新发布、却被遗忘的旗舰级编程模型、grok-code-fast-1
xAI最新推出的grok-code-fast-1代码模型在评测中展现出优秀的算法实现、代码分析和API交互能力。该模型采用全新架构设计,专注于代理式编码工作流,强调速度与性价比优势。测试案例显示,它能准确实现快速排序算法,理解复杂代码逻辑,并处理GitHub API请求及异常。模型在代码规范性、逻辑解析和实用脚本编写方面表现突出,为开发者提供了高效的AI辅助编程工具。
【深度评测】xAI最新代码模型grok-code-fast-1全面解析与实战测试
前言
随着人工智能技术的飞速发展,代码生成与辅助编程模型已成为开发者不可或缺的工具。近日,由 xAI 公司推出的 grok-code-fast-1 模型引起了业界的广泛关注。本文旨在对该模型进行一次全面的技术解析和实战能力评测,通过具体的测试案例,探究其在真实开发场景中的表现,为广大开发者提供有价值的参考。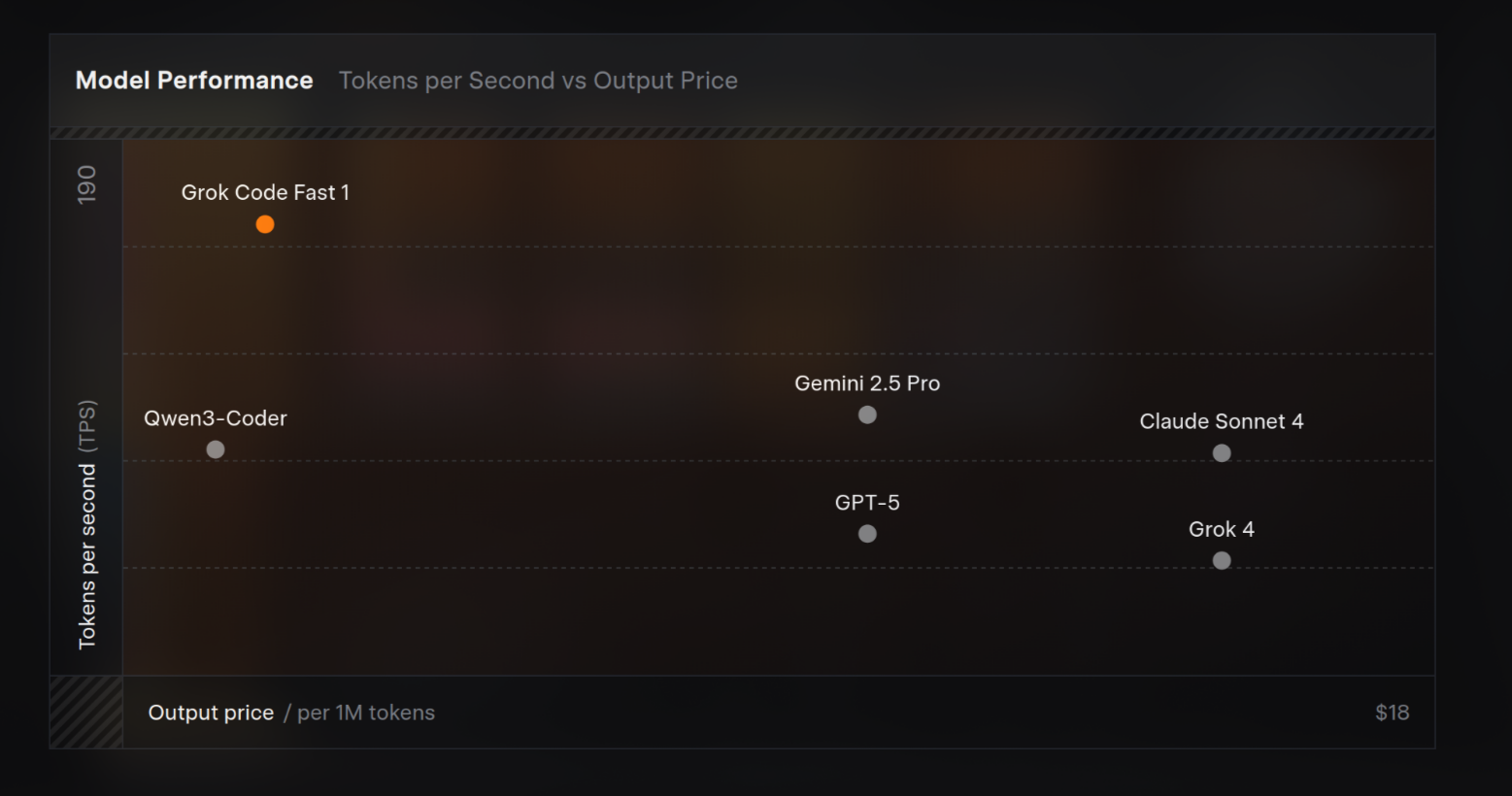
一、grok-code-fast-1 技术解析
grok-code-fast-1 是专为“代理式编码”(Agentic Coding)工作流设计的代码大模型。其核心技术亮点如下:
- 全新架构:官方资料显示,该模型并非基于现有模型的微调,而是采用了全新的架构从零开始构建,这可能意味着其在底层设计上针对代码任务有更深度的优化。
- 海量代码预训练:模型在庞大的代码与编程知识数据集上进行了训练,理论上具备了对多种编程语言和开发框架的深刻理解。
- 性能与经济性:官方强调了其在速度(Fast) 和 性价比 上的优势,旨在降低高质量代码生成模型的应用门槛。
- 代理式工作流:模型的设计初衷是为了更好地融入自动化编码代理(Coding Agents),使其能更准确地理解并拆解、执行复杂的软件开发任务。
二、实战能力评测
