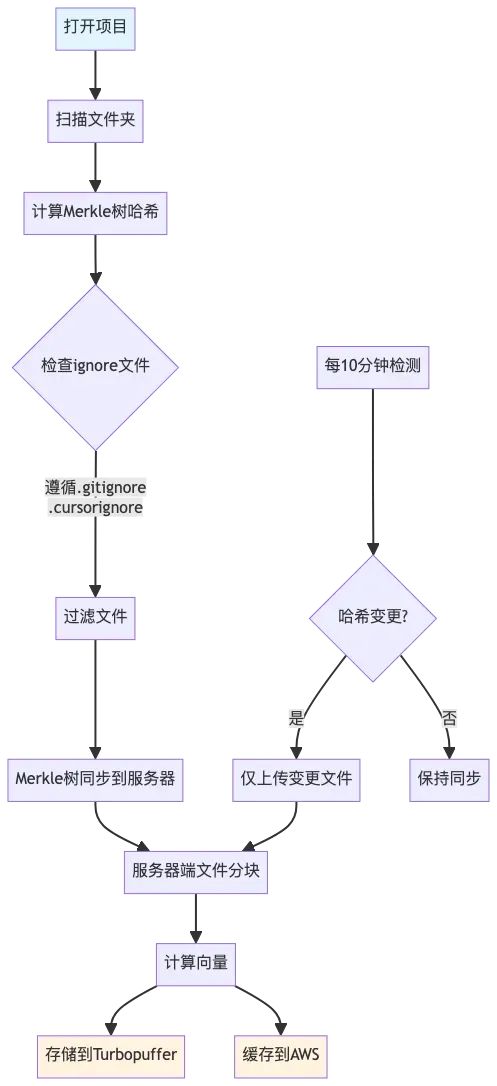
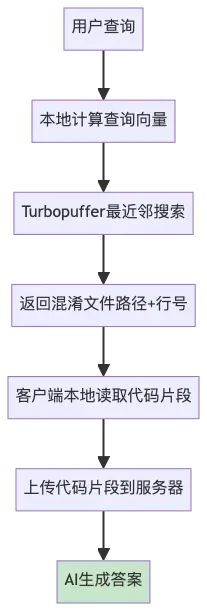
对于以上的流程, 外行的我有了一些思路, 也产生了一些疑问
-
Merkle Tree是什么? 起到了什么作用?
-
turbopuffer看起来是一个向量库, 为什么cursor要将向量存入其中? 它解决了什么场景下的什么问题?
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

理解Merkle tree
什么是Merkle Tree
默克尔树(Merkle Tree)也叫哈希树,是一种树形数据结构:
-
叶子节点(Leaf Node):每个叶子节点存储的是某个数据块的加密哈希值。
-
非叶子节点(Branch/Inner Node):每个非叶子节点存储的是其所有子节点哈希值拼接后的哈希。
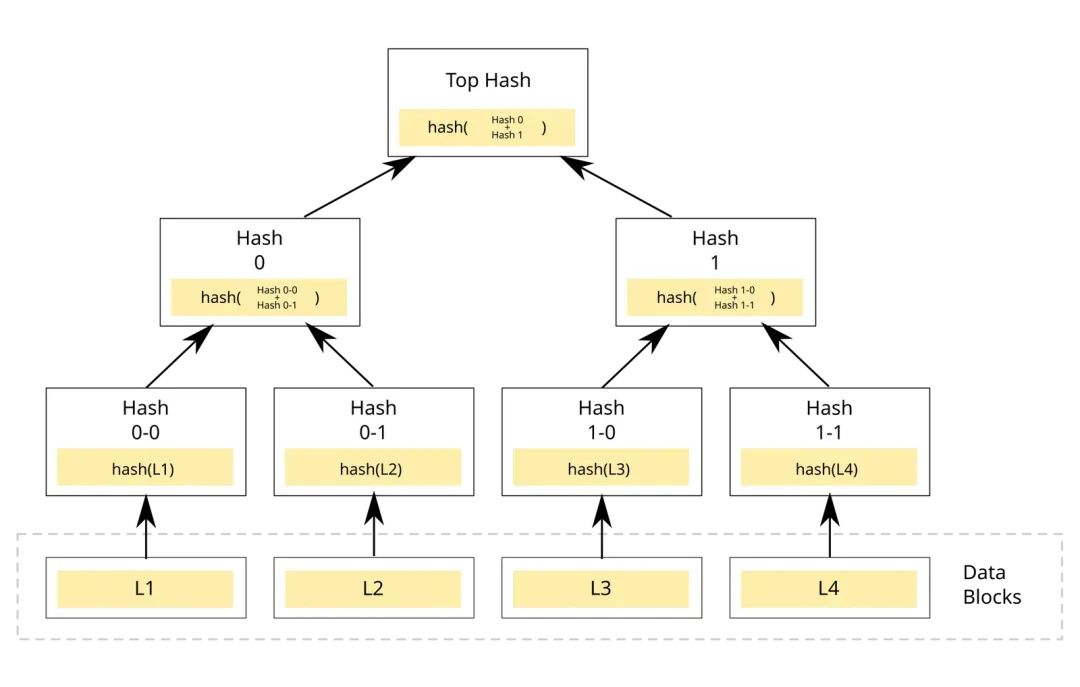
举例说明:
假设有两个数据块 L1 和 L2
先分别对 L1、L2 计算哈希,得到 Hash 0-0 和 Hash 0-1。
然后将 Hash 0-0 和 Hash 0-1 拼接,再计算一次哈希,得到 Hash 0(父节点)。
最后将Hash 0与Hash 1拼接, 再计算一次哈希, 得到Top Hash(根节点)
Merkle Tree 的作用
1. 高效验证
要证明某个数据块属于这棵树,只需要提供从该叶子节点到根节点路径上的"兄弟节点"哈希值。验证复杂度为 O(log n),而不是 O(n)。
2. 数据完整性保证
只要根哈希(Merkle Root)保持不变,就能确保整个数据集未被篡改。任何底层数据的修改都会导致根哈希发生变化。
3. 增量同步
通过比较不同版本的Merkle Tree,可以快速定位发生变化的数据块,实现高效的增量同步。
Merkle Tree 的应用场景
-
区块链技术:比特币、以太坊等用于验证交易数据的完整性;
-
分布式存储:IPFS、Amazon DynamoDB等用于数据一致性校验;
-
版本控制系统:Git使用类似机制追踪文件变更和验证仓库完整性;
因为没有接触过区块链和分布式存储原理, 这里用每个程序员都使用的git来简单介绍下Merkle Tree在版本控制系统里的应用。
版本控制软件git
Git 的对象分为四类:blob、tree、commit、tag
Merkle Tree 结构体现在 blob、tree、commit 这三层
-
blob:存储文件内容(叶子节点)。
-
tree:存储目录结构,记录目录下所有的 blob/tree 的哈希(中间节点)。
-
commit:存储一次提交,指向一个 tree(根节点),并且包含父 commit 的哈希以及作者、时间等信息。
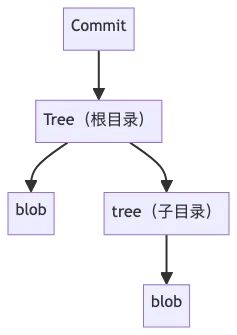
通过一个简单的示例来说明, 构造一个文件目录如下
/Users/ko/Documents/merkle/├── README.md└── src/└── main.java
第一次提交
README.md 内容为 A
src/main.java 内容为 X
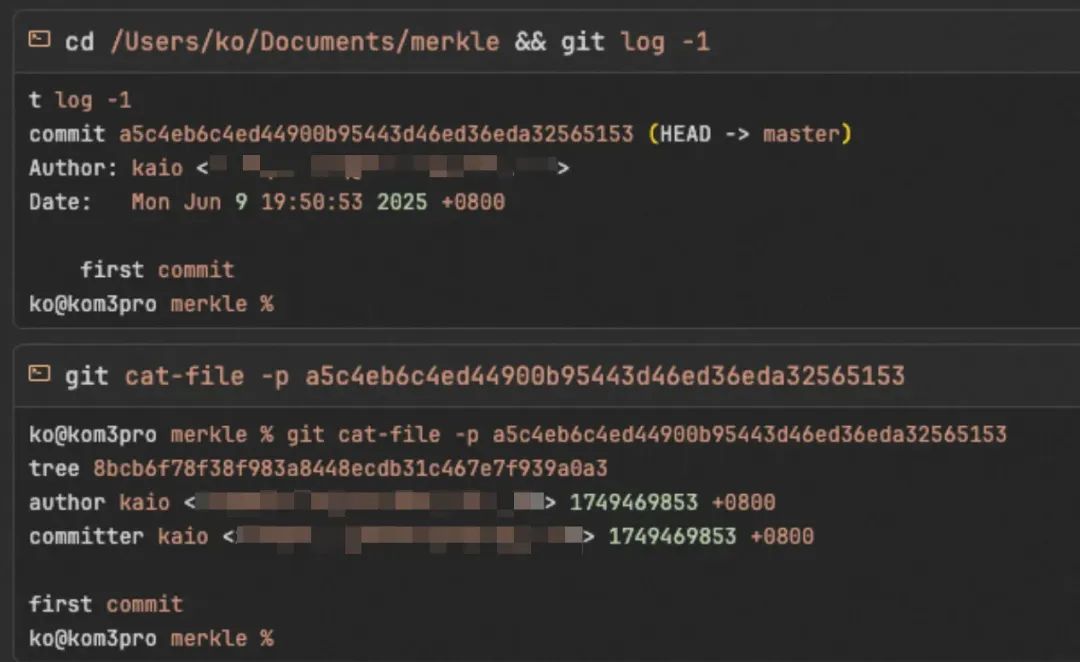
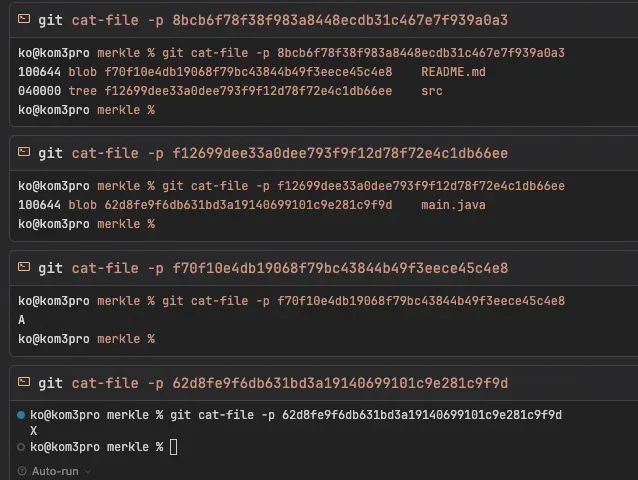
最后得到的Merkle Tree 如下:
