
鹅厂面试官:“你做了三个月 RAG,召回率多少?“ 我:这篇七万字是我的答案!
有人问:“我最近在学大模型,到处都在说 RAG,这到底是个什么东西?”
有人问:“RAG 和直接用 ChatGPT 有什么区别?”
还有人问:“我们公司说要做一个基于大模型的内部知识库,让我去调研 RAG,我该从哪里开始看?”
这些问题我太熟悉了,因为每一批进入大模型领域的同学,都会在某个时间点突然意识到:RAG 这个词出现得比任何其他技术术语都频繁,但真正能说清楚它是什么、为什么要用它的人,其实并不多。
今天这篇文章就来把这件事讲清楚。
不用任何前置知识,从"大模型为什么需要 RAG"开始讲起,一步一步拆开,讲清楚它解决的是什么问题、核心流程是什么样的、工程上有哪些关键细节。
我们用训练营里面一个具体的场景贯穿全文:某金融保险公司要给内部员工和客服人员做一个知识库问答系统,文档库里有 5000 份保险合同、理赔手册和培训材料,格式涵盖 PDF(含扫描件)、Word、PPT。
这个场景涵盖了 RAG 工程里几乎所有的典型挑战,跟着这个案例走完一遍,你会发现 RAG 既没有想象中神秘,也没有想象中简单。
全文 7 万字,建议先收藏慢慢阅读。

一、什么是 RAG,为什么需要它
1.1 从 LLM 的本质局限说起
在回答"RAG 是什么"之前,先说一个更根本的问题:LLM 为什么不够,为什么需要一个额外的检索系统。
一个大语言模型,不管是 GPT-4、Qwen 还是 Claude,它的知识都来自训练数据。训练数据有截止日期,而且不包含你们公司内部的文档——你的保险合同、你的内部审计规则、你的产品价格表、你昨天更新的合规要求,LLM 一概不知道。
更糟糕的是,LLM 在不知道的时候不会说"我不知道",它会"幻觉"——用听起来合理、措辞流畅的方式编造一个答案。这种幻觉在日常对话里可能无害,但在医疗、金融、法律这类场景里,一个错误但听起来像真的回答,危害比直接说"我不知道"大得多。设想一下:客服人员问"这款重疾险的等待期是多久",系统给出了一个 LLM 凭空编造的数字——客户理解出了偏差,后来出险了却发现在等待期内,纠纷就来了。
LLM 还有第三个问题:它对所有人的回答是一样的,它不知道你们公司的具体产品、具体定价、具体的内部处理规则。一个给全公司员工用的问答系统,必须基于公司自己的知识库,而不是 LLM 的通用知识。
这三个问题——知识截止日期、幻觉、缺乏领域专有知识——就是 RAG 要解决的问题。
1.2 RAG 的核心思路
RAG(Retrieval-Augmented Generation,检索增强生成)的思路非常直观:
生成之前,先检索。
不让 LLM 凭记忆回答,而是先从你的知识库里检索出与问题相关的内容,然后把这些内容连同用户的问题一起发给 LLM,告诉它:“你只能基于我给你的这些资料来回答,不要用你自己的知识。”
这样做的好处:
- 知识可以实时更新:只需要更新知识库,不需要重新训练 LLM
- 幻觉大幅降低:LLM 有了"参考资料",答案有据可查
- 来源可追溯:可以告诉用户答案来自哪份文件的哪个章节
- 成本低:相比 Fine-Tuning,RAG 不需要训练,部署成本可控
RAG 的本质是给 LLM 加了一个"实时记忆":知识库就是外部记忆,检索就是回忆,生成就是用这段记忆来回答问题。
1.3 RAG 的发展阶段:从 Naive RAG 到 Modular RAG
RAG 技术本身也在快速演进,大致可以分成三个阶段,了解这个演进过程对理解为什么现在的工程实现是这样设计的很有帮助。
阶段一:Naive RAG(朴素 RAG,2020-2022)
最简单的实现:切块 → 向量化 → 相似度检索 → 发给 LLM。这个阶段解决了"能不能用"的问题,但工程质量很粗糙:文档解析不认真、Chunk 按固定长度切、只用向量检索、没有精排。效果不稳定,但证明了这条路是走得通的。
阶段二:Advanced RAG(高级 RAG,2022-2023)
开始认真对待每个模块的质量:引入了更好的 Chunk 切分策略(语义切分)、混合检索(向量+关键词)、精排(Rerank 模型)、Query 改写、多路召回等。这是目前大多数生产环境 RAG 系统所处的阶段,也是这篇文章重点讲的阶段。
阶段三:Modular RAG(模块化 RAG,2024 至今)
把 RAG 系统拆解为独立可配置的模块,不同模块可以根据场景选择不同的实现:有的场景需要 GraphRAG(知识图谱),有的需要 Self-RAG(自适应检索),有的需要 Iterative RAG(多轮迭代检索)。模块化让系统可以根据具体业务需求灵活组合。
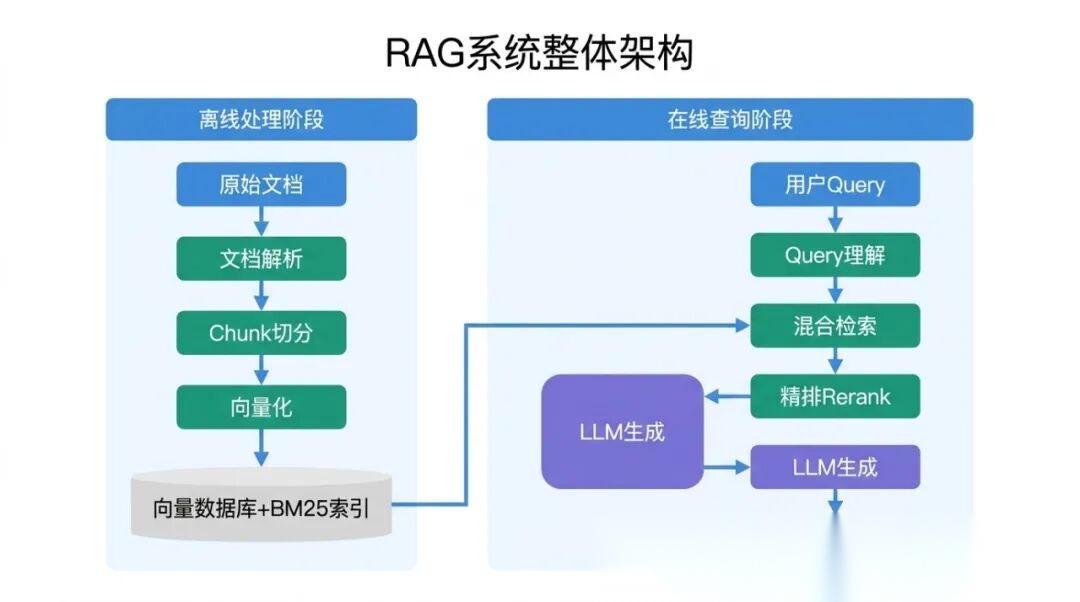
1.4 整体架构:两大阶段、七个核心模块
一个工程级的 RAG 系统分成两大阶段。
离线处理阶段是准备阶段,把原始文档处理成可供检索的格式。这个阶段通常只做一次(或定期更新):
- 文档解析:把 PDF、Word、PPT 的内容提取出来,处理扫描件、表格、多栏排版
- Chunk 切分:把长文档切成适合检索的小段落,保持语义完整性
- 向量化:用 Embedding 模型把每个 Chunk 转换成向量
- 建立双索引:存入向量数据库(Milvus)和全文索引(Elasticsearch)
在线查询阶段是实时响应用户查询:
- Query 理解:分析用户的意图,做指代消解、Query 改写、Query 扩写
- 混合检索:并行运行向量检索和 BM25 检索,RRF 融合,动态权重
- 精排(Rerank):Cross-Encoder 对候选结果精细排序,选出 Top 5-10
- 生成:把 Query 和检索结果组织成 Prompt,LLM 生成最终答案
看起来流程清晰,但每一步里都藏着工程细节。下面一层一层拆开来讲,讲清楚每个模块"为什么这样设计",而不是"能用就行"。
1.5 RAG 与传统搜索的本质区别
工程师在接触 RAG 时,经常会问一个问题:这跟我们已经有的企业内部搜索系统有什么区别?搜索不就是"找文档"吗?