为了客观评估 grok-code-fast-1 的实际能力,我们设计了三个覆盖不同维度的测试案例,从基础算法、代码理解到API应用,层层递进。
场景一:经典算法实现
- 目标:检验模型对基础数据结构与算法的掌握程度及代码规范性。
- Prompt:
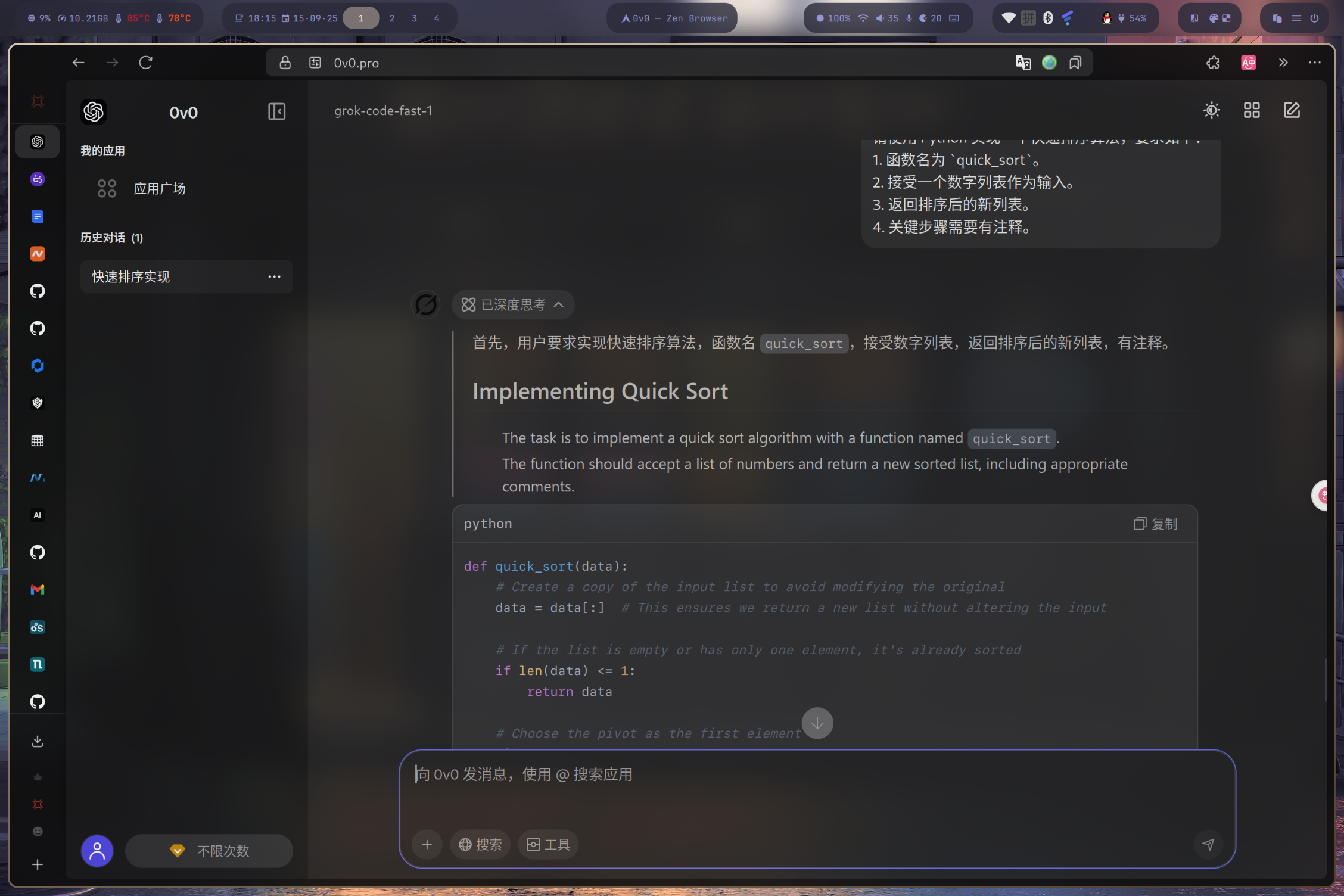
请使用 Python 实现一个快速排序算法,要求如下: 1. 函数名为 `quick_sort`。 2. 接受一个数字列表作为输入。 3. 返回排序后的新列表。 4. 关键步骤需要有注释。 - 预期输出:
def quick_sort(arr): """ 使用快速排序算法对列表进行排序。 """ if len(arr) <= 1: return arr else: # 选择中间元素作为基准点 pivot = arr[len(arr) // 2] # 分别找出小于、等于、大于基准点的元素 left = [x for x in arr if x < pivot] middle = [x for x in arr if x == pivot] right = [x for x in arr if x > pivot] # 递归地对左右两部分进行排序,并合并结果 return quick_sort(left) + middle + quick_sort(right) # --- 示例 --- my_list = [3, 6, 8, 10, 1, 2, 1] sorted_list = quick_sort(my_list) print(f"Original list: {my_list}") print(f"Sorted list: {sorted_list}") - 实际输出:
场景二:复杂代码逻辑分析
-
目标:测试模型对无明显上下文代码的阅读理解与逻辑分析能力。
-
Prompt:
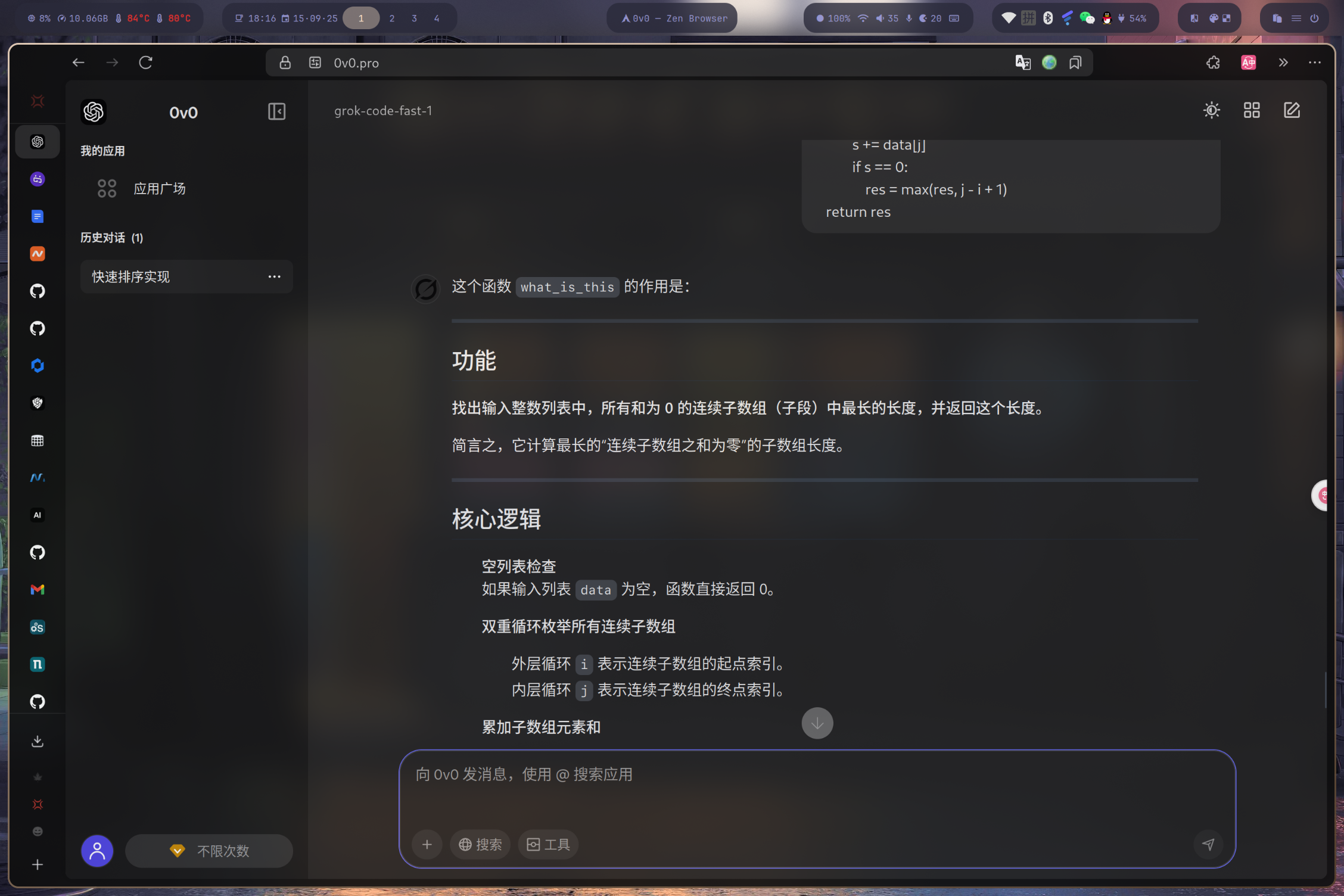