commit: a5c4eb6c4ed44900b95443d46ed36eda32565153|tree: 8bcb6f78f38f983a8448ecdb31c467e7f939a0a3├── README.md → blob: f70f10e4db19068f79bc43844b49f3eece45c4e8 (内容: A)└── src/|tree: f12699dee33a0dee793f9f12d78f72e4c1db66ee└── main.java → blob: 62d8fe9f6db631bd3a19140699101c9e281c9f9d (内容: X)
第二次提交
修改 src/main.java,内容变为 Y,README.md 没变。
截图省略, 最后得到的Merkle Tree如下:
commit: 89525719a212f4eca05046aabd270ffb33986359|tree: c804c7202de606c518dc2bef93d9e3a5c5e71da2├── README.md → blob: f70f10e4db19068f79bc43844b49f3eece45c4e8 (内容: A)└── src/|tree: 52e68717674074112abe8865a0be7fc111b1e523└── main.java → blob: 9bda8c35c2f1978aa4b691660a4a1337523d3ce4 (内容: Y)
只要递归对比两次提交的 tree 结构,找到哈希不同的 blob,就能精准识别出所有被修改的文件。
这正是 Merkle Tree 在 Git 变更识别中的核心价值。
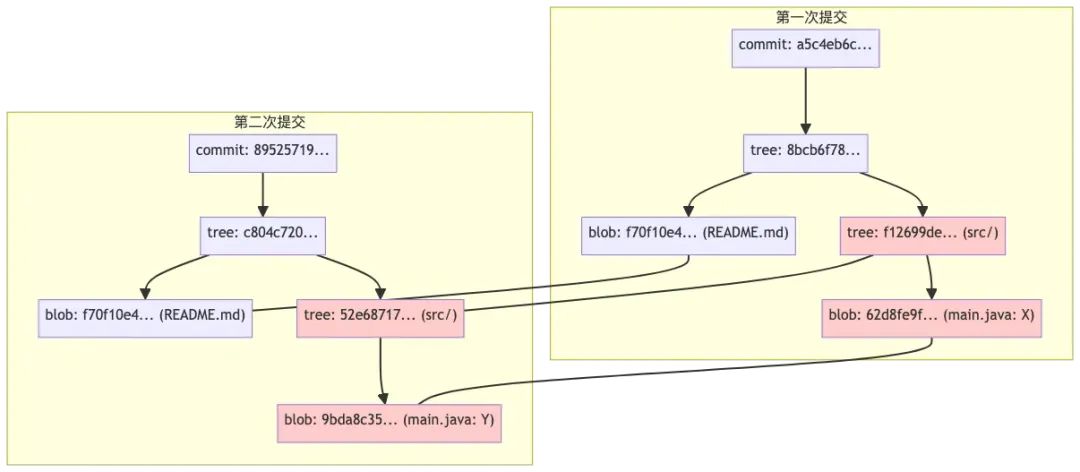
Merkle Tree在git中的功能总结
-
高效完整性校验,防篡改
-
每个对象(blob、tree、commit)都用哈希值唯一标识,任何内容变动都会导致哈希变化。
-
只要根哈希(commit 哈希)没变,说明整个项目历史、内容都没被篡改。
-
高效存储与去重
-
相同内容的文件(blob)或目录结构(tree)只存一份,极大节省空间。
-
没有变动的部分直接复用历史对象,无需重复存储。
-
高效对比和查找变更
-
只需对比 tree 或 commit 的哈希,就能快速判断两次提交是否完全一致。
-
递归对比 tree 结构,可以高效定位到具体变动的文件和内容。
-
历史可追溯,结构清晰
-
每个 commit 通过 parent 字段串联,形成不可篡改的历史链。
-
可以随时还原任意历史时刻的完整项目快照。
探索turbopuffer向量数据库

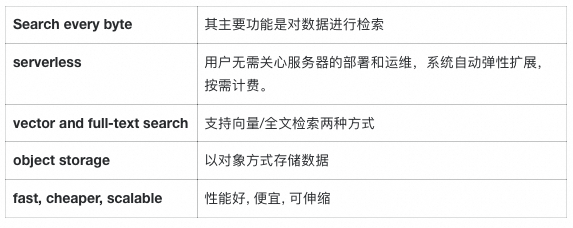
Search every byte
serverless vector and full-text search built from first principles on object storage: fast, 10x cheaper, and extremely scalable
从官网的标题图中我们可以得到以下信息:
我们也发现turbopuffer将cursor作为其优秀案例宣传, 并解释了cursor选择该产品的原因和结果。

可以简单总结为:
turbopuffer的serverless架构, 缓存/冷热策略,为Cursor实现了成本和性能的完美平衡。
产品体验
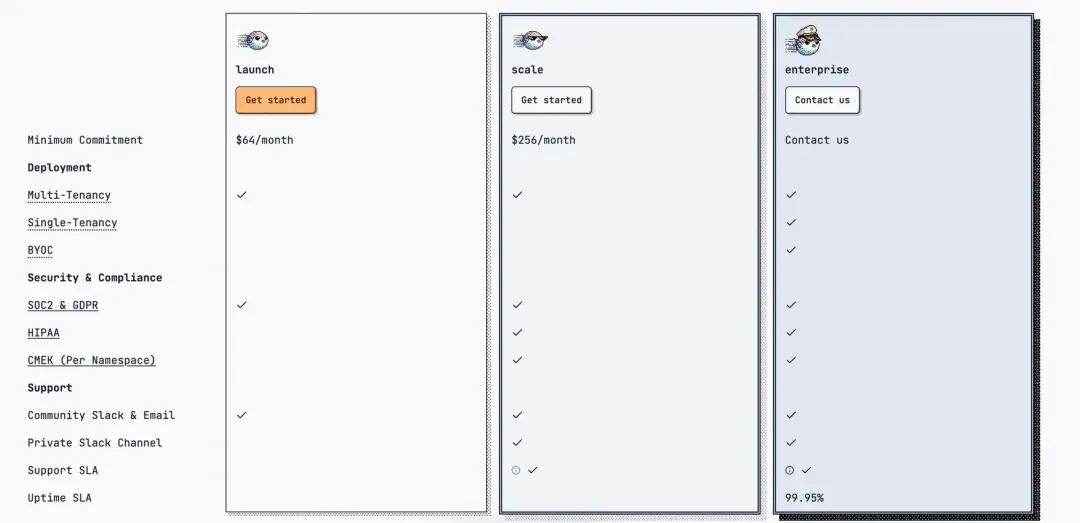
turbopuffer采用按量计费的模式, 但其限制了64美元/月的最低消费, 在与他们的解决方案工程师沟通之后, 同意为我的账号加白处理进行免费体验。
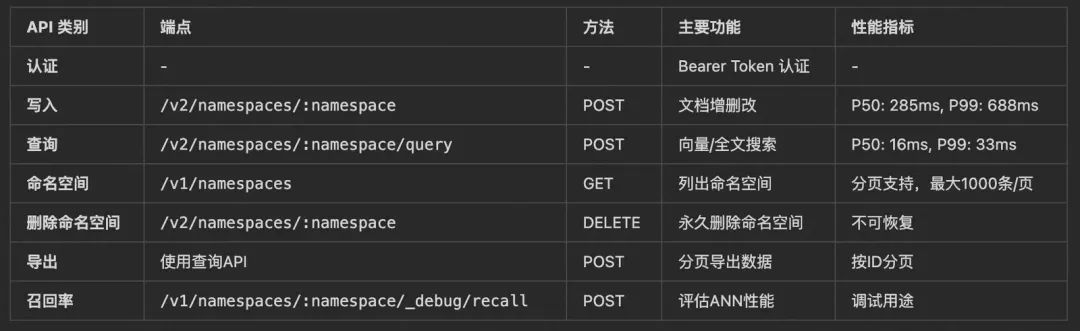
turbopuffer提供了一系列标准的HTTP RESTful 接口, 供业务方对向量库进行读写操作。