区别是本质性的,理解这个区别,才能理解为什么 RAG 要用 Embedding 而不是直接用搜索引擎。
传统搜索(关键词检索):
用户输入"等待期",搜索引擎找包含"等待期"这个词的文档,按 BM25 算法排序,返回文档列表。用户自己去读文档,找自己想要的信息。
返回的是"文档列表",用户需要自己消化。如果知识分散在 10 份文档的 10 个不同位置,用户要一份一份去翻。
RAG(检索增强生成):
用户输入"等待期内患了重大疾病能赔吗",RAG 系统理解语义,找到最相关的几段内容(可能来自不同文档的不同章节),把这些内容组合起来送给 LLM,LLM 直接给出一个综合性的答案:“根据《XXX保险产品说明书》第3条第2款,等待期内发生的疾病不在保障范围内。等待期通常为90天……但如果是意外伤害(非疾病),则……”
返回的是"答案",不是文档列表,用户不需要自己综合判断。
这个差别对企业知识库用户体验的提升是革命性的——从"我去搜,自己找答案"变成了"我问,它直接告诉我"。
1.6 什么项目适合上 RAG,什么不适合
不是所有问题都适合 RAG,错误地使用 RAG 有时候比不用还糟糕。
适合 RAG 的场景:
- 知识库有明确的边界和权威来源(合同文本、技术文档、法规条文)
- 用户的问题有确定的答案(而不是开放性的创意问题)
- 知识需要频繁更新(新产品上线、条款修改)
- 需要来源可追溯(合规、法律、医疗场景)
- 知识量超过 LLM 上下文窗口(超过几十页)
不适合 RAG 的场景:
- 知识主要是"常识"或通用知识,LLM 本身已经知道
- 问题是创意性的、开放式的("帮我写一首诗"不需要检索)
- 知识库质量极差(文档混乱、格式不一致、内容相互矛盾),"Garbage In"的情况
- 实时性要求极高而知识库更新跟不上(比如股票实时价格)
我们的保险知识库场景,非常典型地属于"适合 RAG"的场景:有 5000 份权威文档、用户问题有确定答案、条款定期更新、合规要求来源可追溯。这让 RAG 的收益非常清晰,实施路径也比较顺。
RAG系统整体架构图:离线处理流程与在线查询流程
二、离线阶段第一关:文档解析,“Garbage In, Garbage Out”
RAG 系统有一句行内话叫"Garbage In, Garbage Out"——输入的内容质量决定了输出的答案质量。而这个"垃圾"问题,大多数时候出在文档解析这个最不起眼的环节。很多人上来就在折腾 Embedding 模型和检索算法,但解析环节的内容是混乱的,后面做多少优化都没有意义。
2.1 五种文档格式各自的坑
我们的保险知识库里,文档类型至少有五种:普通 PDF、扫描版 PDF、Word 文档、PPT、带有大量表格的财务报告和产品说明书。每种格式都有各自的解析挑战。
普通 PDF:多栏排版和页眉页脚污染
很多保险公司的理赔指南用的是双栏排版,页面上左侧是正文,右侧是对应的说明或补充。如果用最简单的按行顺序提取文本,解析结果会把左栏和右栏的内容混在一起:
原始内容(双栏排版示意):
[左栏] [右栏] 第一条 理赔申请流程: 申请人须同时提交以下材料: 一、事故发生后48小时内联系公司 1. 本人身份证复印件 二、提供医院出具的完整诊断证明 2. 保险合同及附件复印件 三、填写索赔申请书并签字确认 3. 医院出具的原始诊断证明 四、等待保险公司三个工作日审核 4. 费用清单及发票原件
按行顺序解析后(错误结果):
第一条 理赔申请流程:申请人须同时提交以下材料: 一、事故发生后48小时内联系公司 1. 本人身份证复印件 二、提供医院出具的完整诊断证明 2. 保险合同及附件复印件 三、填写索赔申请书并签字确认 3. 医院出具的原始诊断证明
这段文本进入向量库之后,语义是完全混乱的。用户问"理赔需要提交哪些材料",检索到这段内容,LLM 面对这一锅粥,给出错误或不完整的答案。
除了多栏排版,普通 PDF 还有页眉页脚污染问题:每页顶部"XXX保险公司 内部资料 严禁外传"和底部"第 X 页/共 Y 页"这类无意义文本,如果不过滤,会混入每个 Chunk,干扰向量检索。
解决方案是做版面分析(Layout Analysis),识别出文档的物理结构——哪些区域是标题、哪些是正文、哪些是左栏、哪些是右栏、哪些是页眉页脚——然后按逻辑顺序重组,并过滤掉无关区域。
实现工具:pdfplumber 做基础文本提取时可以获取每个文字块的坐标,结合坐标信息可以判断多栏结构。更复杂的文档用 layoutparser 或 unstructured.io 做基于深度学习的版面分析。
扫描版 PDF:OCR 准确率、水印、图像质量
保险公司的历史合同大量是扫描件。扫描件没有文本层,必须经过 OCR(光学字符识别)才能提取文字。我们在项目里遇到了三类典型的 OCR 失准场景:
场景一:低分辨率扫描。 老旧合同的扫描分辨率可能只有 150 DPI,字迹模糊,传统 OCR 的识别率从 95% 骤降到 60% 以下。处理方法:用拉普拉斯方差检测图像清晰度,方差低于阈值 100 的识别为低质量扫描件,先做图像预处理(CLAHE 对比度增强、双边滤波降噪、Hough 变换矫正偏斜)再送入 OCR。
场景二:水印和印章叠加。 保险合同上的红色公章、"副本"水印经常与文字重叠。OCR 在这种情况下,会把印章的笔画认成字符,产生大量乱码。
我们的处理方案是训练一个 U-Net 做像素级语义分割:把每个像素分类为"文字区域"或"水印/印章区域",先在图像层面把水印抹掉,再做 OCR。训练数据是人工标注的 200 张带水印保险合同(每张图片标注出水印区域的 mask),训练过程约 3 天(V100 GPU)。优化后 OCR 准确率从 73% 提升到 94%,提升了 21 个百分点。
import torch import torch.nn as nn # U-Net 前向推理:对扫描件图像做水印分割 def remove_watermark(image_array, unet_model, device): """ 输入:原始扫描件图像(numpy array,HxWx3) 输出:去除水印后的图像 """ # 预处理 tensor = preprocess(image_array).unsqueeze(0).to(device) # 推理:输出每个像素属于水印的概率 with torch.no_grad(): watermark_mask = unet_model(tensor).sigmoid().squeeze(0) # 阈值化得到二值mask binary_mask = (watermark_mask > 0.5).cpu().numpy() # 用白色填充水印区域(保险合同背景通常是白色) cleaned = image_array.copy() cleaned[binary_mask] = 255 return cleaned
场景三:表格结构的 OCR 失真。 这是最棘手的问题,后面专门讲。
Word 文档:样式信息的利用
Word 文档(.docx)的结构比 PDF 清晰得多——它有明确的段落标签、标题级别(Heading 1、Heading 2 等)、表格标签。用 python-docx 解析时,可以直接获取这些结构信息:
from docx import Document def parse_docx_with_structure(file_path): doc = Document(file_path) sections = [] current_section = {"level": 0, "title": "", "content": []} for para in doc.paragraphs: style = para.style.name text = para.text.strip() if not text: continue # 识别标题层级 if style.startswith('Heading 1'): # 保存当前section,开始新section if current_section["content"]: sections.append(current_section) current_section = {"level": 1, "title": text, "content": []} elif style.startswith('Heading 2'): if current_section["content"]: sections.append(current_section) current_section = {"level": 2, "title": text, "content": []} else: current_section["content"].append(text) if current_section["content"]: sections.append(current_section) # 处理表格 for table in doc.tables: table_data = extract_table(table) sections.append({"level": 99, "title": "TABLE", "content": table_data}) return sections def extract_table(table): """提取表格,保持行列结构""" rows = [] for row in table.rows: cells = [cell.text.strip() for cell in row.cells] rows.append(cells) return rows
利用 Word 的样式信息,可以直接获得准确的层级结构,这是 PDF 解析需要费力推断的东西。
2.2 表格解析:最难的一关
表格解析是文档解析里最难的问题,值得单独深入讲。保险合同里有大量高价值表格:保费计算表、责任范围表、免赔额对照表、不同年龄段保额表——这些表格里的数字是用户最常查询的内容,但同时也是最难正确解析的内容。
表格分两大类,解析难度天壤之别:
有边框的结构化表格:每个单元格都有明确的边框线,工具容易识别行列结构。用 pdfplumber 或 camelot 可以解析出来,准确率在 80-90%。
无边框的对齐式表格:靠空格对齐,没有边框,对大多数工具来说几乎无解。普通工具识别出来的是一堆没有行列关系的文本,完全丢失了列对齐关系:
原始无边框表格: 年龄 男性保费 女性保费 最高保额 30岁 2,340元 1,980元 500万 40岁 3,560元 2,890元 400万 50岁 5,890元 4,230元 300万 错误解析结果(按行顺序拼接): 年龄 男性保费 女性保费 最高保额 30岁 2,340元 1,980元 500万 40岁 3,560元 2,890元 400万
进了向量库之后,用户问"50岁男性保费是多少",召回这段内容,LLM 面对这一串数字根本无法正确定位。
我们的方案是做了一个前置分类器:用卷积神经网络识别当前页面是否包含无边框表格,如果包含,调用 MinerU(基于 Table Transformer 架构,专门针对无边框表格训练)而不是通用解析工具。
def detect_borderless_table(page_image, classifier_model): """ 判断页面是否包含无边框表格 返回:(has_borderless_table: bool, confidence: float) """ tensor = transform(page_image).unsqueeze(0) with torch.no_grad(): output = classifier_model(tensor) prob = torch.softmax(output, dim=1)[0][1].item() return prob > 0.7, prob def parse_table_smart(page, page_image): has_borderless, conf = detect_borderless_table(page_image, table_classifier) if has_borderless: # 调用MinerU,速度慢但准确 table = mineru_parser.parse(page_image) else: # 调用轻量工具,速度快 table = camelot.read_pdf(page) return table
为什么不全部用 MinerU?MinerU 推理速度慢,单页约 300ms,而通用工具只需要 80ms。5000 份文档,每份平均 20 页,全用 MinerU 要 33 个小时;通过分类器只对约 15% 的特殊 Case 调用 MinerU,总解析时间压缩到约 6 小时,工程上可接受。
表格的存储格式
解析出来的表格,存成什么格式进向量库?有三种方案:
方案一:Markdown 表格格式
| 年龄 | 男性保费 | 女性保费 | 最高保额 | |------|---------|---------|---------| | 30岁 | 2,340元 | 1,980元 | 500万 | | 40岁 | 3,560元 | 2,890元 | 400万 |
优点:结构清晰,LLM 天然能理解 Markdown 表格。缺点:大表格的 Markdown 会很长,超出 Chunk 大小限制时需要分割,而分割 Markdown 表格比较麻烦。
方案二:JSON 格式
{"table_type": "premium_schedule", "headers": ["年龄", "男性保费", "女性保费", "最高保额"], "rows": [ {"年龄": "30岁", "男性保费": "2340", "女性保费": "1980", "最高保额": "5000000"}, {"年龄": "40岁", "男性保费": "3560", "女性保费": "2890", "最高保额": "4000000"} ]}
优点:结构化,方便程序处理。缺点:LLM 对 JSON 的理解没有对自然语言和 Markdown 的理解稳定。
方案三:自然语言描述(Text Serialization)
保费费率表:30岁男性年保费2340元,女性1980元,最高保额500万; 40岁男性年保费3560元,女性2890元,最高保额400万; 50岁男性年保费5890元,女性4230元,最高保额300万。
优点:LLM 处理最稳定,不需要理解表格结构。缺点:丢失了部分结构信息,而且文本比较冗长。