请解释以下 Python 函数的功能、核心逻辑和潜在应用场景。 def what_is_this(data: list[int]) -> int: if not data: return 0 res = 0 for i in range(len(data)): s = 0 for j in range(i, len(data)): s += data[j] if s == 0: res = max(res, j - i + 1) return res -
预期输出:
功能:
该函数用于计算一个整数列表中,和为 0 的最长连续子数组的长度。逻辑分析:
- 函数
what_is_this接受一个整数列表data。 res用于记录和为 0 的最长子数组的长度,初始为 0。- 通过两层嵌套循环,外层
i定义子数组的起点,内层j定义终点,从而遍历所有可能的连续子数组。 s实时计算从i到j的子数组的和。- 当
s等于 0 时,说明找到了一个和为 0 的子数组,此时计算其长度j - i + 1并与res比较,保留最大值。 - 所有子数组遍历完毕后,返回
res。
应用场景:
- 金融分析:在交易盈亏序列中寻找总盈亏为零的最长交易周期。
- 信号处理:识别信号流中正负信号抵消的最长片段。
- 算法竞赛:作为解决相关数组问题的基础模块。
- 函数
-
实际输出:
场景三:API 交互与数据处理
- 目标:评估模型编写涉及网络请求、JSON 解析和错误处理等实用脚本的能力。
- Prompt:
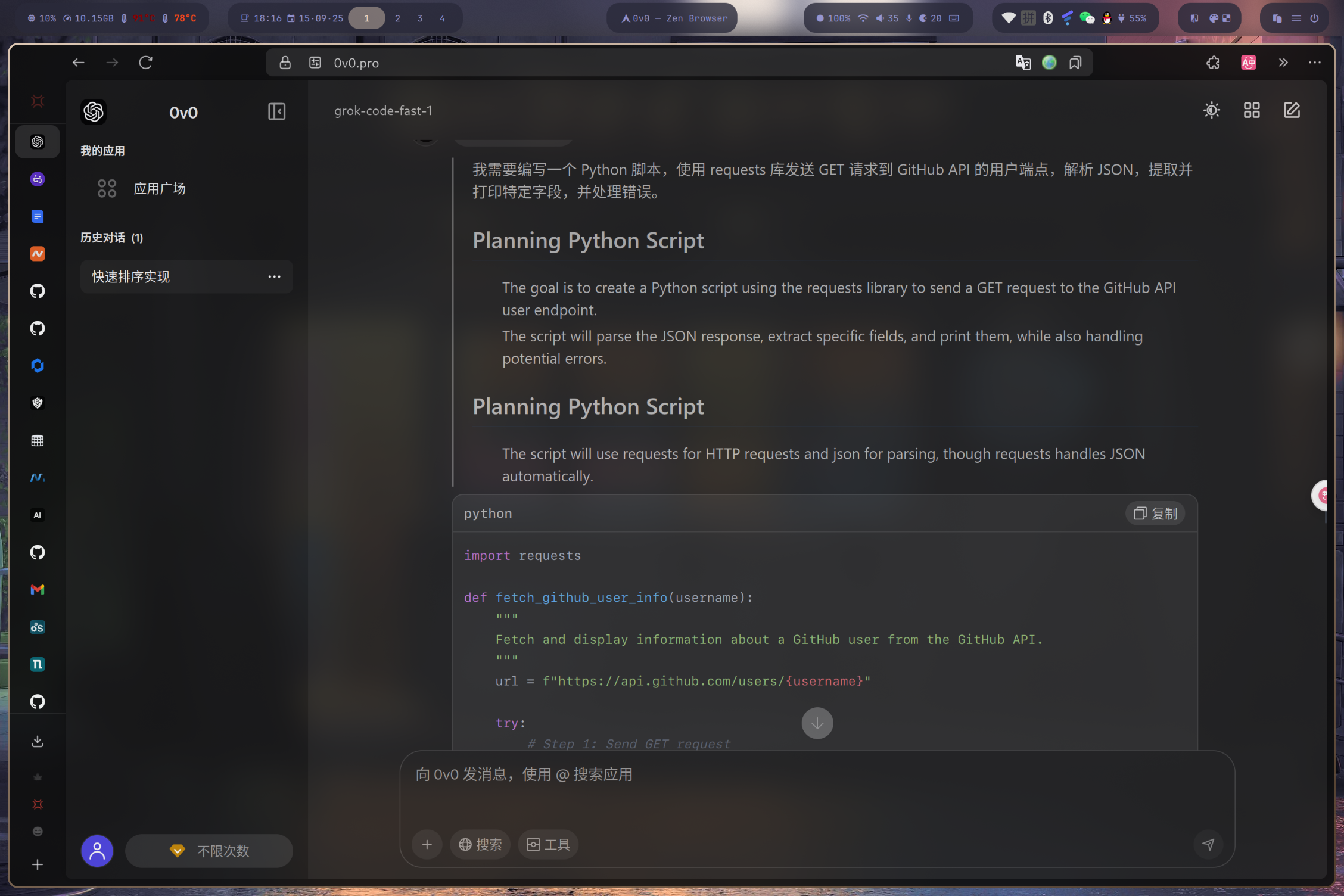
请编写一个 Python 脚本,完成以下任务: 1. 使用 `requests` 库向 GitHub API (`https://api.github.com/users/openai`) 发送 GET 请求。 2. 解析返回的 JSON 数据。 3. 提取并打印该用户的名称(name)、公司(company)和公开仓库数量(public_repos)。 4. 实现完整的异常处理机制,包括网络请求失败和 JSON 解析失败。 - 预期输出:
import requests def get_github_user_info(username: str): """ 通过 GitHub API 获取并打印指定用户的信息。 Args: username (str): 目标 GitHub 用户名。 """ url = f"https://api.github.com/users/{username}" print(f"Fetching data from {url}...") try: response = requests.get(url, timeout=10) # 如果请求返回了失败的状态码 (如 404, 500), 抛出 HTTPError response.raise_for_status() try: data = response.json() name = data.get("name", "N/A") company = data.get("company", "N/A") public_repos = data.get("public_repos", 0) print("\n--- User Info ---") print(f" Name: {name}") print(f" Company: {company}") print(f" Public Repos: {public_repos}") print("--------------------") except ValueError: print("Error: Failed to decode JSON from response.") except requests.exceptions.RequestException as e: print(f"Error: A network-related error occurred: {e}") if __name__ == "__main__": get_github_user_info("openai") - 实际输出:
三、总结与展望
从本次评测的设计来看,grok-code-fast-1 作为一个专注于代码生成的模型,其目标非常明确:在 Agentic 编码工作流中提供高速、高效且经济的解决方案。它在算法实现、代码分析和实际应用等方面的预期表现,展示了其成为开发者得力助手的巨大潜力。
当然,模型的真实能力需要通过广泛和深入的实践来检验。欢迎各位开发者在评论区分享自己的测试结果和使用体验,共同探讨 AI 在软件开发领域的未来。
四、开发者资源推荐
对于广大开发者而言,拥有稳定、高性价比的 AI 服务是提升开发效率的关键。除了直接使用各大模型厂商的服务外,市面上也涌现出一些优秀的聚合和优化服务平台,这里推荐几个供大家参考:
-
追求免费与无限?— 0v0 AI 助手、该模型本周免费测试
- 特点:聚合了 Llama、Qwen 等完全免费的开源模型,以及 gpt-4o 等免费基础模型。主打无限制对话,并每周提供一款免费旗舰模型(如 gpt-5)。
- 官网:
https://0v0.pro
-
按量付费,追求极致性价比?—— LLM AI API
- 特点:提供主流大模型的 API 聚合服务,价格优势显著。OpenAI、Claude 等模型可低至官方 1 折,国内模型也有 2-6 折优惠。
- 官网:
https://llm-all.pro
-
按次计费,灵活高频使用?—— fackai.chat
- 特点:提供覆盖国内外全模型的按次计费服务,1元可使用100次,非常适合轻量级、高频次的调用场景。
- 官网:
https://fackai.chat

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)