这里用cursor快速实现了一个python用例, 其功能是对一个代码文件分块, 调用本地通过ollama部署的向量模型nomic-embed-text向量化, 然后调用turbopuffer提供的write接口写入向量库, 最后调用Query检索向量。
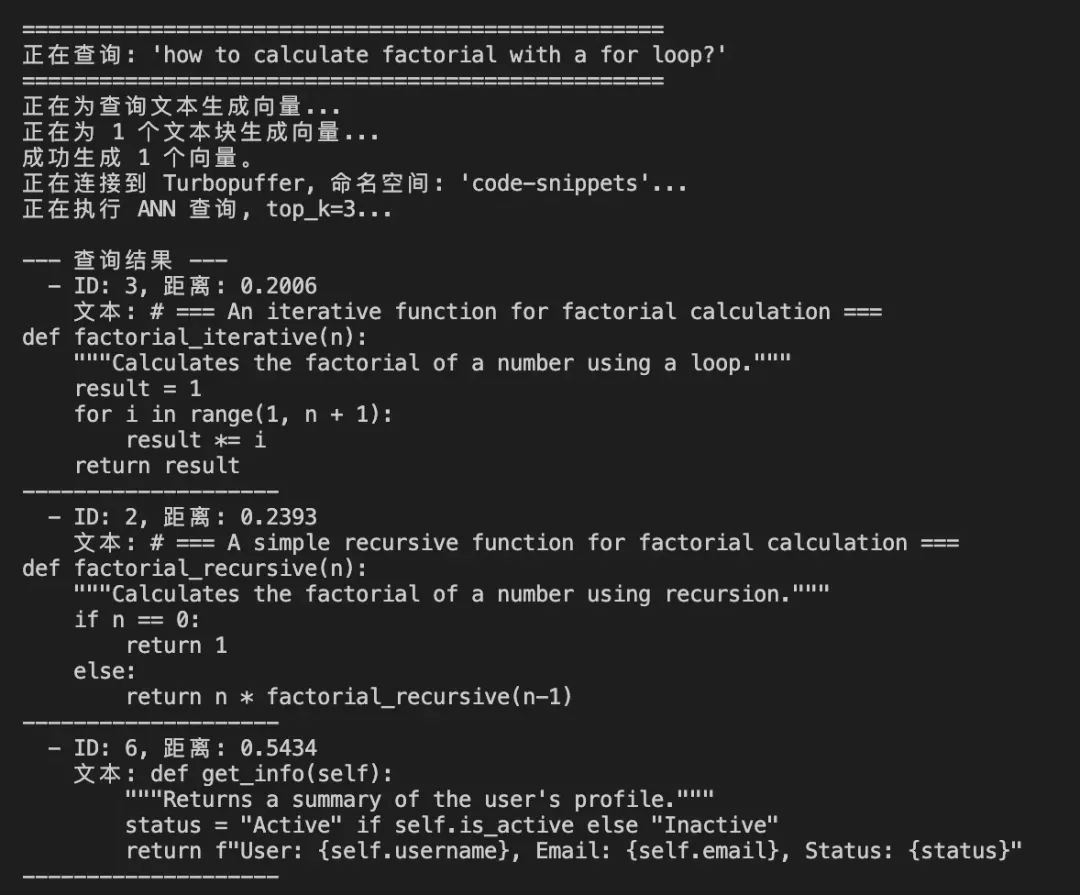
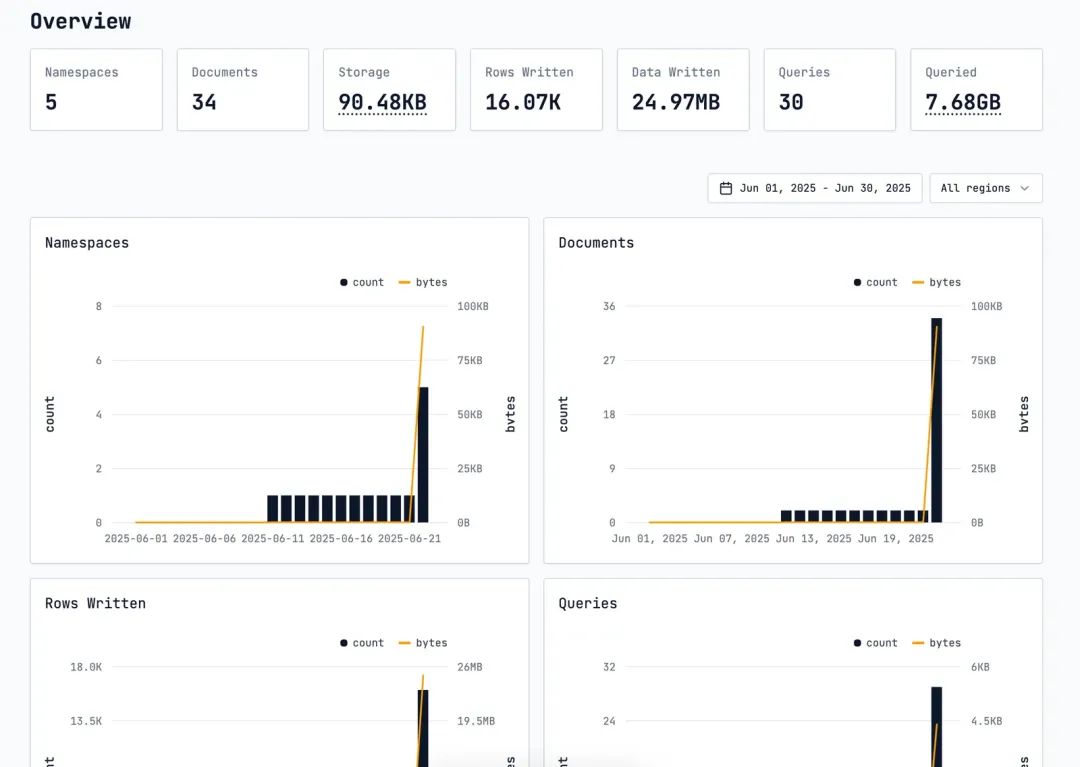
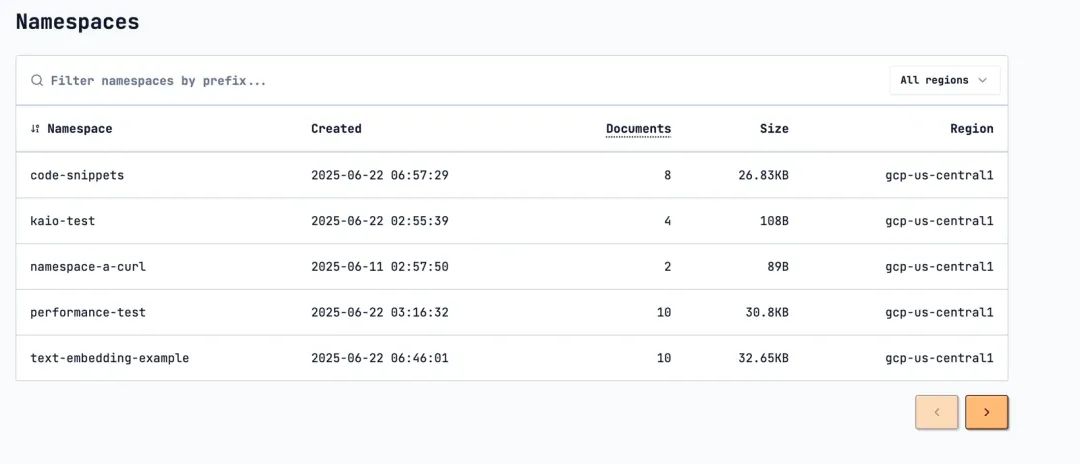
turbopuffer在WEB上提供了较为简单的管理后台, 可以查看Namespaces, Documents, Rows Written, Queries, Storage 等相关统计信息。
体验下来, turbopuffer简单易用, 没有太多的复杂功能, 就是一个提供存储和检索能力的向量库. 其真正的核心技术应该在于其独特的后端架构和由此带来的性能优化以及成本优势, 下面将对其架构设计进行介绍。
架构分析
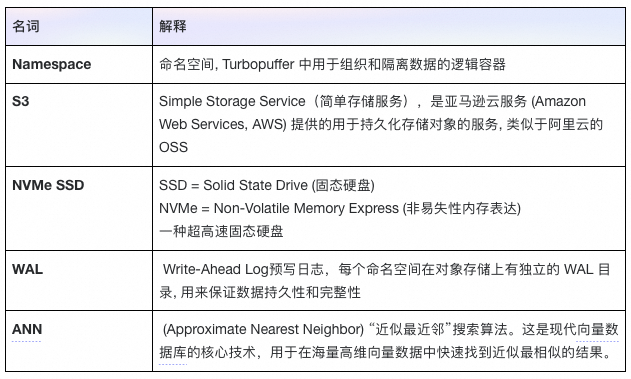
以下分析来自于turbopuffer官方提供的架构文档, 为了便于理解, 先对频繁出现的一些陌生名词进行简单的解释。
数据写入
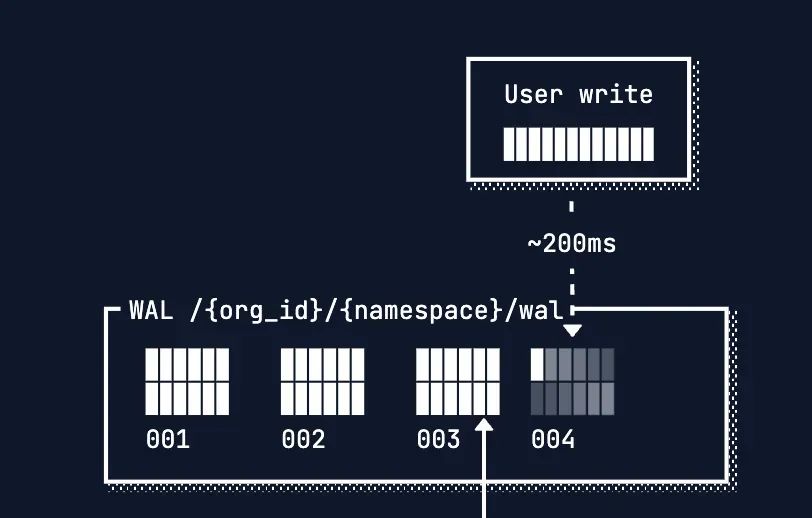
写入操作并不会直接将数据写入到向量库中, 而是放入到WAL日志文件中
-
每一次写入操作在文件写入对象存储成功后同步返回;
-
采用100毫秒的时间窗口来收集请求, 所有对同一命名空间的并发写入,都会被合并成一个单独的WAL文件;
-
每个命名空间每秒最多只能提交一次批处理后的WAL文件。
可以看到turbopuffer牺牲了单次操作的响应速度(高延迟),换来了系统处理海量并发请求的能力(高吞吐量)。
这对于代码索引这类后台批量任务来说,是非常理想的设计。它不关心单次写入快不快,只关心能否在短时间内把所有数据都“喂”给系统。
这里有一个关键点, 新写入的数据还没有写入索引文件中, 这时候如何保证数据可查? turbopuffer对此有个特殊逻辑, 见后文的分析。
索引创建
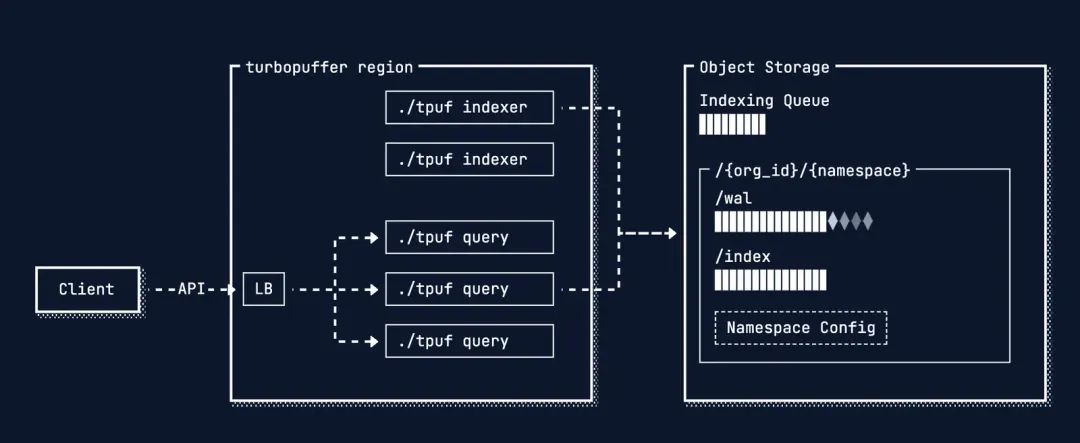
这里使用了典型的生产者-消费者的设计模式
-
write进程把“这里有一批新数据需要被索引”这个任务放入Indexing Queue;
-
indexer进程则从队列中取出任务来执行;
两类进程相互独立工作, 互不干扰, 提升了系统的稳定性和吞吐量。
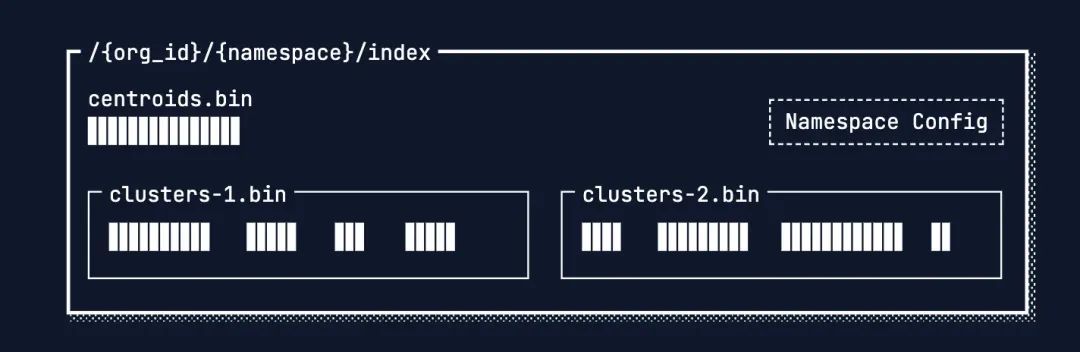
索引的初始化流程如下:
1.聚类
通过聚类算法(如K-Means),将所有向量分成预先设定好的多个簇。
2.计算质心
对于每个“簇”,系统会计算出一个“质心(Centroid)”向量。这个质心是该簇内所有向量的“平均代表”或“几何中心”,最能体现这个簇的整体特征。
3.创建质心索引:
为质心向量单独创建一个小而快的索引文件centroids.bin。这个文件体积小,可以被快速加载和搜索。
4.存储数据块:
同一个簇内的所有原始向量数据,会被物理上存储在一起,形成一个连续的数据块(Data Block),并存放到对象存储中。系统会记录下每个质心对应的数据块在对象存储上的具体位置, 比如说clusters-1.bin的1000-5000字节的数据属于类别1。
turbopuffer使用了SPFresh,它是一个支持就地向量更新的系统,主要解决了传统向量数据库在大规模数据更新时需要全局重建索引导致的高资源消耗、查询性能波动和服务中断问题。通过LIRE增量重平衡协议,只重新分配分区边界的少量向量而非重建整个索引,在十亿级向量规模下,仅需要传统方案1%的内存和不到10%的CPU资源,就能提供稳定的查询性能和24小时不间断的服务,完美契合了基于对象存储的云原生架构需求。