我们的选择是 Markdown 格式,原因是 LLM 对 Markdown 的理解一致性最好,而且 Markdown 格式方便人工审查解析质量。大表格分割时,每个子 Chunk 都带上表头(下一节详细讲)。
2.3 层级结构保留:让检索结果有上下文
解析出来的文本,如果丢失了原始的层级结构,检索质量会大幅下降。
想象这样一个场景:用户问"核辐射在保障范围内吗"。知识库里有两段内容:
段落 A(来自"承保责任"章节):“被保险人在保险期间内因意外伤害、疾病、手术等均在保障范围内……”
段落 B(来自"责任免除"章节的第2条):“以下情况不在保障范围内:(1)战争或武装冲突、(2)核辐射、(3)故意行为……”
如果这两段内容都不携带章节信息,向量检索可能因为段落 A 里有"保障范围"这个关键词而把它排到前面,段落 B 反而排在后面。LLM 看到"在保障范围内……",可能误以为核辐射是赔的,给出错误答案。
正确的做法是在每个 Chunk 上挂载元数据(Metadata),记录它来自哪个文档、哪个章节、哪个子章节:
{ "chunk_id": "contract_2024_001_chunk_042", "doc_id": "contract_2024_001", "doc_name": "XXX保险产品说明书(2024年版)", "doc_type": "insurance_contract", # 文档类型:合同/手册/培训材料 "section_path": "第3条保险责任 > 3.2责任免除 > (2)免责条款", "section_level": 3, "chunk_index": 42, "char_count": 387, "is_key_clause": True, # 是否是关键条款(责任/免责/费率相关) "has_table": False, # 是否包含表格内容 "prev_chunk_id": "contract_2024_001_chunk_041", # 前一个chunk "next_chunk_id": "contract_2024_001_chunk_043", # 后一个chunk "parse_confidence": 0.95, # 解析置信度(OCR文档低于1.0) "update_time": "2024-12-01" # 文档最后更新时间 }
这些元数据在检索时可以做过滤(比如"只检索2024年版合同"),在答案生成后可以给用户展示来源(“根据《XXX保险产品说明书》第3条第2款责任免除……”),在系统评估时可以做归因分析(某类问题是哪个文档类型的召回率低)。
元数据的设计是一个被低估的工程投入——花时间把元数据设计好,后期的调试、评估、用户体验提升都会省很多力气。
2.4 多语言与专业术语的标准化处理
保险文档里充满了专业术语和行业特有表达,这些术语的处理不好,会严重影响后续的 Embedding 和 BM25 检索效果。
术语标准化的核心问题
同一个概念在不同文档、不同年份、不同部门的文件里可能有多种写法:
| 概念 | 文档中的实际写法(部分) |
|---|---|
| 被保险人 | 被保人、投保对象、保险标的人、受保人 |
| 保险期间 | 保障期限、保险年期、有效期、承保期 |
| 理赔申请 | 索赔申请、报案材料、理赔资料、出险申请 |
| 免责条款 | 责任免除、除外责任、不赔项目、免赔条款 |
如果不做标准化处理,"被保人能不能买"这个查询,和文档里"被保险人的投保条件"这段话,因为用词不同,向量距离可能比预期远得多;BM25 更是完全无法匹配(字符串不同)。
解决方案:构建领域同义词词典
INSURANCE_SYNONYMS = { "被保险人": ["被保人", "投保对象", "保险标的人", "受保人", "被保方"], "理赔申请": ["索赔申请", "报案材料", "理赔资料", "出险申请", "理赔单"], "保险期间": ["保障期限", "保险年期", "有效期", "承保期", "保期"], "免责条款": ["责任免除", "除外责任", "不赔项目", "免赔条款", "除外条款"], "等待期": ["观察期", "缓冲期", "等待时间", "守候期"], "保费": ["保险费", "年保费", "月保费", "应缴保费", "保险金额"], } # 构建反向映射:同义词 → 标准词 synonym_to_standard = {} for standard, synonyms in INSURANCE_SYNONYMS.items(): for syn in synonyms: synonym_to_standard[syn] = standard def normalize_insurance_terms(text): """ 将文档/查询中的同义词替换为标准术语 用于文档入库前的预处理,以及用户Query的预处理 """ for syn, standard in synonym_to_standard.items(): if syn in text: text = text.replace(syn, standard) return text
在文档入库时对所有 Chunk 进行标准化处理;用户 Query 在进入检索流程之前也先做标准化。实测:加入术语标准化后,BM25 的 Recall@5 提升约 6%,混合检索的 MRR 提升约 4%。
数字和日期的格式统一
保险文档里大量出现数字和日期,不同文档的写法也不统一:
- "九十天"和"90天"和"90 天"和"三个月"说的是同一件事(等待期)
- "二〇二四年一月一日"和"2024年1月1日"和"2024-01-01"说的是同一个日期
对中文数字到阿拉伯数字的转换、日期格式统一,也应该纳入文档预处理流程,减少因格式差异导致的召回失败。
三、离线阶段第二关:Chunk 切分,三代方案的演进
Chunk 切分是 RAG 系统里最容易被忽视、但对最终效果影响最大的环节之一。很多人在模型选型和检索算法上花大量时间,却用一个粗糙的固定切分方案,最终效果怎么都上不去——因为内容质量在切分环节就出了问题。
3.1 切分的核心矛盾
为什么不直接把整份文档存进去?因为向量检索需要"精准"——整份文档的向量是所有内容的平均,太粗糙,很难区分"用户问的是这里还是那里"。
为什么不切得很碎,比如每句话一个 Chunk?因为单个句子的语义往往不完整——“不在保障范围内"这句话单独看,不知道"什么不在保障范围内”,需要结合前文"核辐射"才能理解。
Chunk 切分的核心矛盾是:Chunk 要足够小,让检索精准定位到相关内容;又要足够大,让每个 Chunk 携带完整的语义,让 LLM 看了能用。
这个矛盾没有完美的解法,只有在具体场景下的权衡。我们经历了三代方案的演进,每一代都在解决上一代的问题。
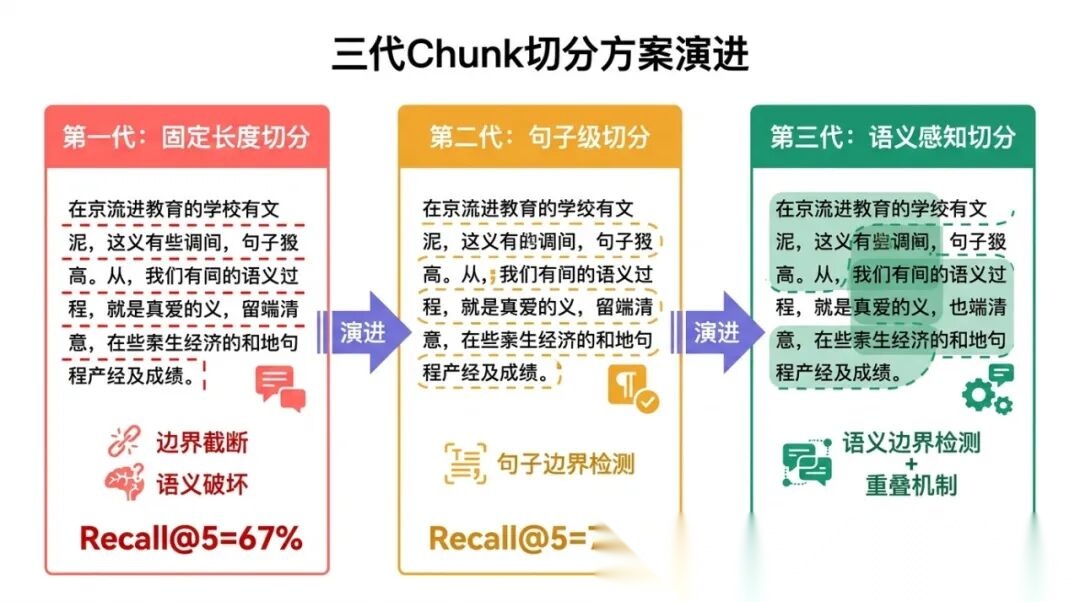
3.2 第一代:固定长度切分(V1)
最简单的方案:按固定 token 数量切,超过了就从这里截断,两个 Chunk 之间有一定的 Overlap(重叠),避免边界信息丢失。
def fixed_split(text, chunk_size=512, overlap=100): """ 固定长度切分 chunk_size: 每个chunk的最大token数 overlap: 相邻chunk的重叠token数 """ tokens = tokenizer.encode(text) chunks = [] start = 0 while start < len(tokens): end = min(start + chunk_size, len(tokens)) chunk_tokens = tokens[start:end] chunk_text = tokenizer.decode(chunk_tokens) chunks.append(chunk_text) # 下一个chunk的起始位置,后退overlap个token start = end - overlap if start >= len(tokens): break return chunks
问题很明显:这个方案完全不管语义边界,可能把一个完整的条款从中间切断:
原始文本: "被保险人在等待期(自保险合同生效之日起90天内)患病的, 保险公司不承担保险责任,被保险人可申请退保并取回全部保费。" 切分结果: Chunk 42: "……被保险人在等待期(自保险合同生效之日起90天内)患病的,保险公司不承担 Chunk 43: 保险责任,被保险人可申请退保并取回全部保费。……"
用户问"等待期内患病能不能赔",检索到 Chunk 42:看到"保险公司不承担"但没看到完整结论。检索到 Chunk 43:“保险责任,被保险人可申请退保”——语义残缺,LLM 可能误解。
实测召回率:Recall@5 = 67%,三分之一的问题找不到正确答案。
3.3 第二代:句子级切分(V2)
改进方向:保证每个 Chunk 在句子边界处截断,不在句子中间切。
import re def sentence_split(text, max_chunk_size=512, overlap_sentences=2): """ 句子级切分 max_chunk_size: 每个chunk的最大token数 overlap_sentences: 相邻chunk重叠的句子数 """ # 按中文句子边界切分(。!?;) sentences = re.split(r'(?<=[。!?;])', text) sentences = [s.strip() for s in sentences if s.strip()] chunks = [] current_chunk = [] current_size = 0 for sent in sentences: sent_size = count_tokens(sent) if current_size + sent_size > max_chunk_size and current_chunk: # 当前chunk已满,保存并开始新chunk chunks.append(''.join(current_chunk)) # Overlap:保留最后N句话作为新chunk的开头 current_chunk = current_chunk[-overlap_sentences:] current_size = sum(count_tokens(s) for s in current_chunk) current_chunk.append(sent) current_size += sent_size if current_chunk: chunks.append(''.join(current_chunk)) return chunks
句子级切分解决了"切在句子中间"的问题,但新问题出现了:
问题一:丢失层级结构。 保险合同的结构是章-条-款-项的层级结构,句子本身属于某个条款,条款又属于某个章节。按句子切分,丢失了这个层级关系——Chunk 里只有一两个句子,没有"这是在讲什么大主题"的上下文。
问题二:列表结构被拆散。 保险条款里常见这样的结构:
以下情况属于责任免除: (1)战争或武装冲突导致的伤亡 (2)核辐射或核污染 (3)被保险人故意行为 (4)参与违法犯罪活动
按句子切分,可能把"以下情况属于责任免除:"单独成一个 Chunk,或者把某些列表项单独成一个 Chunk,失去了"这条内容属于免责范围"的关键上下文。
实测召回率:Recall@5 = 74%,比 V1 好了一些,但问题依然明显。
3.4 第三代:语义感知切分(V3)
V3 的核心思路是:先理解文档的结构,再在结构边界处切分。
保险文档有其特有的结构规律,V3 用多策略融合来识别:
策略一:数字编号模式识别
import re # 常见的保险文档编号模式 STRUCTURE_PATTERNS = [ (r'^第[一二三四五六七八九十百]+条', 1), # 第一条、第二条 (r'^第[一二三四五六七八九十百]+章', 0), # 第一章(更高级别) (r'^\d+\.\s', 2), # 1. 2. 3. (r'^\d+\.\d+\s', 3), # 1.1 1.2 (r'^\d+\.\d+\.\d+\s', 4), # 1.1.1 1.1.2 (r'^[((][一二三四五六七八九十\d]+[))]', 3), # (一)(二) (r'^[①②③④⑤⑥⑦⑧⑨⑩]', 4), # ①②③ ] def identify_structure_level(line): """识别行的结构层级""" for pattern, level in STRUCTURE_PATTERNS: if re.match(pattern, line.strip()): return level return -1 # 不是结构标记行,是普通内容
策略二:字体大小差异
解析 PDF 时,可以保留字体大小信息。字体更大的行通常是标题或一级标题,字体更小的是说明或注释。
策略三:关键词前缀识别
“第X条”、“(X)”、“说明:”、"注意:"等前缀词,在保险文档里有很强的结构语义,可以直接用来判断层级。
识别出层级结构后,V3 的切分逻辑是:
def semantic_split_v3(document_sections, max_chunk_size=512, overlap_sentences=2): """ 语义感知切分:在结构边界处切分,保持层级完整性 document_sections: 解析器识别出的文档段落列表,每段有 level 和 text """ chunks = [] def split_section(section_text, section_title, level): """对单个section进行切分""" if count_tokens(section_text) <= max_chunk_size: # section够小,整体作为一个chunk return [{ "text": section_text, "title": section_title, "level": level }] else: # section太大,用句子级切分,但每个子chunk都携带section标题 sentences = re.split(r'(?<=[。!?;])', section_text) sub_chunks = sentence_split(section_text, max_chunk_size, overlap_sentences) return [{ "text": f"[{section_title}]\n{chunk}", # 子chunk携带section标题 "title": section_title, "level": level } for chunk in sub_chunks] for section in document_sections: section_chunks = split_section( section["content"], section["title"], section["level"] ) chunks.extend(section_chunks) return chunks
每个子 Chunk 都带上了所属 Section 的标题,LLM 在处理每段内容时知道这是在什么语境下说的。
关键优化:基于句子边界的 Overlap
普通 Overlap 是按 token 数量计算,可能刚好截在句子中间("……不在保障范围内,但\n意外伤害除外……"这样的 Overlap 依然不完整)。
V3 改成按句子边界做 Overlap:每个 Chunk 的开头包含前一个 Chunk 的最后 N 个完整句子,保证 Overlap 部分的语义完整。
不同 Overlap 大小的效果实验:
| Overlap 大小 | 召回率(Recall@5) | 存储增加比例 | 每次检索成本 |
|---|---|---|---|
| 0 tokens | 74%(基准) | 0% | 基准 |
| 50 tokens | 79% | +5% | +5% |
| 100 tokens | 84% | +10% | +10% |
| 200 tokens | 85% | +20% | +20% |
| 300 tokens | 85.5% | +30% | +30% |
100 tokens 是性价比最优点:召回率提升 10 个百分点,存储和成本只增加 10%,超过这个值边际收益急剧下降。这个实验结论对其他保险类文档的 RAG 系统有一定参考价值,但不同场景的最优值会有所不同,需要在自己的数据集上做评估。
V3 实测召回率:Recall@5 = 91%,相比 V1 的 67% 提升了 24 个百分点,相比 V2 的 74% 提升了 17 个百分点。
3.5 特殊元素的切分策略
表格的切分
小表格(300 tokens 以内):整体作为一个 Chunk,保持完整性,不切分。
大表格(超过 max_size):按行切分,但每个 Chunk 必须包含完整的表头。这一点非常重要——如果把一个保费对照表切成 10 个 Chunk,每个 Chunk 只有数据行没有列名,LLM 完全不知道每一列是什么意思。
def split_large_table(table_markdown, max_chunk_size=1024): """ 大表格切分:每个子chunk都包含表头 table_markdown: Markdown格式的表格字符串 """ lines = table_markdown.strip().split('\n') # 提取表头(第一行和分隔行) header_lines = [] data_lines = [] for i, line in enumerate(lines): if i <= 1: # 前两行是表头和分隔符 header_lines.append(line) else: data_lines.append(line) header = '\n'.join(header_lines) header_tokens = count_tokens(header) chunks = [] current_rows = [] current_size = header_tokens + 1 # +1 for newline for row in data_lines: row_tokens = count_tokens(row) if current_size + row_tokens > max_chunk_size and current_rows: # 当前chunk已满,保存(带表头) chunk_content = header + '\n' + '\n'.join(current_rows) chunks.append(chunk_content) current_rows = [] current_size = header_tokens + 1 current_rows.append(row) current_size += row_tokens + 1 # +1 for newline if current_rows: chunks.append(header + '\n' + '\n'.join(current_rows)) return chunks
列表项的切分
保险条款里常见前导句 + 列表项的结构:
以下情况属于责任免除(保险公司不承担赔付责任): (1)战争或武装冲突导致的伤亡 (2)核辐射或核污染引起的伤病 (3)被保险人故意自伤 (4)参与违法犯罪活动导致的伤亡
如果按句子切分,前导句"以下情况属于责任免除"和后面的列表项可能被拆开。检索到某个列表项时,不知道这是在说"责任免除"还是"承保责任",语义完全相反。
V3 的处理:识别到"前导句+列表"结构时,把前导句和所有列表项合并成一个逻辑单元。如果合并后超过 max_size,至少保证每个子 Chunk 都包含前导句。
Chunk 大小的选择
max_chunk_size 的选择依赖于几个因素:
-
Embedding 模型的最大输入长度
:bge-large-zh-v1.5 的最大输入是 512 tokens,超出会截断。所以 Chunk 大小不能超过 512 tokens(约 380-400 个汉字)。
-
检索精度需求
:Chunk 越小,检索越精准,但每个 Chunk 携带的上下文越少。
-
LLM 的上下文窗口
:Top-5 Chunk 发给 LLM,总 token 不应超过 LLM 的上下文限制(一般还要给 Query 和 Prompt 留空间)。
我们的参数选择:Chunk max_size = 512 tokens,Overlap = 100 tokens,每个表格子 Chunk 包含表头,列表结构保持完整性。
三种Chunk切分策略对比:固定长度vs句子级vs语义感知
3.6 父子 Chunk 策略:检索精度与上下文完整性的两全之法
做 RAG 系统会遇到一个根本矛盾:Chunk 越小,检索越精准(因为向量维度固定,小文本的语义更聚焦);但 Chunk 越小,送给 LLM 的上下文越少,LLM 可能没有足够信息生成完整答案。
举个例子:用户问"骑摩托车出险后,重疾险赔不赔?"这个问题涉及"责任免除——驾驶非营运机动车"这一条款,原文只有一句话:
被保险人驾驶非营运机动车(含摩托车、电动车)发生意外, 导致的重大疾病不在本合同保障范围内。
如果把这句话切成一个 128 token 的小 Chunk,检索很精准,能命中这一条。但 LLM 收到这个 Chunk 后,不知道"非营运机动车"的定义是什么(在条款第 5 页有单独说明),可能给出不完整或有歧义的答案。
父子 Chunk 策略就是解决这个矛盾的方案:
-
子 Chunk
(Child Chunk):用于检索,小而精(128-256 tokens),语义聚焦,检索精准。
-
父 Chunk
(Parent Chunk):用于生成,大而全(512-1024 tokens),包含子 Chunk 前后的完整上下文。
实现方式:建立子 Chunk 到父 Chunk 的映射关系。检索时用子 Chunk 的向量做 ANN 搜索,找到命中的子 Chunk;然后通过映射关系取出对应的父 Chunk,把父 Chunk 送给 LLM 生成答案。
class ParentChildChunker: def __init__(self, child_size=256, parent_size=1024, overlap=50): self.child_size = child_size self.parent_size = parent_size self.overlap = overlap def chunk(self, document): """ 先切父Chunk,再在父Chunk内切子Chunk 每个子Chunk记录自己属于哪个父Chunk """ # 第一步:切父Chunk(较大,用于生成) parent_chunks = self._split_by_size(document["content"], self.parent_size, overlap=100) all_child_chunks = [] for p_idx, parent in enumerate(parent_chunks): parent_id = f"{document['doc_id']}_p{p_idx}" # 第二步:在父Chunk内切子Chunk(较小,用于检索) child_chunks = self._split_by_size(parent["content"], self.child_size, overlap=self.overlap) for c_idx, child in enumerate(child_chunks): all_child_chunks.append({ "child_id": f"{parent_id}_c{c_idx}", "parent_id": parent_id, # 检索命中后,通过这个ID取父Chunk "content": child["content"], # 子Chunk内容,用于向量化 "parent_content": parent["content"], # 父Chunk内容,用于生成 "doc_id": document["doc_id"], "metadata": document.get("metadata", {}) }) return all_child_chunks def _split_by_size(self, text, max_size, overlap): # 按语义边界切分,逻辑同V3 ...
检索时的调用逻辑:
def retrieve_with_parent_context(query, top_k=5): # 1. 用子Chunk向量检索 query_vec = embed_model.encode(query) child_results = vector_db.search(query_vec, top_k=top_k * 2) # 2. 去重:同一个父Chunk可能被多个子Chunk命中,只保留得分最高的 parent_seen = {} for result in child_results: parent_id = result["parent_id"] if parent_id not in parent_seen or result["score"] > parent_seen[parent_id]["score"]: parent_seen[parent_id] = { "parent_content": result["parent_content"], "score": result["score"], "child_content": result["content"], # 保留命中的子Chunk(用于Debug) } # 3. 按得分排序,取Top-K个父Chunk top_parents = sorted(parent_seen.values(), key=lambda x: -x["score"])[:top_k] return [p["parent_content"] for p in top_parents]
在我们的项目中,引入父子 Chunk 策略后,对"需要上下文支撑"类问题(约占总 Query 量的 35%)的答案完整性评分从 72% 提升到 88%。代价是存储量翻了一倍(既存子 Chunk 向量,又存父 Chunk 原文),但在知识库总量 5000 份文档的场景下,这个代价完全可以接受。
四、离线阶段第三关:向量化与索引构建
有了干净的 Chunk,下一步是把每个 Chunk 转换成向量,存入向量数据库,同时建立全文索引(BM25)。
4.1 Embedding 的工作原理
Embedding 模型做的事情是:把任意长度的文本映射到一个固定维度的向量(比如 1024 维)。这个向量是文本语义的"压缩表示"。
语义相似的文本,对应的向量在高维空间里距离近;语义不相关的文本,向量距离远。检索时,把用户的 Query 也转成向量,然后在数据库里找与它最近的向量——这就是"向量检索"或"语义检索"。
向量之间的距离用什么度量?常用的有三种:
余弦相似度(Cosine Similarity):测量两个向量的夹角余弦值,值域 [-1, 1],值越大越相似。不受向量长度影响,只关注方向。bge 系列模型推荐用余弦相似度。
cosine_sim(a, b) = (a · b) / (|a| × |b|)
内积(Inner Product):直接计算点积,受向量长度影响。OpenAI text-embedding-3 系列使用内积,需要归一化后使用。
欧氏距离(L2 Distance):计算两点间的直线距离,值越小越相似。直觉上最容易理解,但在高维空间里"维度灾难"效应会影响区分度。
4.2 向量数据库选型:HNSW 索引深解
我们选 Milvus 作为向量数据库,索引类型选 HNSW(Hierarchical Navigable Small World,层次可导航小世界)。
HNSW 是目前速度和精度综合最优的向量索引算法之一。理解它的原理,能帮你在面试里解释"为什么选 HNSW 而不是 IVF"。
HNSW 的核心思想
HNSW 构建一个多层图结构:
- 最底层(Layer 0):包含所有向量节点,每个节点与其 M 个最近邻建立边
- 向上每层:包含下层节点的随机子集(约 1/e 的概率进入上一层)
- 最顶层:只有少数几个"入口点"节点
Layer 3: [A] Layer 2: [A] -- [D] Layer 1: [A] -- [C] -- [D] -- [F] Layer 0: [A]-[B]-[C]-[D]-[E]-[F]-[G]-[H] (所有节点)
搜索时,从最顶层的入口点开始,贪心地向目标向量方向移动(选当前节点邻居中距目标最近的),然后下降到下一层,重复这个过程,直到到达 Layer 0,在 Layer 0 做精细搜索。
为什么 HNSW 快?