其实现方案超出了我当前的认知水平, 就不在此展开, 感兴趣的同学可以通过"SPFresh: Incremental In-Place Update for Billion-Scale Vector Search"这篇论文学习。
数据检索
冷查询
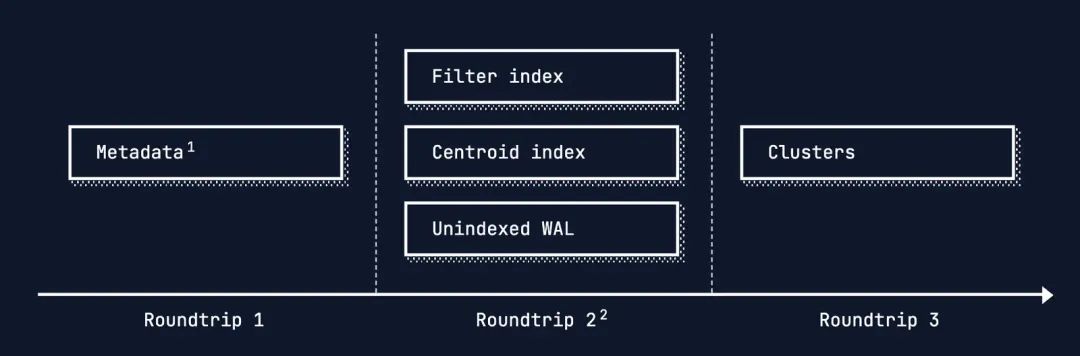
对于用户的一次检索请求, 通常有以下三轮网络交互

缓存策略
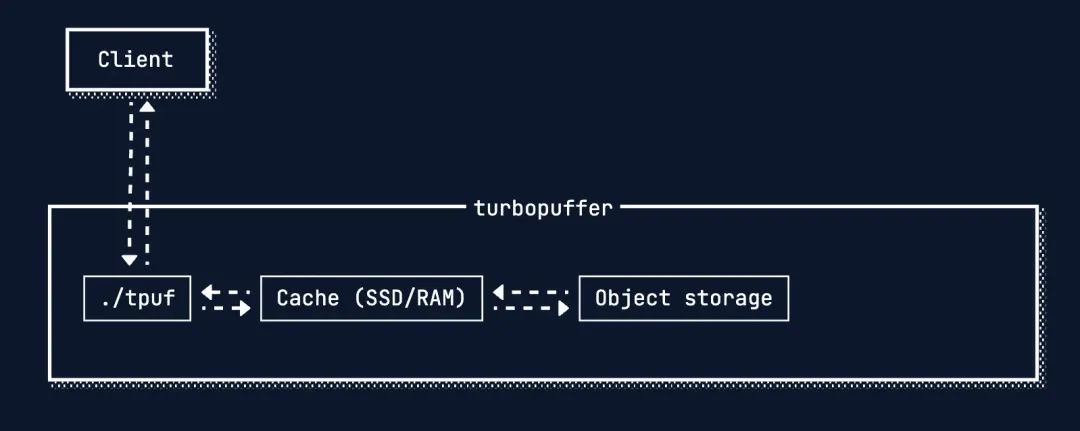
-
首次查询(冷查询):当一个命名空间(namespace)第一次被查询时,系统需要直接从对象存储读取索引数据。这个过程很慢,对于100万文档的规模,中位数延迟(p50)为402毫秒。
-
数据被缓存:首次查询完成后,该命名空间的所有索引数据会被自动加载到查询节点服务器的高速NVMe固态硬盘上。
-
后续查询(热查询):一旦数据被缓存,后续的查询将直接从高速NVMe读取,速度急剧提升。同样的查询,中位数延迟(p50)降至16毫秒,性能提升了约25倍。
-
预热机制
-
官方提供了Warm cache API, 该接口的会立即启动后台的缓存加载任务
-
官方建议在用户登陆或者打开应用时, 调用该接口, 在用户执行止一次查询操作时, 就能够体验极速的响应, 完全感受不到冷启动的延迟。
-
系统会将针对同一个命名空间的后续查询,路由到同一个查询节点(Query Node)上。这确保了请求能够命中该节点上的热缓存。任何一个查询节点都有能力处理任何一个命名空间的查询。如果某个节点发生故障,或者因为负载均衡需要,请求可以被无缝地转移到其他节点上。
总结
turbopuffer是一个云原生向量数据库,专注于提供高性能的向量存储与检索能力。核心功能包括ANN近似最近邻搜索、BM25全文搜索、混合查询和丰富的属性过滤。其技术特点是基于对象存储的存算分离架构,支持命名空间隔离的多租户模式,查询延迟P50仅16ms,写入性能达10,000+向量/秒,并提供强一致性保证。
Cursor在2023年11月迁移到turbopuffer后,实现了20倍成本降低、无限命名空间的无服务器模型,以及峰值1M+写入/秒的高性能表现。turbopuffer通过SPFresh就地更新技术和冷/热缓存机制,完美解决了Cursor代码库向量化和智能代码理解的需求。
更多的疑问
经过前两章知识的补充, 我的理解似乎更加深刻了。
Merkle tree 负责本地变更检测和高效同步,turbopuffer 负责云端的向量存储与检索。
-
首先, 通过使用Merkle Tree, cursor能够快速diff出修改的文件;
-
对于修改的文件, cursor会对文件分chunk, 然后计算出向量;
-
因为cursor在文档中承诺隐私模式下源代码不会上传给第三方, 所以只会传入向量和一些属性字段(行数范围, 加密的路径等)到turbopuffer;
-
turbopuffer异步更新索引;
-
查询时cursor先对查询语句计算向量, 然后调用turbopuffer拿到结果, 拿结果在本地获取具体的代码片段构造上下文, 最后调用大模型服务;
懂得越多, 疑问也变得更多了
-
构造Merkle Tree, 执行diff操作的触发时机是啥? diff之后如何更新向量?
-
cursor如何对文件分chunk? 使用什么模型计算向量的?
-
对于多分支开发的项目, 如何有效避免重复计算?
关于 Cursor 项目的 codebase index, 在网络上能够获取到的原理信息也仅限如此了。真是让人意犹未尽, 有种漂浮在空中的感觉。