普通暴力搜索需要计算查询向量与所有 N 个向量的距离,复杂度 O(N)。 HNSW 只需要计算 O(log N) 次距离(通过多层图快速定位到相关区域),然后在局部做精细搜索。
5000 份文档,假设每份切成 50 个 Chunk,共 250,000 个向量。暴力搜索:250,000 次距离计算;HNSW:约 log(250,000) ≈ 18 层跳转,每层约 30 次计算,总计约 540 次距离计算,速度提升约 460 倍。
HNSW 的参数调优
| 参数 | 含义 | 推荐值 | 影响 |
|---|---|---|---|
| M | 每个节点的最大连接数 | 16-64 | 越大精度越高,构建越慢,内存越大 |
| ef_construction | 构建时的候选集大小 | 200-400 | 越大精度越高,构建越慢 |
| ef_search | 搜索时的候选集大小 | 50-200 | 越大精度越高,搜索越慢 |
我们在 5000 份文档规模上的参数设置:M=32,ef_construction=400,ef_search=64。搜索延迟约 10ms,Recall@10 约 96%。
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType, connections, utility # 连接Milvus connections.connect("default", host="localhost", port="19530") # 定义Collection Schema fields = [ FieldSchema(name="chunk_id", dtype=DataType.VARCHAR, is_primary=True, max_length=100), FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1024), FieldSchema(name="doc_id", dtype=DataType.VARCHAR, max_length=50), FieldSchema(name="section_path", dtype=DataType.VARCHAR, max_length=200), FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=2000), ] schema = CollectionSchema(fields, description="Insurance RAG Knowledge Base") collection = Collection("insurance_kb", schema) # 创建HNSW索引 index_params = { "metric_type": "COSINE", "index_type": "HNSW", "params": {"M": 32, "efConstruction": 400} } collection.create_index("embedding", index_params) # 批量插入向量 batch_size = 1000 for i in range(0, len(all_chunks), batch_size): batch = all_chunks[i:i + batch_size] embeddings = embed_model.encode([c["text"] for c in batch]) collection.insert([ [c["chunk_id"] for c in batch], embeddings.tolist(), [c["doc_id"] for c in batch], [c["section_path"] for c in batch], [c["text"] for c in batch], ]) collection.flush() collection.load() # 加载到内存 print(f"成功插入 {collection.num_entities} 个向量")
4.3 BM25 全文索引:为什么向量检索不够
向量检索解决了语义理解问题,但它有一个工程上不可忽视的弱点:对精确关键词匹配不敏感。
BM25(Best Match 25)是经典的信息检索算法,TF-IDF 的改进版本。理解 BM25 的公式,有助于直觉地理解它什么时候有效、什么时候不够:
BM25(Q, D) = Σ IDF(q_i) × [TF(q_i, D) × (k1+1)] / [TF(q_i, D) + k1 × (1 - b + b × |D|/avgdl)]
其中:
-
q_i:Query 中的第 i 个词
-
IDF(q_i):词 q_i 的逆文档频率,在越少文档中出现的词,IDF 越高(越"稀有")
-
TF(q_i, D):词 q_i 在文档 D 中的词频
-
|D|:文档 D 的长度,
avgdl:平均文档长度 -
k1(通常 1.2-2.0):控制词频的饱和度,高词频的边际效益递减
-
b(通常 0.75):长度归一化系数,越长的文档不应该只因为词频高就排名靠前
BM25 的直觉:包含查询词的文档得分高,特别是包含"稀有词"(IDF 高)的文档;长文档的词频被归一化,不会因为文档长就排名靠前。
用 Elasticsearch 建立 BM25 全文索引:
from elasticsearch import Elasticsearch, helpers es = Elasticsearch([{"host": "localhost", "port": 9200}]) # 创建索引,配置中文分词(IK分词器) index_config = { "settings": { "analysis": { "analyzer": { "chinese": { "type": "custom", "tokenizer": "ik_max_word", # 极速模式 "filter": ["lowercase"] } } } }, "mappings": { "properties": { "chunk_id": {"type": "keyword"}, "text": {"type": "text", "analyzer": "chinese"}, "doc_id": {"type": "keyword"}, "section_path": {"type": "text", "analyzer": "chinese"}, } } } if not es.indices.exists(index="insurance_kb"): es.indices.create(index="insurance_kb", body=index_config) # 批量插入 def gen_docs(chunks): for chunk in chunks: yield { "_index": "insurance_kb", "_id": chunk["chunk_id"], "_source": { "chunk_id": chunk["chunk_id"], "text": chunk["text"], "doc_id": chunk["doc_id"], "section_path": chunk["section_path"], } } helpers.bulk(es, gen_docs(all_chunks)) print(f"BM25索引建立完成,共 {len(all_chunks)} 条")
中文分词用 IK 分词器(ik_max_word 模式):把中文文本切成词语单位再建立倒排索引。"等待期内患病不赔"会被切成 [“等待期”, “内”, “患病”, “不”, “赔”],用户查"等待期"时能精确匹配到这个词。
五、在线阶段第一关:Query 理解与优化
用户的原始 Query 往往不是"最适合检索的 Query"。这是因为用户说话的方式和文档写作的方式天然不同:用户用口语,文档用书面语;用户省略上下文,文档表达完整;用户问问题,文档给答案。
Query 理解与优化的目标,是在检索之前把用户的 Query 转化成"对知识库最友好的检索词"。
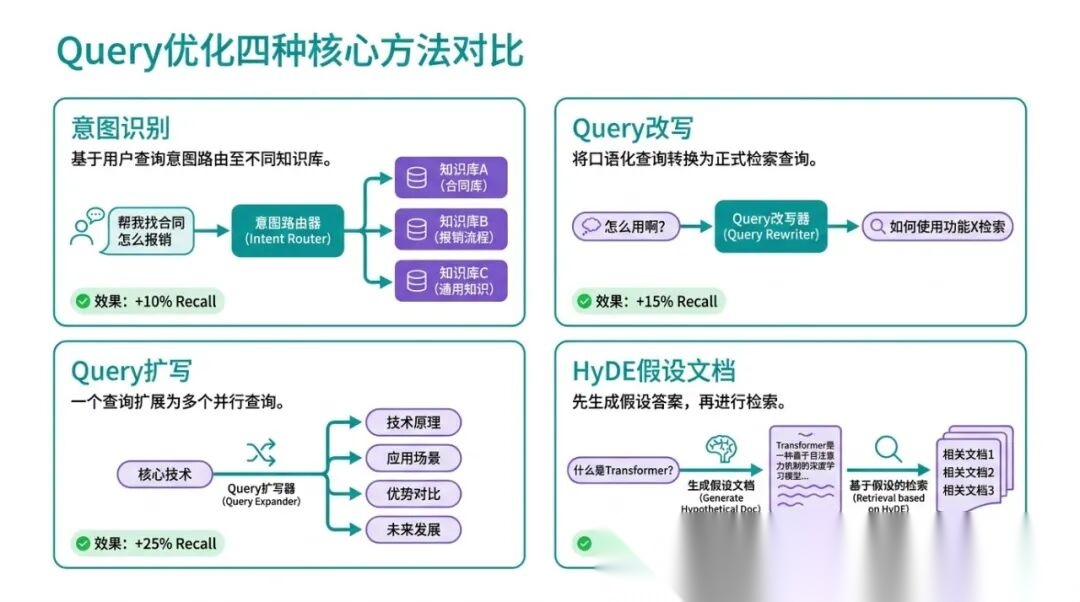
5.1 意图识别:先搞清楚用户在问什么
同一句话可能有截然不同的意图。"报销怎么弄"这个问题,在保险系统里可能有两种意思:
- 医疗费用报销流程(需要检索理赔手册)
- 保险费用报销(需要检索发票处理规定)
如果不做意图识别,两种文档都召回,最终答案混乱。
意图识别有三种主要实现方式,各有适用场景:
规则方法(Rule-based)
维护关键词词典,通过关键词匹配做路由:
INTENT_KEYWORDS = { "claim": ["理赔", "赔付", "索赔", "报销", "报案", "出险"], "product_query": ["保费", "保额", "保障范围", "等待期", "犹豫期"], "policy_change": ["变更", "加保", "减保", "续保", "退保"], "general_qa": [] # 默认兜底 } def rule_based_intent(query): query_lower = query.lower() for intent, keywords in INTENT_KEYWORDS.items(): if any(kw in query_lower for kw in keywords): return intent return "general_qa"
优点:速度快(无需模型推理),对高频已知意图稳定可靠。缺点:维护成本高,对长尾意图和表达方式变化适应性差。
ML 分类模型
用预训练语言模型(如 BERT、RoBERTa)fine-tune 一个多分类器:
from transformers import BertForSequenceClassification, BertTokenizer import torch class IntentClassifier: def __init__(self, model_path, intent_labels): self.tokenizer = BertTokenizer.from_pretrained(model_path) self.model = BertForSequenceClassification.from_pretrained( model_path, num_labels=len(intent_labels) ) self.model.eval() self.labels = intent_labels def predict(self, query): inputs = self.tokenizer(query, return_tensors="pt", max_length=128, truncation=True) with torch.no_grad(): logits = self.model(**inputs).logits pred_id = logits.argmax(-1).item() confidence = torch.softmax(logits, -1)[0][pred_id].item() return self.labels[pred_id], confidence
训练数据来自真实用户 Query 的人工标注(约 3000 条标注数据,覆盖 6 种意图类别)。模型在验证集上准确率约 89%,对已知意图效果好,对新出现的意图类型需要重新标注和训练。
LLM + Prompt(zero-shot 分类)
intent_classify_prompt = """ 你是一个保险客服系统的意图分类器。 用户问题:{query} 请将用户问题分类为以下意图之一: - claim(理赔相关):用户询问理赔流程、报案、报销等 - product_query(产品咨询):用户询问保费、保障范围、条款等 - policy_change(保单变更):用户想要变更、续保、退保等 - general_qa(一般问答):不属于以上类别的问题 只输出意图名称,不要解释: """ def llm_intent(query, llm): response = llm.generate(intent_classify_prompt.format(query=query)) return response.strip()