换个思路, 何不从开源生态中寻找答案? 毕竟技术的发展往往是相互借鉴的,同类型的产品往往有着相似的设计理念和实现思路。一顿搜寻之后, continue走进了我的视线。
开源方案Continue的启发
产品试用
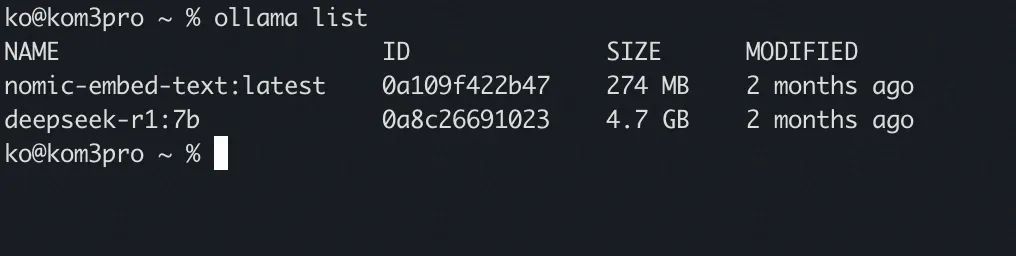
先准备好本地的相关环境, 这里我通过ollama在本地部署deepseek7b和nomic-embed-text。
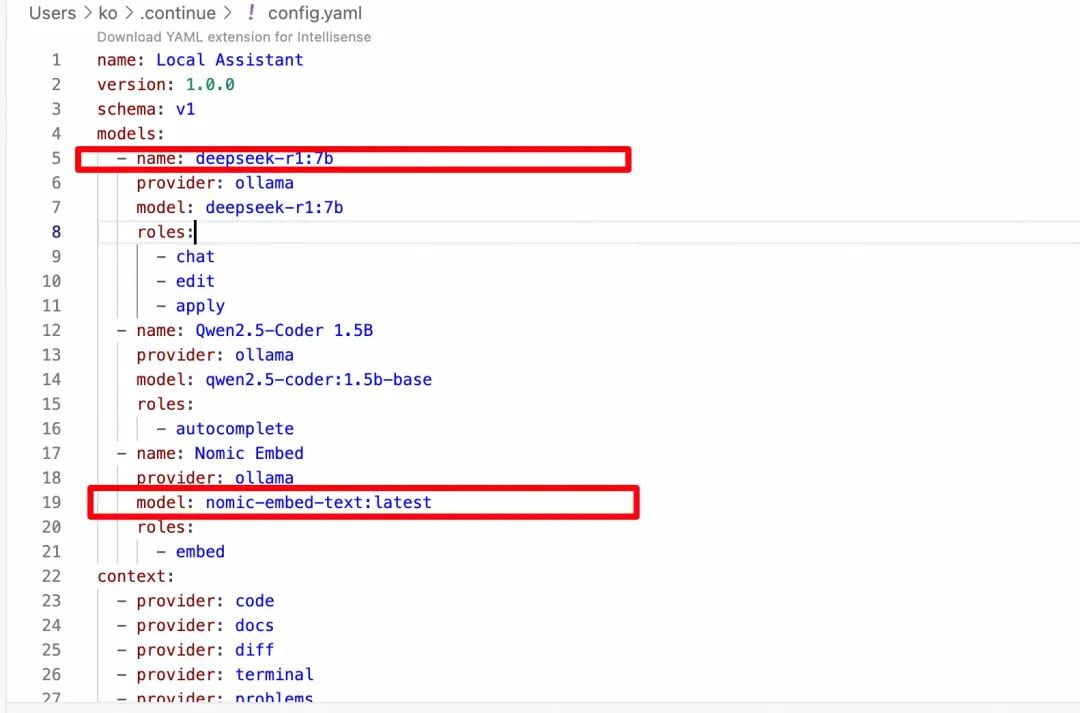
在vscode上安装continue插件并配置好模型:
这里我打开了一个自己的python项目, 可以看到能够正常进行codebase indexing。
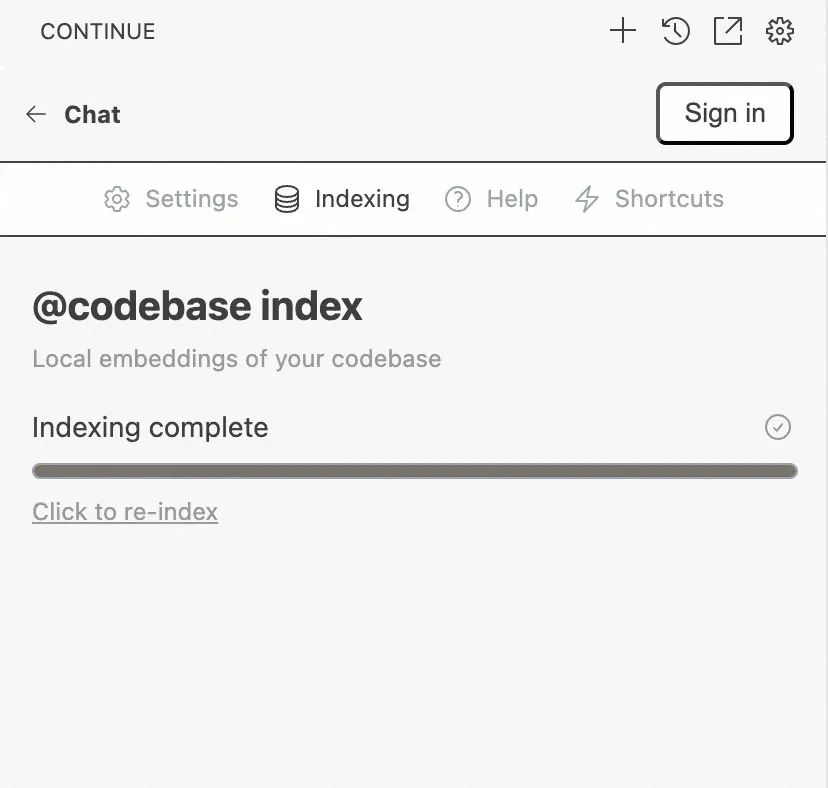
在index complete完成之后可以在对话框中使用@codebase命令, 可以正常从codebase中检索出相似的代码文件。
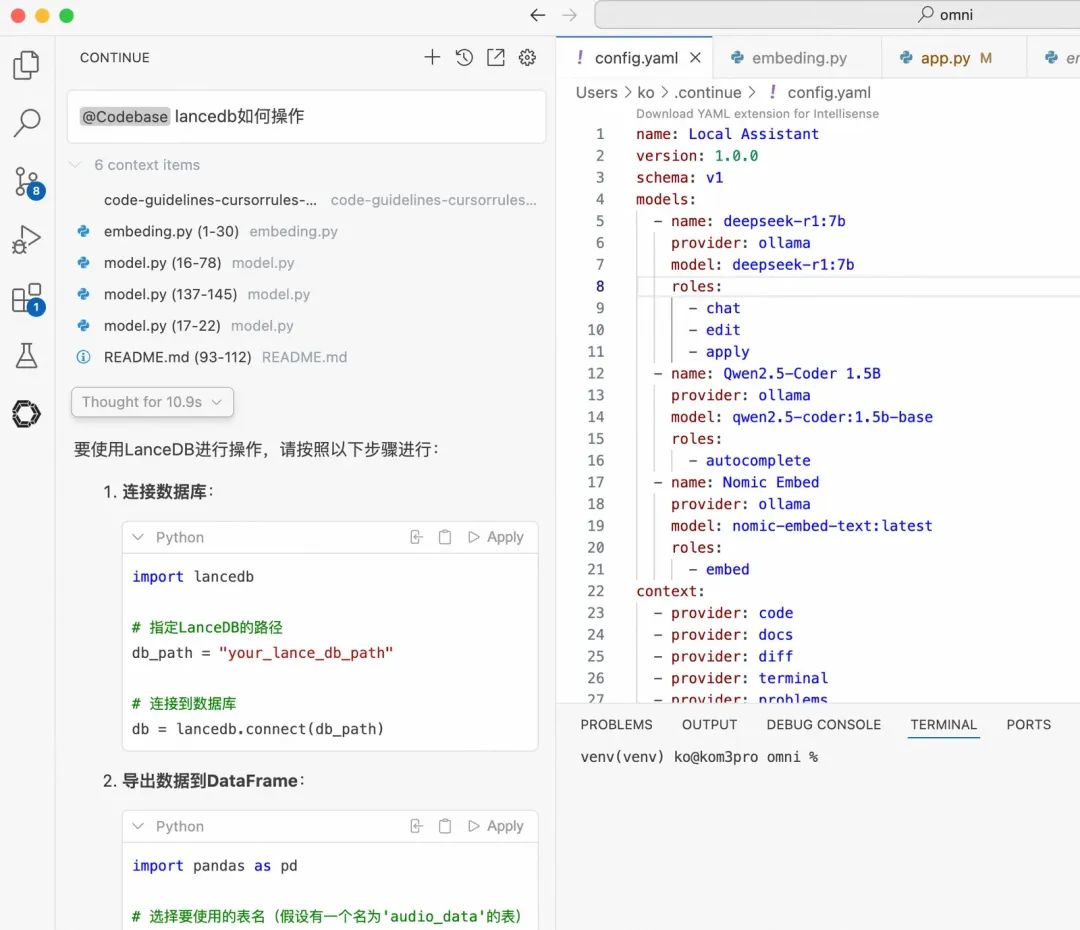
在homs目录下可以看到生成了索引文件夹, 索引相关的内容应该就在这里。
可以看到continue的codebase的交互方式和使用方式与cursor如出一辙, 必须好好研究一下它的实现方式。
探索Index模块
core/indexing目录是我们需要关注的代码实现, 它们负责文件变更检测、索引构建、全文检索、分块处理等功能。
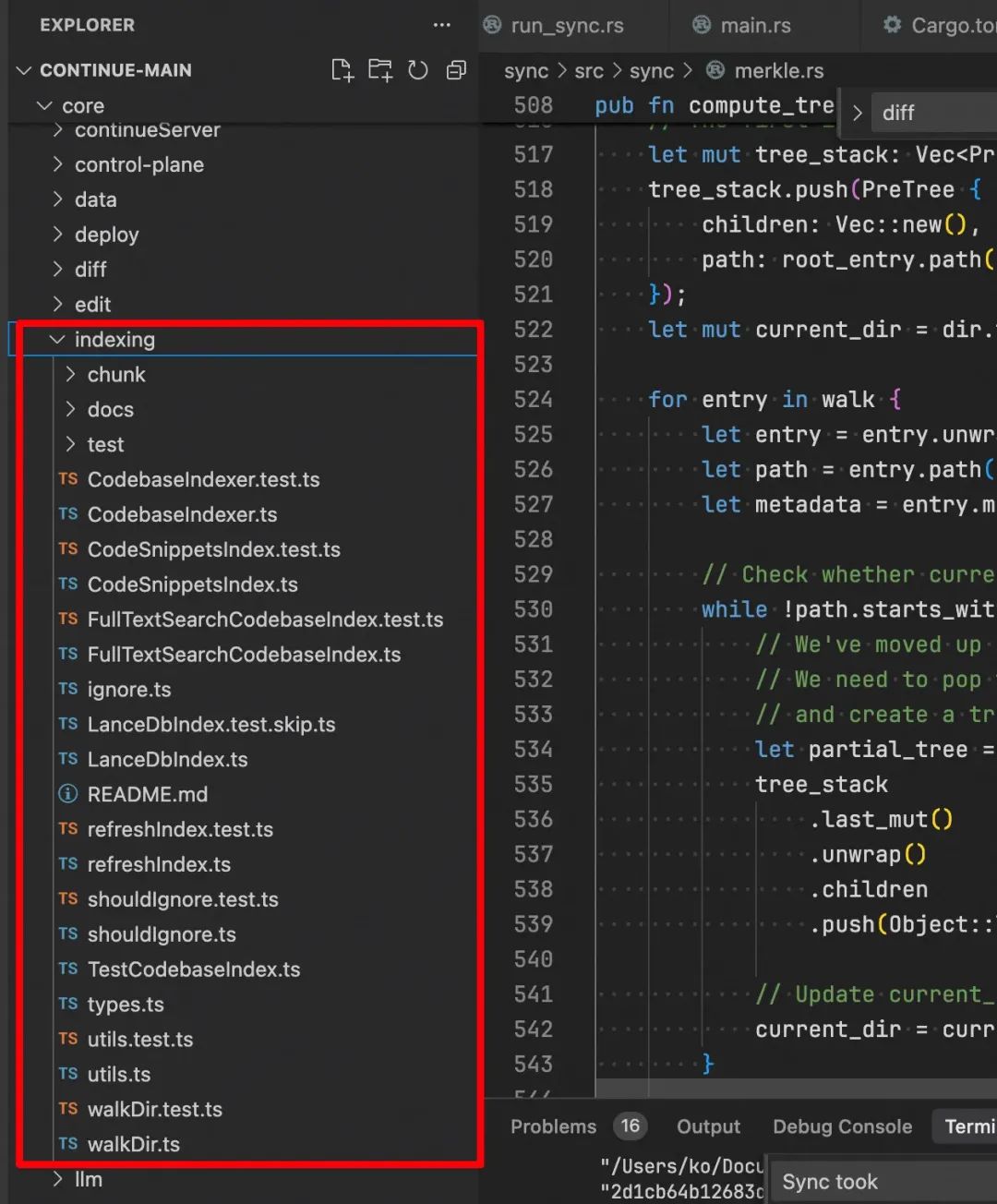
首先阅读README.md, 从中可以得到以下关键信息
-
continue使用的是标签系统(tagging system)来确保相同的文件内容不会被计算多次;
-
对文件内容的哈希结果称为cacheKey, 用于判断文件是否相同;
完整索引流程
1.检查所有文件的修改时间戳(mtime),快速判断文件是否变更。
2.与本地 SQLite 快照数据对比,分出“新增、删除、需更新”的文件。
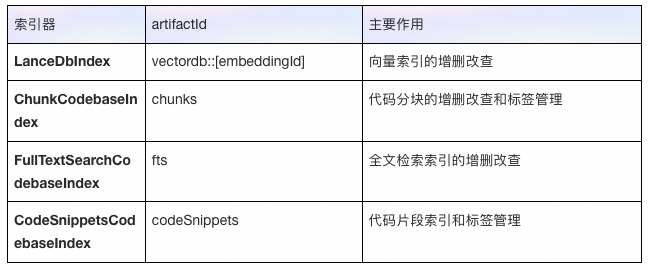
3.对于这些文件, 将其分成四类文件列表(compute、delete、addTag、removeTag)
4.将文件列表交给索引器( CodeSnippets、FullTextSearch、Chunk、LanceDb)统一处理。
默认包含以下四种索引器
我们的分析将聚焦在continue如何对整个代码库计算向量并存储到向量数据库里, 这个过程涉及到的核心代码文件如下:

事件驱动的索引更新
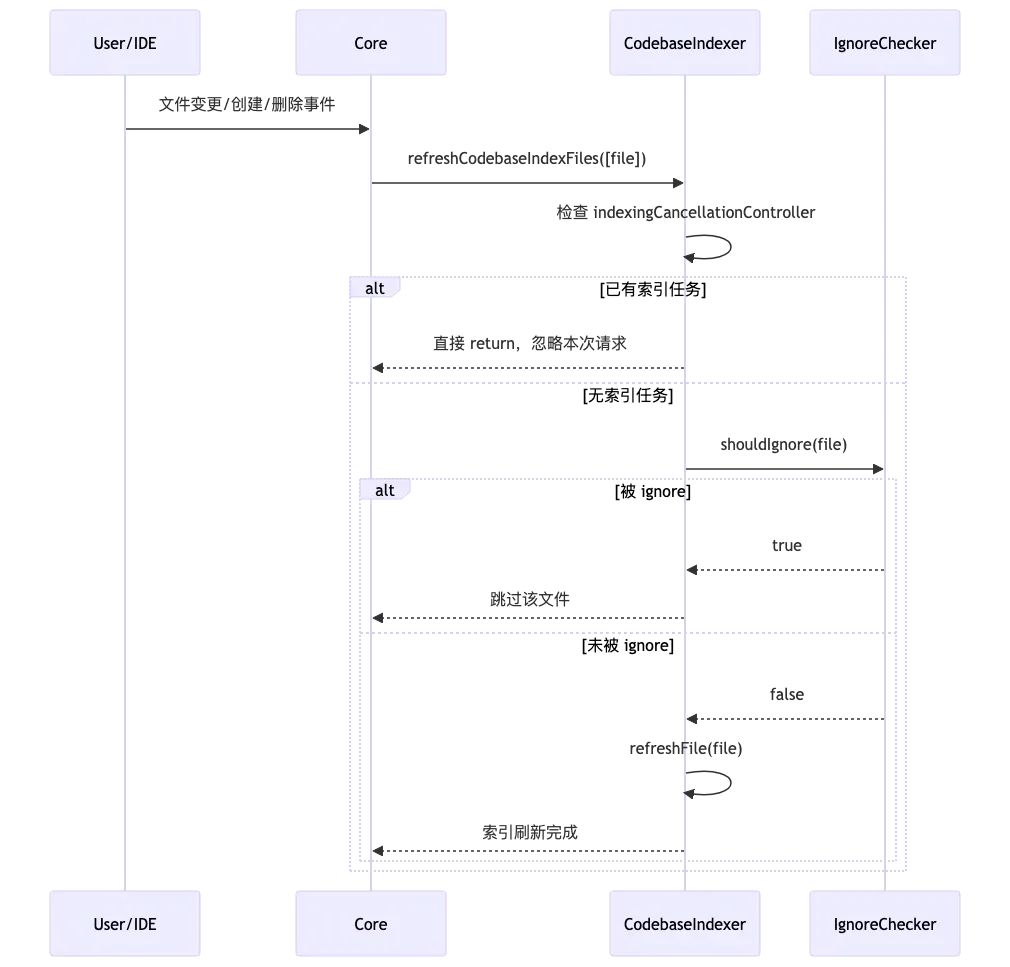
事件触发
-
用户主动点击重建索引按钮全量重建
-
文件创建、修改、删除时自动增量更新
-
分支切换、忽略文件变更时全量重建
-
事件监听器会收集变动的文件路径,准备进行索引刷新。
全局锁
-
在 refreshCodebaseIndexFiles 内部,首先检查 indexingCancellationController(全局唯一)。
-
如果当前已有索引任务在进行,则新请求会被直接忽略,不会并发执行,保证索引操作串行化。
ignore 过滤
-
对每个待处理文件,调用 shouldIgnore判断是否应被忽略。
-
只有未被 ignore 的文件才会进入后续索引流程。
refreshFile
-
通过refreshFile,对每个需要索引的文件进行实际的索引刷新。
索引刷新的具体过程
更新文件索引的核心流程在core/indexing/CodebaseIndexer.ts的refreshFile方法中。
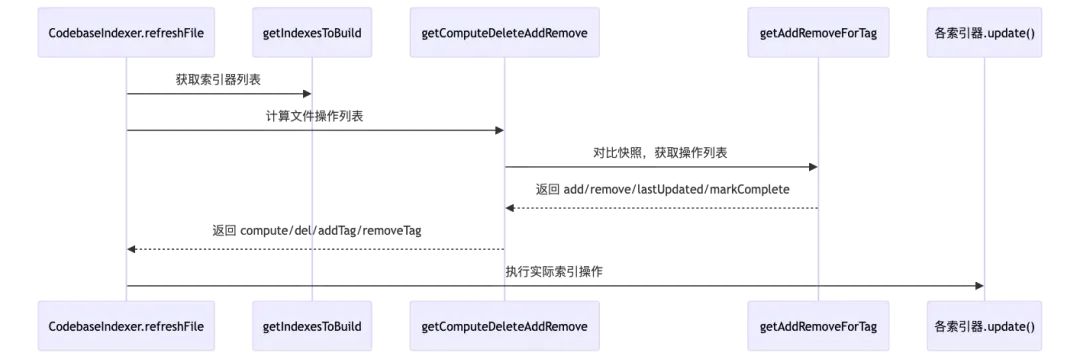