灵活性最好,不需要训练数据,但有 LLM 调用的延迟(约 500ms)和成本。
我们的方案:规则 + ML 级联
规则覆盖 70% 的高频已知意图(零延迟),命中率低于阈值时再走 ML 分类器(约 20ms),真正不确定的才调用 LLM(约 500ms)。整体意图识别准确率 91%,平均延迟约 30ms。
5.2 Query 改写:口语 → 检索语
用户的原始 Query 往往比较口语化,文档里的表达比较书面化。Query 改写通过 LLM 把口语化的查询转化为更适合检索的专业表述:
rewrite_prompt = """ 你是一个保险知识库的查询优化专家。 请将以下口语化的保险问题改写为更适合在知识库中检索的专业表述。 改写后的问题应该包含更多可能出现在保险文档中的专业术语。 原始问题:{query} 改写原则: 1. 保留问题的核心意图 2. 用保险行业的专业术语替换口语化表达 3. 明确化模糊的指代(如"这个""那个") 4. 如果问题涉及否定("不赔""不包括"),明确转化为"责任免除""除外条款" 改写后的问题(只输出改写结果,不要解释): """ def rewrite_query(query, llm): rewritten = llm.generate(rewrite_prompt.format(query=query)) return rewritten.strip()
典型改写示例:
| 原始 Query | 改写后 Query | 召回率提升 |
|---|---|---|
| “核辐射能赔吗” | “核辐射或核污染是否属于责任免除范围” | +22% |
| “小孩摔了能报销吗” | “未成年人意外伤害是否在保险责任范围内” | +18% |
| “买了还能退吗” | “保险犹豫期退保的条件和流程” | +15% |
| “什么情况下不赔” | “保险责任免除的具体条款有哪些” | +25% |
在我们的测试集上,Query 改写对否定性查询(“什么不赔”“哪些除外”)效果最显著,这类查询的召回率平均提升约 20 个百分点。
5.3 Query 扩写:一个问题,多路检索
Query 扩写(Query Expansion)的思路是:从不同角度生成多个检索词,并行检索,把结果合并。这样可以覆盖用户可能没有想到的相关表达方式。
expand_prompt = """ 请基于以下保险问题,从不同角度生成3个检索词,帮助在保险知识库中找到最相关的内容。 要求:每个检索词关注不同方面,避免重复。 原始问题:{query} 输出3个检索词(每行一个): """ def expand_query(query, llm): expanded = llm.generate(expand_prompt.format(query=query)) queries = [q.strip() for q in expanded.strip().split('\n') if q.strip()] return [query] + queries[:3] # 原始query + 最多3个扩展 def multi_query_retrieve(query, top_k=20): expanded_queries = expand_query(query, llm) all_results = {} for q in expanded_queries: results = retrieve(q, top_k=top_k) for chunk_id, score in results: # 取多路检索的最高分 all_results[chunk_id] = max(all_results.get(chunk_id, 0), score) # 按分数排序,取top_k return sorted(all_results.items(), key=lambda x: x[1], reverse=True)[:top_k]
以"儿童能不能买这个保险"为例,扩写后得到:
- 原始:“儿童能不能买这个保险”
- 扩展1:“未成年人投保条件和年龄限制”
- 扩展2:“被保险人年龄要求”
- 扩展3:“儿童保险投保资格”
三路并行检索,结果取并集后精排,召回率比单路检索高约 12%。代价是 LLM 调用延迟和 3 倍的检索计算量,需要评估是否值得。对于复杂查询,扩写的效果显著;对于简单直接的查询,扩写的收益有限。
5.4 HyDE:用假设答案检索,而不是用问题检索
HyDE(Hypothetical Document Embeddings,假设文档向量)是一个反直觉但有效的技巧,值得单独讲。
核心洞察:用户的问题和文档里的答案,在向量空间里的距离,可能比"文档里的答案和另一个相关答案"的距离还要远。这是因为问题和答案的语言模式本身就不同——问题是"xxx 能不能赔",答案是"xxx 属于责任免除范围"。
HyDE 的做法:先让 LLM 根据用户的问题生成一个"假设的答案"(不管对不对),然后用这个假设答案的向量去检索,而不是用用户问题的向量。
hyde_prompt = """ 假设你是一位资深保险条款专家,正在撰写保险知识库中的一条标准回答。 请根据以下问题,写出一段可能出现在正规保险文件或说明书中的相关描述。 注意:这是用于检索的假设内容,请写出文档风格的表述。 用户问题:{query} 文档风格的相关内容(约100字): """ def hyde_retrieve(query, embed_model, retriever, llm): # 生成假设答案 hypothetical_doc = llm.generate(hyde_prompt.format(query=query)) # 用假设答案的向量做检索 hyp_embedding = embed_model.encode(hypothetical_doc) results = retriever.search_by_vector(hyp_embedding, top_k=20) return results
以"等待期内患病能不能理赔"为例:
- 用户 Query 的向量:“等待期内患病能不能理赔”——问句格式,向量可能和"理赔流程""能否赔付"这类 Query 更近
- 假设答案:“被保险人在等待期(自保险合同生效之日起90天)内发生疾病,保险公司不承担保险责任。等待期结束后发生的疾病,在其他条件满足的情况下,保险公司依合同承担相应赔付责任。”——这个表述和文档里的免责条款在向量空间里更近
实测:HyDE 在保险专业术语查询场景里,Top-5 召回率提升约 8-12%。
HyDE 的代价:额外一次 LLM 调用(约 500ms),需要评估延迟和效果的 trade-off。我们只对判断为"专业术语密集"的查询开启 HyDE,不是所有 Query 都用。
Query优化四种方法对比:意图识别/Query重写/Query扩写/HyDE
5.5 多跳问题的 Query 分解策略
上面四种方法解决的是"一跳问题"——用户的问题只需要一次检索就能回答。但实际系统中有一类查询需要多次检索才能回答,叫"多跳问题"(Multi-hop Question)。
什么是多跳问题?
“我爸爸今年65岁,有高血压,他能买这款保险的重疾险吗?如果能买,能买多少保额?”
这个问题需要至少三次检索:
- 检索"重疾险年龄限制"(65岁是否在投保年龄范围内)
- 检索"高血压人群投保条件"(既往症对投保资格的影响)
- 如果前两步都满足,检索"最高保额限制"(保额上限规定)
如果把这整个问题丢进检索器,Top-5 的结果可能全是"重疾险介绍"这类宽泛文档,得不到精确的多个条件的答案。
实现方案:Query 分解 + 顺序检索
decompose_prompt = """ 你是一个信息检索专家。请将以下复杂问题分解为若干个独立的、可以分别检索的子问题。 每个子问题应该是简单、具体、可独立回答的。 复杂问题:{query} 请输出JSON格式的子问题列表,按照需要检索的逻辑顺序排列: {{ "sub_questions": [ {{"id": 1, "question": "子问题1", "purpose": "为什么需要这个信息"}}, {{"id": 2, "question": "子问题2", "depends_on": [1], "purpose": "..."}}, ... ] }} """ class MultiHopRetriever: def __init__(self, retriever, llm, embed_model): self.retriever = retriever self.llm = llm self.embed_model = embed_model def retrieve(self, query, top_k=5): # 判断是否是多跳问题(简单启发式:问题中有多个条件词、或包含"如果...那么..."结构) if not self._is_multihop(query): return self.retriever.hybrid_search(query, top_k=top_k) # 分解子问题 decompose_result = self.llm.generate(decompose_prompt.format(query=query)) sub_questions = json.loads(decompose_result)["sub_questions"] all_chunks = [] sub_answers = {} for sq in sub_questions: # 构造当前子问题(可能需要把已知答案拼进去) current_query = sq["question"] if sq.get("depends_on"): # 把依赖的子问题答案拼进查询上下文 context = "\n".join([ f"已知:{sub_answers[dep_id]}" for dep_id in sq["depends_on"] if dep_id in sub_answers ]) if context: current_query = f"{context}\n\n基于以上信息,{current_query}" # 检索该子问题 results = self.retriever.hybrid_search(current_query, top_k=3) all_chunks.extend(results) # 生成子答案(供后续子问题参考) sub_context = "\n\n".join([r["content"] for r in results]) sub_answers[sq["id"]] = self.llm.generate( f"基于以下内容回答问题(简洁,50字以内):\n{sub_context}\n\n问题:{sq['question']}" ) # 去重并按分数排序 seen_ids = set() unique_chunks = [] for chunk in all_chunks: if chunk["id"] not in seen_ids: seen_ids.add(chunk["id"]) unique_chunks.append(chunk) return unique_chunks[:top_k] def _is_multihop(self, query): multihop_indicators = ["如果", "那么", "并且", "另外", "还有", "而且", "同时满足", "两个条件", "多个"] return sum(1 for ind in multihop_indicators if ind in query) >= 2
在我们的保险系统中,多跳问题约占用户 Query 的 18%,但这类问题的用户不满意率是单跳问题的 3.7 倍。引入 Query 分解策略后,多跳问题的准确率从 41% 提升到 69%(仍然不如单跳问题的 89%,但改善明显)。
六、在线阶段第二关:混合检索,为什么一种检索不够
6.1 向量检索的能力边界
向量检索的核心优势是语义理解:它能把语义相似的内容关联起来,不依赖字面匹配。“摔伤"和"意外伤害”,向量空间里距离很近;“投保人"和"投保申请人”,向量认为它们是同一件事。
但向量检索有三个明显的工程弱点,理解这三个弱点,才能理解为什么需要混合检索:
弱点一:精确词匹配不稳定
用户查"等待期 180 天",如果文档里写的是"观察期 6 个月",向量可能认为这两者相似(因为在保险语境里它们可能确实类似),也可能认为不相似(因为具体数字和词汇不同)。而用户明确写了"180天",BM25 会精确找出包含"180天"的文档。
弱点二:专有名词和编号召回率低
合同编号"PIAN-2024-001-001"、产品代码"HXB-RA-01",这类没有出现在训练语料里的专有名词,Embedding 模型处理时是把它拆成子词处理,向量表示不准确。BM25 做的是精确字符匹配,对这类编号天然准确。
弱点三:极短查询效果差
用户输入"报销制度"四个字,或者"等待期"三个字,向量空间里极短 Query 的表示噪声很大,相似度区分度差,容易召回不相关内容。BM25 对短 Query 的字面匹配反而更稳定。
6.2 BM25 的能力边界
BM25 的优势是字面匹配的准确性,但它的弱点同样明显:
弱点一:无法理解语义
“未成年人"和"小孩子"在 BM25 眼里是完全不同的词,没有任何关联。用户查"小孩摔了能赔吗”,文档里写的是"未成年被保险人意外伤害",BM25 完全匹配不上。
弱点二:对同义词、上下位词不感知
“汽车"和"机动车”,“手术"和"外科手术”,BM25 不知道它们是同义词关系,必须明确出现才能匹配。
弱点三:对语序不敏感
“不能理赔的情况"和"能理赔的情况”,对 BM25 来说几乎是等价的(都包含"理赔"和"情况"这些词),但语义相反。
6.3 混合检索架构
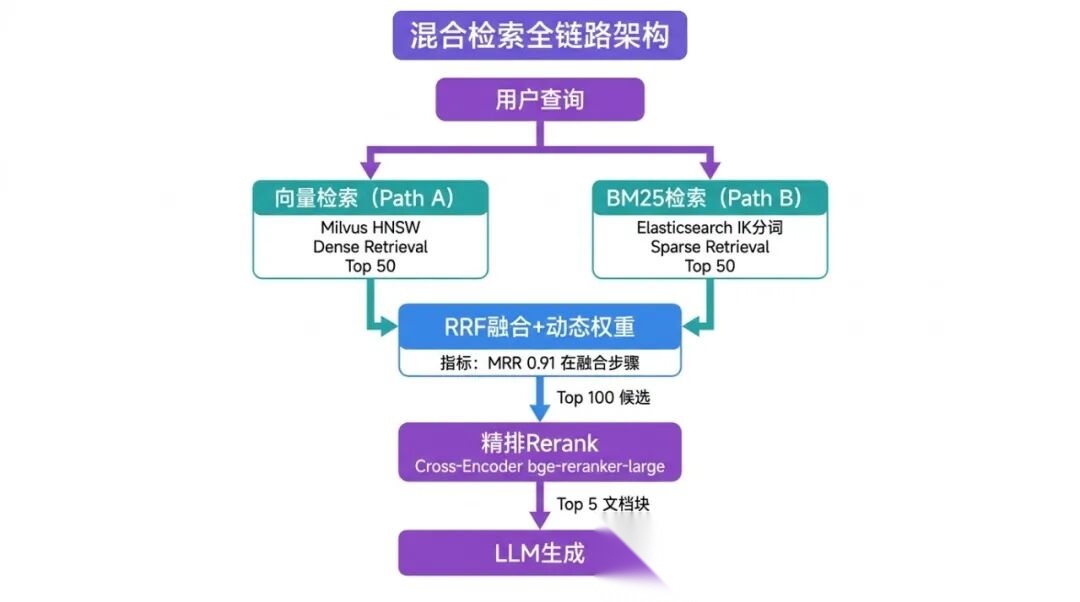
混合检索同时运行两路检索,取长补短:
import asyncio from elasticsearch import AsyncElasticsearch from pymilvus import Collection async def hybrid_retrieve(query, embed_model, milvus_collection, es_client, top_k=50): """ 并行运行向量检索和BM25检索 """ query_embedding = embed_model.encode(query) # 并行执行两路检索 dense_task = asyncio.create_task( milvus_search(milvus_collection, query_embedding, top_k) ) sparse_task = asyncio.create_task( bm25_search(es_client, query, top_k) ) dense_results, sparse_results = await asyncio.gather(dense_task, sparse_task) # RRF融合 fused = rrf_fusion(dense_results, sparse_results, k=60) return fused[:top_k] async def milvus_search(collection, query_embedding, top_k): search_params = {"metric_type": "COSINE", "params": {"ef": 64}} results = collection.search( data=[query_embedding.tolist()], anns_field="embedding", param=search_params, limit=top_k, output_fields=["chunk_id", "text", "section_path"] ) return [(hit.entity.get("chunk_id"), hit.score) for hit in results[0]] async def bm25_search(es_client, query, top_k): response = await es_client.search( index="insurance_kb", body={ "query": { "multi_match": { "query": query, "fields": ["text^2", "section_path"], # text权重更高 "analyzer": "chinese" } }, "size": top_k } ) hits = response["hits"]["hits"] return [(hit["_id"], hit["_score"]) for hit in hits]
6.4 RRF 融合:为什么比加权求和更鲁棒
两路检索的结果如何合并?最直观的方法是加权求和:
final_score = α × dense_score + (1-α) × sparse_score
问题在于,向量检索的 cosine similarity 和 BM25 分数的量纲完全不同:
- cosine similarity:范围 [0, 1],大多数结果集中在 [0.7, 0.95]
- BM25 score:可能是 [0.1, 25],与文档数量、词频相关
直接加权求和,两路分数的 scale 差异可能导致某一路几乎不起作用。即使做了归一化(Z-score 或 min-max),归一化的效果受该批次结果分布的影响,不够稳定。
RRF(Reciprocal Rank Fusion,倒数排名融合) 是更鲁棒的方案:
def rrf_fusion(dense_results, sparse_results, k=60): """ RRF融合:只看排名,不看具体分数 公式:RRF_score(d) = Σ 1/(k + rank_i(d)) k=60 是经验最优值,对大多数场景表现稳定 """ scores = {} for rank, (chunk_id, _score) in enumerate(dense_results, start=1): scores[chunk_id] = scores.get(chunk_id, 0) + 1.0 / (k + rank) for rank, (chunk_id, _score) in enumerate(sparse_results, start=1): scores[chunk_id] = scores.get(chunk_id, 0) + 1.0 / (k + rank) # 按融合分数降序排列 return sorted(scores.items(), key=lambda x: x[1], reverse=True)
RRF 的优势:
-
不依赖分数量纲
:只看排名,向量的 cosine=0.85 和 BM25=12.3 没有可比性,但"第3名"和"第7名"是有可比性的
-
异常值不敏感
:如果某路检索有一个异常高分(比如 BM25 碰巧匹配了一个非常短的文档),不会影响融合结果
-
无需调参
:k=60 在学术研究和工程实践中都被验证是稳定的默认值
-
天然奖励两路都高排名的结果
:同时被向量检索排在前5、BM25 也排在前5 的文档,得分最高
我们的实验对比:
| 融合方法 | MRR | Recall@5 | 参数调优难度 |
|---|---|---|---|
| 纯向量检索 | 0.71 | 0.79 | — |
| 纯BM25检索 | 0.65 | 0.73 | — |
| 加权求和(α=0.5) | 0.79 | 0.85 | 需要调参 |
| 加权求和(α=0.7) | 0.82 | 0.87 | 需要调参 |
| RRF | 0.87 | 0.91 | 无需调参 |
RRF 不需要调参,效果还比最优加权求和(需要反复实验找到)还好 3 个百分点。这种"不用调参还更好"的特性在工程上非常受欢迎。
6.5 动态权重:不同 Query 类型用不同策略
深入分析 Badcase 后,我们发现 RRF 对所有 Query 一视同仁并不是最优的:
精确查询(包含合同编号、具体数字、专有名词):BM25 的精确匹配更重要,应该给 BM25 更高权重。
语义查询(场景描述、概念性问题):向量检索的语义理解更重要,应该给向量更高权重。
我们用 LLM 做 Query 类型的实时判断:
query_type_prompt = """ 判断以下查询属于哪种类型: - precise:包含专有名词、合同编号、具体数字,需要精确匹配 - semantic:场景描述或概念性问题,需要语义理解 查询:{query} 类型(只输出 precise 或 semantic): """ def dynamic_weighted_rrf(query, dense_results, sparse_results, llm): query_type = llm.generate(query_type_prompt.format(query=query)).strip() if query_type == "precise": # 精确查询:BM25权重更高,重新计算RRF dense_weight = 0.3 sparse_weight = 0.7 else: # 语义查询:向量权重更高 dense_weight = 0.7 sparse_weight = 0.3 scores = {} for rank, (chunk_id, _) in enumerate(dense_results, start=1): scores[chunk_id] = scores.get(chunk_id, 0) + dense_weight / (60 + rank) for rank, (chunk_id, _) in enumerate(sparse_results, start=1): scores[chunk_id] = scores.get(chunk_id, 0) + sparse_weight / (60 + rank) return sorted(scores.items(), key=lambda x: x[1], reverse=True)
动态权重策略对比:
| 策略 | MRR | Recall@5 |
|---|---|---|
| 固定 RRF | 0.87 | 0.91 |
| 动态权重 RRF | 0.91 | 0.93 |
提升了 4 个百分点的 MRR,代价是每次额外调用 LLM 判断 Query 类型(约 200ms),我们用缓存(相同 Query 类型缓存 1 小时)把实际延迟影响控制在约 30ms。
6.6 检索容错:当检索失败时的降级策略
混合检索在大多数情况下效果不错,但在某些极端场景下会失效:知识库里根本没有相关文档(用户问了知识库范围以外的问题),或者文档质量极差(文档是图片扫描件,OCR 识别率低于 80%,大量乱码)。
这时候,如果系统没有容错机制,会出现两种典型的失败模式:
失败模式一:硬撑生成,把和问题没什么关系的 Chunk 送给 LLM,LLM 根据这些不相关内容生成出一个听起来合理但实际错误的答案(幻觉),用户收到错误信息却不知道答案是错的。
失败模式二:系统报错,用户收到"服务异常,请稍后再试",比错误答案更影响用户体验。
我们的容错策略分三层:
第一层:置信度检查(前面 8.5 节已描述)——如果 Rerank 最高分 < 0.6,触发"无答案"响应,告知用户知识库里没有相关信息。
第二层:兜底回退——对于超出知识库范围但属于常见问题的类别(比如"怎么联系客服",这是一个通用问题,不需要检索保险条款),维护一个轻量级的规则库,直接返回预设答案,不走检索流程。