为代码库创建索引有三个核心步骤, 下面将深入进行分析。
步骤1: getAddRemoveForTag
该方法的主要作用是和本地DB里的tag_catalog表做比较, 生成初步的操作列表。
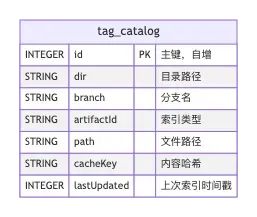
以下是tag_catalog的数据示例
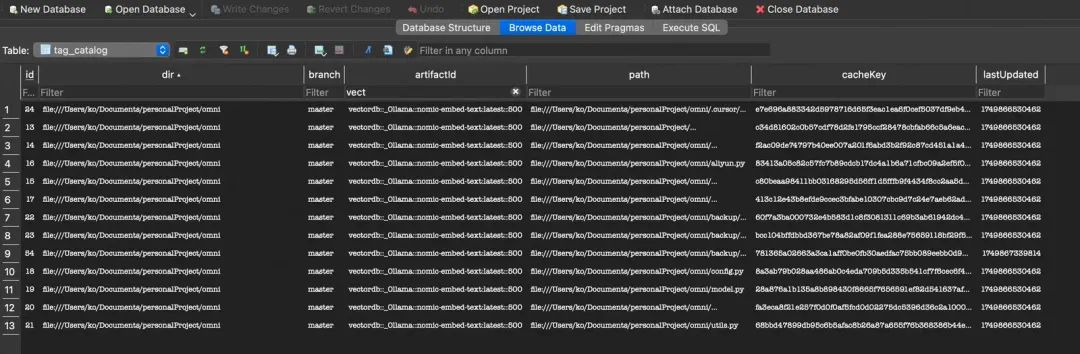
tag = dir + branch + artifactId
tag_catalog 是 Continue 索引系统的核心快照表,用于记录每个分支/目录/索引类型下,已被索引文件的快照信息。
它保证了多分支、多目录、多种索引类型下的索引状态独立且可追踪,是判断文件是否需要重新索引的关键依据。
其具体的执行逻辑如下图
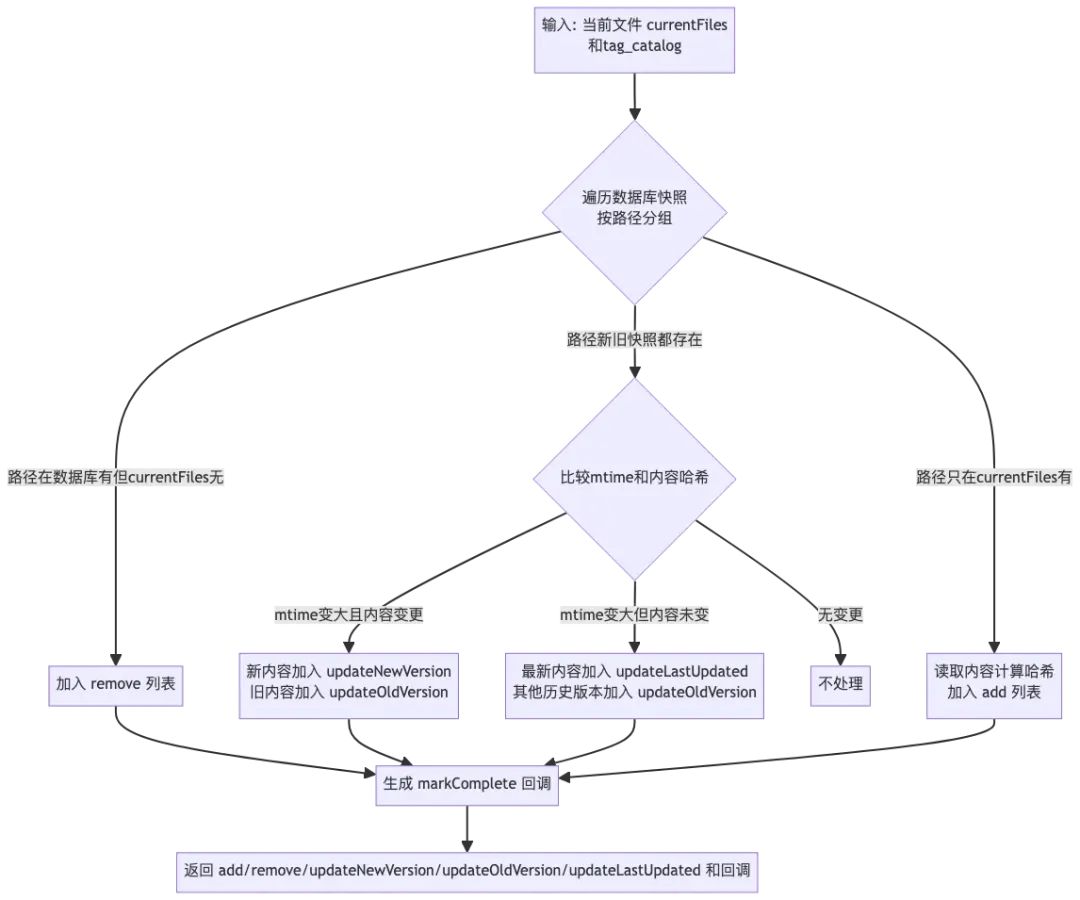
其中markComplete回调会在最后的索引执行器里执行。
步骤2: getComputeDeleteAddRemove
该方法的主要作用是结合上一步返回的结果和本地DB里的global_cache表做比较, 生成最终的操作列表。
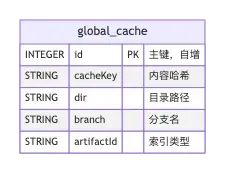
以下是global_cache的数据示例:
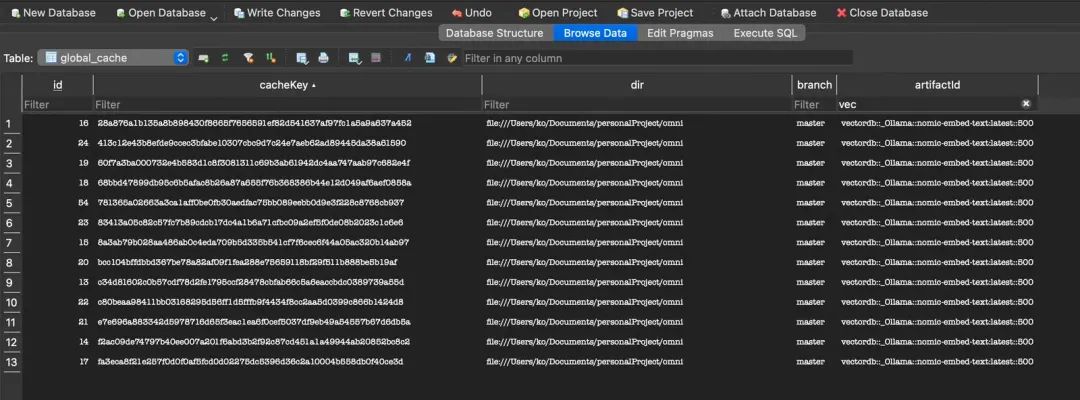
global_cache是内容(cacheKey)维度的数据, 记录的是唯一内容在哪些分支、目录、索引类型下被引用
-
同样内容在不同分支/目录/索引类型下只需索引一次,其他地方只需“打标签”即可
-
在删除文件或切换分支时,判断某内容是否还能被其他分支/目录引用,决定是彻底删除还是仅移除标签。
其具体的执行逻辑如下图
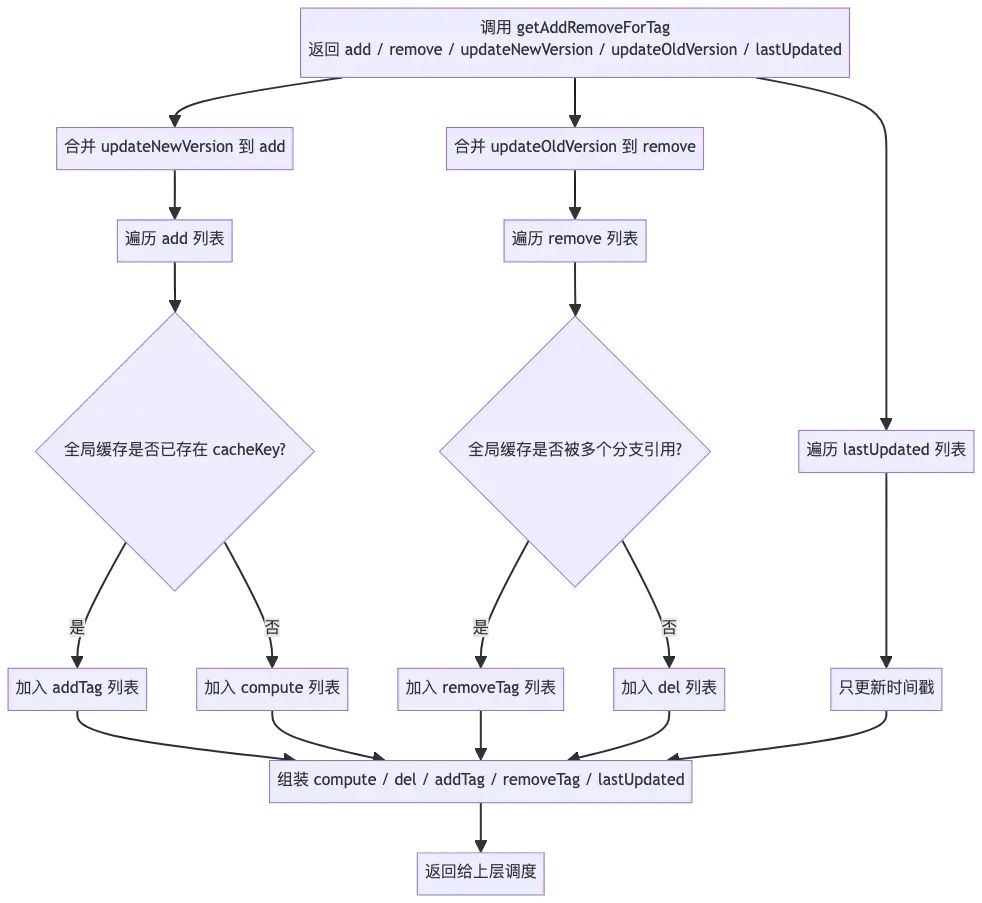
步骤3: 索引器执行udpate
该方法的主要作用是基于上一步返回的最终操作列表, 结合本地DB里的lance_db_cache表, 调用索引器执行索引相关的操作
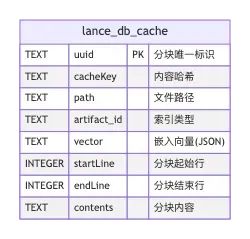
以下是lance_db_cache的数据示例
lance_db_cache 记录每个代码分块(chunk)的详细信息,包括唯一标识(uuid)、内容哈希、所属文件、分块范围、具体内容、向量值等。
-
作为 LanceDB 向量数据库的本地缓存,支持高效的分块检索、标签管理和分块级别的增删改查。
-
支持多分支、多目录、多索引类型下的分块数据管理,便于分块的复用与去重。
-
为语义检索、相似度搜索等 AI 功能提供底层数据支撑。
以下是索引器LanceDbIndex针对步骤2返回的操作列表执行的具体操作。
可以看到针对不同的操作类型, 会对DB和向量数据执行不同的操作。
|
操作类型 |
意义说明 |
处理方式 |
lanceDB |
lance_db_cache |
markComplete(tag_catalog) |
markComplete (global_cache) |
|
compute |
新内容或内容变更,需要真正生成向量 |
读取文件内容,分块,生成向量 |
insert |
insert |
upsert |
upsert |
|
del |
内容彻底无用,需完全移除索引和缓存 |
删除相关数据及缓存 |
delete |
delete |
delete |
delete |
|
addTag |
内容已存在,只需为当前分支/目录/索引类型“挂名” |
拷贝向量, 插入缓存 |
copy |
insert |
upsert |
upsert |
|
removeTag |
只移除当前分支/目录/索引类型的标签,不删内容本身 |
删除该分支向量 |
delete |
不操作 |
delete |
delete |
|
lastUpdated |
内容未变,仅更新时间戳,保持快照与文件系统一致 |
只更新lastUpdated 字段 |
不操作 |
不操作 |
update lastUpdated |
不操作 |
注意:lanceDB的分表规则为dir + branch + artifactId, 即在不同分支的同一文件, 会有多个copy的向量数据。
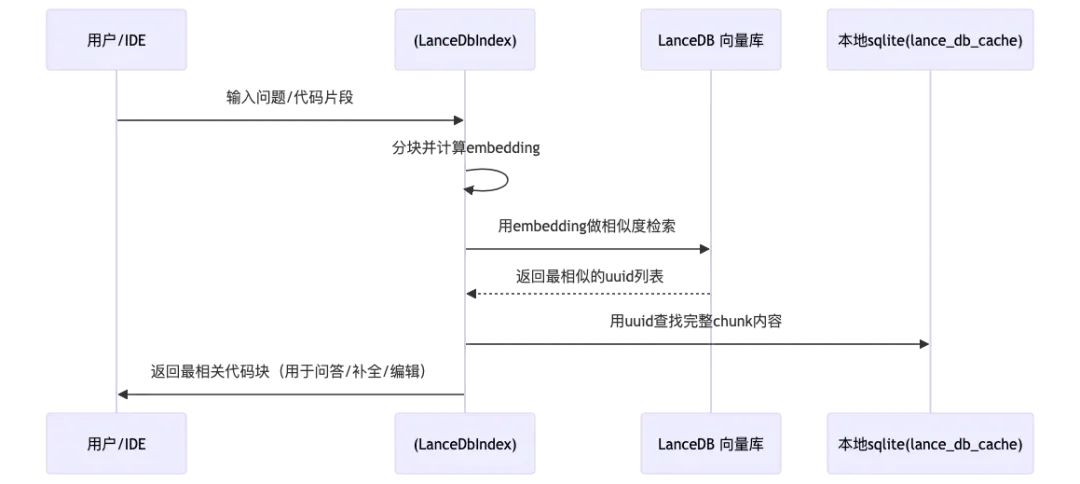
向量检索过程
前面讲了对代码库创建向量并写入向量库的过程, 这里顺便看下retrieve的流程, 这里就相对简单多了。
小结
天塌了, continue在对codebase进行indexing时并没有使用Merkle tree !
但这次探索也并非毫无价值, continue的实现也是一种新思路。
但是掌握一个新的解决方案, 也不是一件坏事, 对其进行简单的总结。
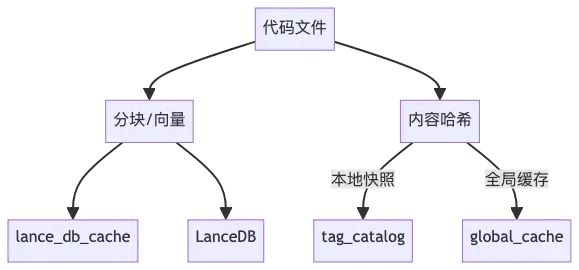
-
代码文件被分块、生成向量,写入 lance_db_cache 和 LanceDB
-
文件内容哈希被记录到 tag_catalog(本地快照)和 global_cache(全局缓存)。
用更通俗的方式来解释这三个DB模型:
tag_catalog:
分支维度的完整文件快照, 每个分支下的每个文件都有唯一一条记录, 用于和当前的文件做比较, 判断文件的操作类型(新增, 删除, 修改), 无论什么操作, 该记录都会被更新.
global_cache:
表示某个文件内容当前在哪个分支已经有向量, 是一个全局的缓存, 主要在多分支场景下避免重复计算
lance_db_cache:
向量库内容的DB缓存, 与向量库的内容一致, 在多分支场景可以拷贝向量, 避免重复计算, 同时在检索场景反查出chunk的内容.
该种技术方案具有如下的优点:
-
只需对比内容哈希和时间戳即可精准判断哪些文件需要重新索引,极大提升索引效率;
-
通过全局缓存, 减少多分支场景下向量计算量;
-
支持多种索引器, 并可进行扩展;
-
索引操作可追踪, 可恢复, 保证一致性;
缺点:
-
依赖文件系统事件触发索引刷新, 容易漏检;
-
目录结构调整需要全部重新计算;
-
没有实现chunk维度的复用(如果一个大文件, 只是在最后追加了一行代码, 按照现在的compute流程, 会将文件拆分成多个chunk, 分别计算向量存储, 而实际只需要对最后一个chunk重新计算即可);
来自Sync的意外之喜
准备转头研究其他开源AI插件的我突然发现, continue源码里有一个基于rust实现的sync模块, 而该模块使用了Merkle tree来做代码库检测!
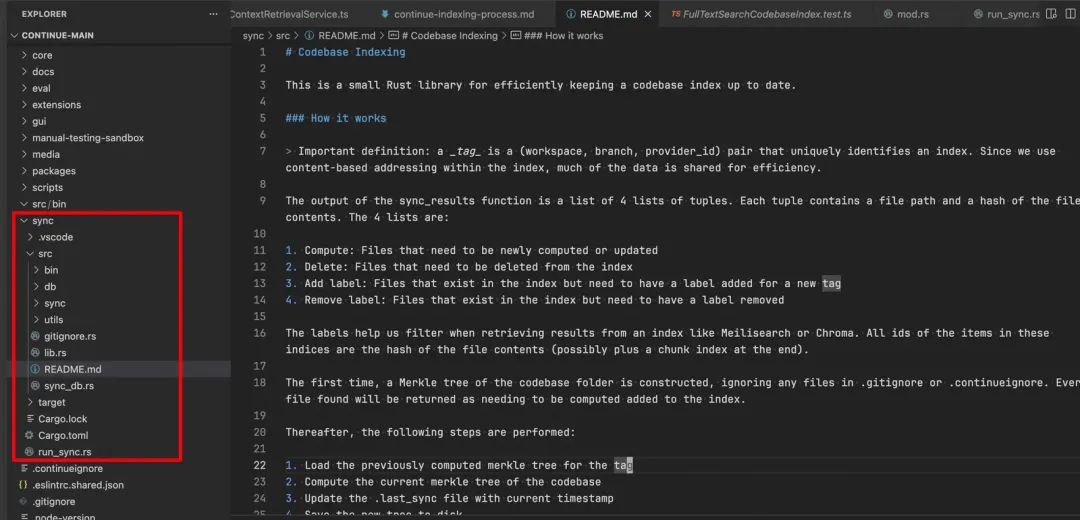
首先阅读README.md, 从中可以得到以下关键信息
-
该模块的核心目标是高效地保持代码库索引的最新状态。它主要用于检测代码库的变更,并输出需要更新索引的文件列表,适合做增量索引和内容去重。
-
输出的文件列表是4 个列表,每个元组包含文件路径和内容哈希。4 个列表分别是:compute, delete, add label, remove label。
回忆前文提到的index模块下的getComputeDeleteAddRemove生成的文件列表compute / del / addTag / removeTag, 这里sync方法输出的文件列表compute/delete/add label/remove label, 这不是能一一对应上么?
本地试运行
由于这个模块在continue的vscode和idea插件中均没有被使用, 我安装了rust环境, 并生成了test方法, 对我的python项目执行了sync同步操作。
在第一次执行, 所有的文件都在compute里, 符合预期。
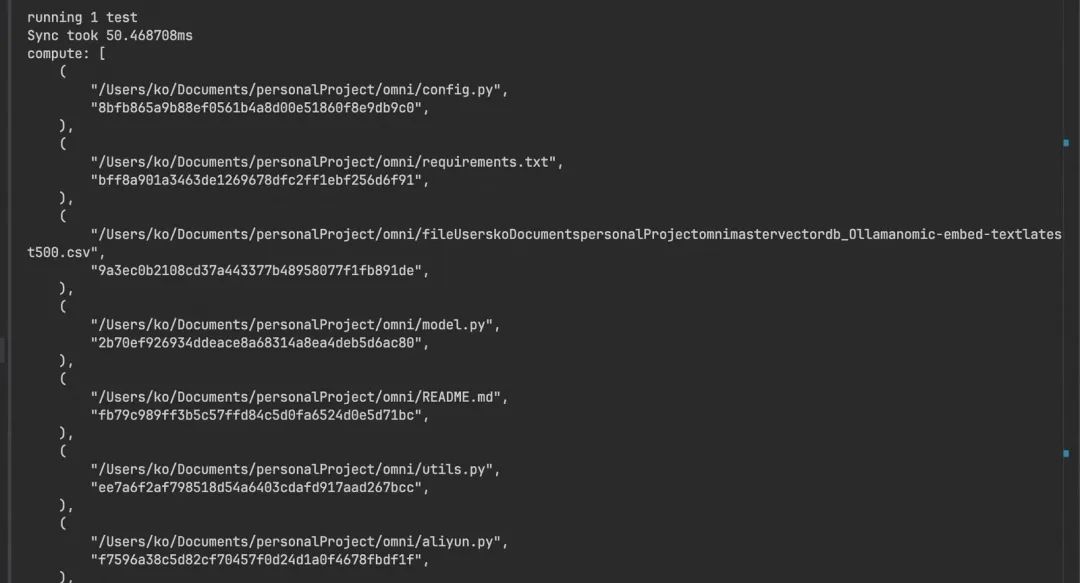

index索引文件中增加了tags文件夹

merkle_tree文件就是一个json格式的树结构
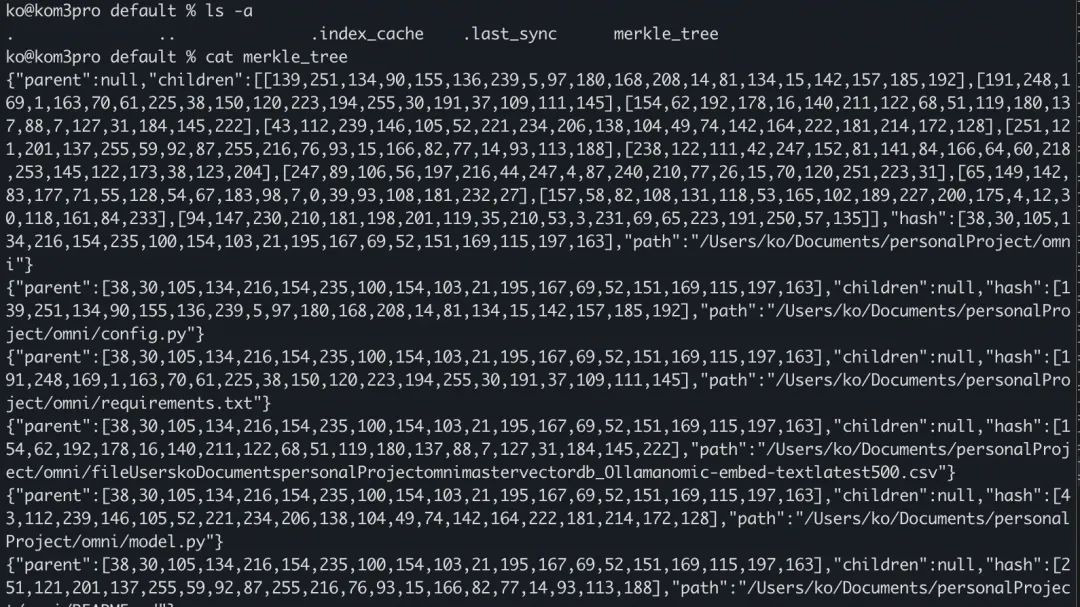
在修改一个文件之后, 再次执行sync, 可以看到compute和delete列表各输出了一个文件。
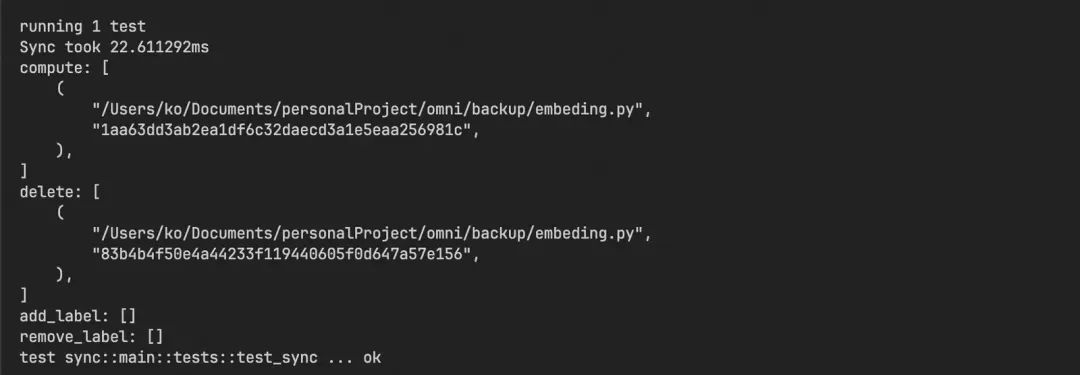
有了前文探索index模块的基础之后, 我们不难猜测, 这里实际用二进制文件代替了index模块里的DB缓存数据, 通过Merkle Tree计算出修改的文件, 再结合二进制文件来决策最后应该是计算/删除向量, 还是只是修改标签。
核心流程
为了便于理解, 这里首先对生成的文件进行说明(tag = dir + branch + artifactId)
|
文件 |
数据格式 |
作用说明 |
|
merkle_tree文件 |
JSONL,每行一个节点(含hash、path、parent、children) |
记录上次同步时的 Merkle Tree 结构,用于变更检测 |
|
.index_cache文件 |
二进制,每20字节为一个内容哈希 |
当前 tag 下已索引内容的哈希集合,实现内容去重和增量索引 |
|
~/.continue/index/.index_cache文件 |
二进制,每20字节为一个内容哈希 |
全局内容哈希集合,所有 tag 共享,进一步去重 |
|
.last_sync文件 |
文本,UNIX 时间戳 |
记录上次同步的时间戳 |
|
rev_tags目录 |
JSON,hash->tag数组 |
内含若干JSON文件, 内容哈希到 tag 列表的映射,追踪每个内容被哪些 tag 引用,实现多标签复用和引用计数 |
不难理解, sync方案里的文件和index方案里的3个DB模型是能够映射上的。
|
sync方案 |
index方案 |
|
tag下的index_cache |
tag_catalog |
|
全局index_cache |
global_cache |
|
rev_tags |
global_cache |
再阅读以下根据源码分析的核心执行流程, 理解起来就不那么困难了。
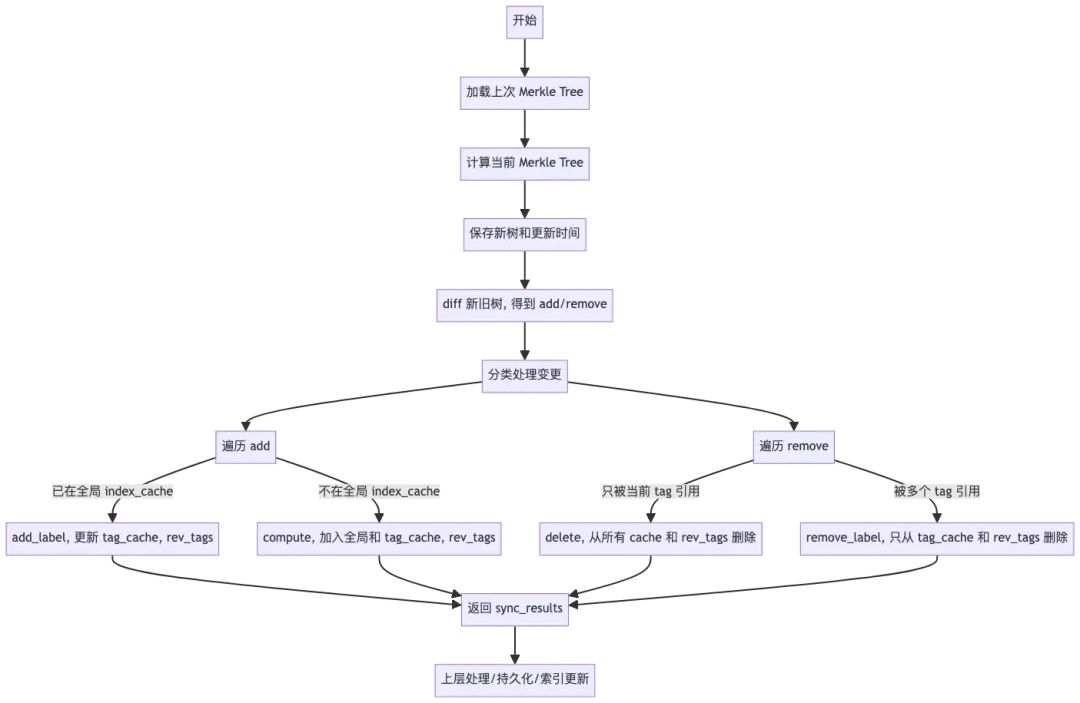
在拿到返回值之后, 按照sync方案的套路, 我们只需要对向量数据进行更新即可实现codebase index的维护。
总结与展望
从最初对Cursor代码库索引机制的好奇心出发,我从官方文档/论坛着手 → 了解Merkle tree原理 → 理解turbopuffer架构 → 剖析Continue开源实现. 这条路走下来, 学习了很多平常的工作接触不到的知识, 技术视野得到了拓展. 但由于个人精力有限, 还是有很多问题, 没有来得及去探索, 比如:
-
Cursor如何进行代码分块?使用什么模型计算向量?
-
其他AI插件是如何进行代码索引的?
-
turbopuffer底层依赖的SPFresh究竟是个啥?
-
Continue除了LanceDbIndex, 剩下的3个索引器承担了什么职责?
只能说学无止境, 总会有新的问题出现, 等待我们去学习研究。
在本次探索过程中, cursor不仅是我的研究对象, 也是我的得力助手, 帮助我总结文档资料, 编写python示例, 理解开源代码, 搭建运行环境, 优化文章表达. 原本需要花费大量时间的工作, AI助手帮我高效完成,真正放大了我的学习能力。
最后,衷心感谢组织提供的宝贵学习机会,鼓励我们主动接触和探索AI技术,营造积极的学习氛围。
大模型风口已至:月薪30K+的AI岗正在批量诞生
2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

如何学习大模型 AI ?
🔥AI取代的不是人类,而是不会用AI的人!麦肯锡最新报告显示:掌握AI工具的从业者生产效率提升47%,薪资溢价达34%!🚀
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)





第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
* 大模型 AI 能干什么?
* 大模型是怎样获得「智能」的?
* 用好 AI 的核心心法
* 大模型应用业务架构
* 大模型应用技术架构
* 代码示例:向 GPT-3.5 灌入新知识
* 提示工程的意义和核心思想
* Prompt 典型构成
* 指令调优方法论
* 思维链和思维树
* Prompt 攻击和防范
* …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
* 为什么要做 RAG
* 搭建一个简单的 ChatPDF
* 检索的基础概念
* 什么是向量表示(Embeddings)
* 向量数据库与向量检索
* 基于向量检索的 RAG
* 搭建 RAG 系统的扩展知识
* 混合检索与 RAG-Fusion 简介
* 向量模型本地部署
* …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
* 为什么要做 RAG
* 什么是模型
* 什么是模型训练
* 求解器 & 损失函数简介
* 小实验2:手写一个简单的神经网络并训练它
* 什么是训练/预训练/微调/轻量化微调
* Transformer结构简介
* 轻量化微调
* 实验数据集的构建
* …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
* 硬件选型
* 带你了解全球大模型
* 使用国产大模型服务
* 搭建 OpenAI 代理
* 热身:基于阿里云 PAI 部署 Stable Diffusion
* 在本地计算机运行大模型
* 大模型的私有化部署
* 基于 vLLM 部署大模型
* 案例:如何优雅地在阿里云私有部署开源大模型
* 部署一套开源 LLM 项目
* 内容安全
* 互联网信息服务算法备案
* …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 21
21 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)