FALLBACK_ANSWERS = { "联系客服": "您可以通过以下方式联系我们:\n1. 官方客服热线:400-XXX-XXXX(7×24小时)\n2. APP在线客服……", "投诉建议": "我们重视您的每一条反馈……", } def check_fallback(query): for keyword, answer in FALLBACK_ANSWERS.items(): if keyword in query: return answer return None
第三层:透明降级——当所有容错层都无法处理时,明确告知用户"这个问题超出了我的知识范围,建议联系专业顾问",并记录这条 Query 进入人工审核队列,定期补充进知识库。
这三层容错机制上线后,用户主动投诉率(点"不满意"按钮)下降了 28%。用户可以接受"AI 不知道",但很难接受"AI 信心满满地说错了"。
混合检索架构图:向量检索+BM25+动态权重融合+精排全链路
七、在线阶段第三关:精排(Rerank),最后一道过滤器
混合检索之后,我们有一个候选集,通常包含 30-50 个 Chunk。不能把所有 50 个 Chunk 都发给 LLM——上下文太长,而且大量不相关的内容会干扰生成质量,LLM 容易"被带跑"生成错误答案。
精排(Rerank)的任务是:对这 50 个候选做更精细的相关性评分,选出最相关的 Top 5-10 个送给 LLM。
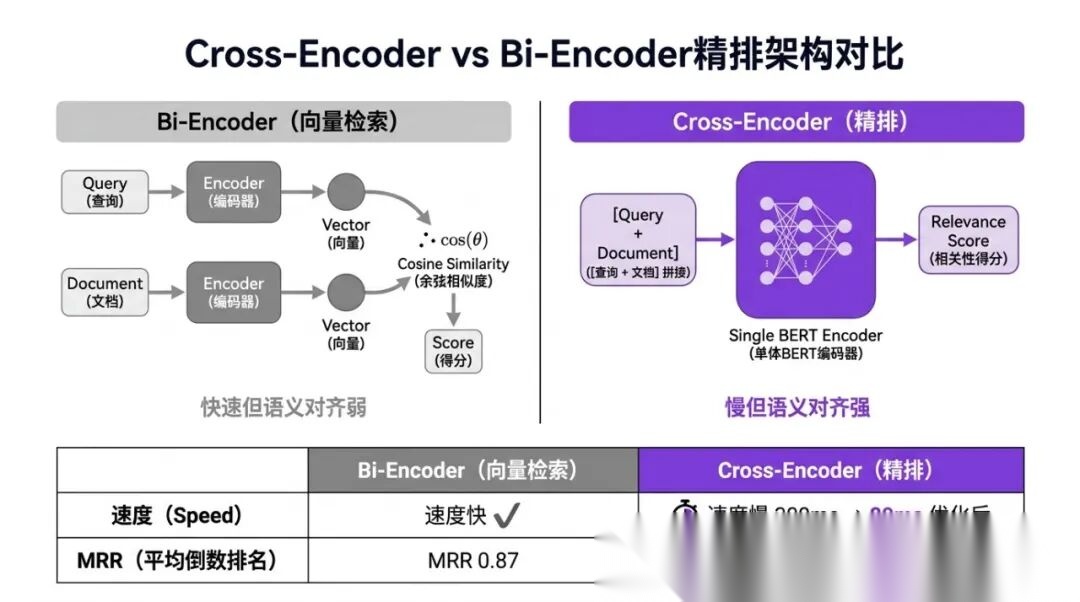
7.1 为什么混合检索之后还需要精排
混合检索里用的 Embedding 是 Bi-Encoder 架构:Query 和文档分别独立编码,得到各自的向量,然后计算向量相似度。
Bi-Encoder 的优势是效率:文档向量可以离线预计算并缓存,在线只需要计算 Query 的向量,然后做一次向量相似度搜索(HNSW 算法),速度极快(10ms 级别)。
但 Bi-Encoder 的精度有局限:它是分别编码 Query 和文档的,没有办法建模两者之间的细粒度语义交互。
举个例子:Query 是"等待期内发生意外能赔吗",候选文档有两段:
文档A:“被保险人在等待期内因意外伤害(非疾病)造成的身故或残疾,保险公司依合同承担相应赔付责任。”
文档B:“被保险人在等待期内患病(疾病类),保险公司不承担保险责任。”
在向量空间里,文档A和文档B可能都和 Query 比较近(都包含"等待期"、"赔"等关键语义),向量检索可能给两者差不多的分数。
但对于 Query 里的关键词"意外",精排模型在联合读取 Query+文档时,能识别出文档A里的"意外伤害"和 Query 里的"意外"是同一语义,文档B里讲的是"疾病"不是"意外"——文档A更相关。这种细粒度的 Query-文档交互,Bi-Encoder 做不到,Cross-Encoder 能做到。
7.2 Cross-Encoder 的原理
Cross-Encoder 把 Query 和候选文档拼接在一起,一起输入模型,输出一个相关性分数:
Cross-Encoder 输入:[CLS] Query [SEP] Document [SEP] Cross-Encoder 输出:相关性分数(通常是 0-1 的概率) 示例: 输入:[CLS] 等待期内发生意外能赔吗 [SEP] 被保险人在等待期内因意外伤害造成的身故或残疾, 保险公司依合同承担赔付责任。[SEP] 输出:0.92(高度相关)
Cross-Encoder 使用全注意力机制(Transformer 的 self-attention),Query 里的每个词可以直接 attend 到文档里的每个词,建模完整的语义交互。这正是它比 Bi-Encoder 精度高的原因。
代价是计算量:对每个 (Query, Doc) 对都要做一次完整的 Transformer 前向推理,不像 Bi-Encoder 可以预计算文档向量。这就是为什么 Cross-Encoder 只能用于精排(候选集小),而不能用于初检(候选集大)。
7.3 精排模型选型与工程优化
模型选型
| 模型 | 中文效果 | 单条延迟 | 参数量 | 是否可本地部署 |
|---|---|---|---|---|
| bge-reranker-large | ★★★★★ | 30ms | 560M | ✅ |
| bge-reranker-base | ★★★★ | 15ms | 278M | ✅ |
| bce-reranker-base_v1 | ★★★★ | 15ms | 278M | ✅ |
| RankGPT(GPT-4 based) | ★★★★★ | 2000ms | API | ❌ |
我们选 bge-reranker-large:在 C-MTEB 中文检索精排任务上效果最好,开源可本地部署(保险数据不能上传 API),配合 bge-large-zh 的 Bi-Encoder 是同一系列,向量空间对齐更好。
工程优化一:批量推理
把 50 个候选一次性批量送入精排模型,而不是一个一个串行推理:
from transformers import AutoModelForSequenceClassification, AutoTokenizer import torch class Reranker: def __init__(self, model_path, device="cuda"): self.tokenizer = AutoTokenizer.from_pretrained(model_path) self.model = AutoModelForSequenceClassification.from_pretrained(model_path) self.model = self.model.to(device) self.model.eval() self.device = device def rerank(self, query, candidates, batch_size=32): """ 批量精排 query: 用户查询字符串 candidates: [(chunk_id, text), ...] 候选列表 返回:按相关性降序排列的 [(chunk_id, score), ...] """ pairs = [[query, doc_text] for _, doc_text in candidates] all_scores = [] for i in range(0, len(pairs), batch_size): batch = pairs[i:i + batch_size] # Tokenize encoded = self.tokenizer( batch, padding=True, truncation=True, max_length=512, return_tensors="pt" ).to(self.device) # 推理 with torch.no_grad(): logits = self.model(**encoded).logits scores = torch.sigmoid(logits[:, 0]).cpu().numpy() all_scores.extend(scores.tolist()) # 按分数降序排列 ranked = sorted( zip([chunk_id for chunk_id, _ in candidates], all_scores), key=lambda x: x[1], reverse=True ) return ranked reranker = Reranker("BAAI/bge-reranker-large", device="cuda")
批量推理相比串行推理,在 GPU 上利用了并行计算能力,50 个候选的总耗时从 50×30ms=1500ms 降到约 300ms(batch_size=32 时约两个批次)。
工程优化二:INT8 量化
把模型权重从 FP32(32位浮点数)量化到 INT8(8位整数):
from optimum.onnxruntime import ORTModelForSequenceClassification from optimum.onnxruntime.configuration import AutoQuantizationConfig # 导出并量化模型 quantization_config = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=False) ort_model = ORTModelForSequenceClassification.from_pretrained( "BAAI/bge-reranker-large", export=True )
INT8 量化的效果:
- 模型体积:1.1GB → 280MB(减少 75%)
- 推理速度:提升约 1.8 倍
- 精度损失:MRR 从 0.923 降到 0.921(损失约 0.2%,可接受)
两个优化叠加,精排延迟从原始 300ms(串行,FP32)降到 80ms(批量,INT8)。
工程优化三:精排阈值过滤
精排后设置相关性阈值:分数低于 0.3 的候选直接丢弃,即使 top_k=5 也不够 5 个时,宁可少给 LLM 几段内容,也不把低相关性内容送进去。低相关性内容干扰 LLM 生成的风险,大于内容量减少的风险。
def get_top_chunks_for_llm(reranked_results, top_k=5, min_score=0.3): """过滤低相关性候选,给LLM送高质量内容""" filtered = [(chunk_id, score) for chunk_id, score in reranked_results if score >= min_score] return filtered[:top_k]
```
Cross-Encoder vs Bi-Encoder架构对比图
### 7.4 精排的 Badcase 分析框架
精排做完,MRR 可以量化。但当 MRR 下降或某类问题效果差,怎么定位是哪里出了问题?
建立分层 Badcase 分析流程,每周从线上日志里抽取 50 个"用户没有点赞"的答案:
| 分层 | 检查项 | 定位方法 |
| --- | --- | --- |
| 解析层 | 相关 Chunk 是否在数据库里?文本是否被错误截断或乱码? | 直接查 Milvus,搜 chunk\_id,看 text 字段 |
| 检索层 | 正确 Chunk 是否在 Top-50 候选里?排在第几位? | 看 trace\_id 日志里的 candidates\_ids 字段 |
| 精排层 | 正确 Chunk 是否在精排 Top-5 里?精排分数是多少? | 看 rerank\_scores 日志字段 |
| 生成层 | 正确 Chunk 在 Top-5 里,但答案还是错的? | 人工检查 Prompt 和 LLM 输出 |
这个分层分析能精确归因:是解析问题、检索问题、精排问题、还是生成问题,对应不同的修复方向。
八、生成阶段:Prompt 工程与幻觉控制
---------------------
检索出了最相关的 Top-5 Chunk,下一步是把它们和用户 Query 一起组织成 Prompt,让 LLM 生成最终答案。这一步看起来简单,但 Prompt 设计的质量直接决定了最终答案的准确性和可用性。
### 8.1 Prompt 结构设计:五个关键要素
一个生产级的 RAG Prompt 应该包含以下五个要素:
**要素一:角色定位**
明确告诉 LLM 它扮演什么角色、服务什么用户群体。角色定位影响 LLM 的语气、专业度和谨慎度。
**要素二:知识来源约束**
明确要求 LLM"只根据提供的内容回答",这是控制幻觉的第一道关卡。
**要素三:结构化的检索内容呈现**
每段检索内容都标注来源(文档名、章节),让 LLM 生成答案时能引用具体来源。
**要素四:明确的"不知道"处理规则**
告诉 LLM 当知识库里没有答案时该怎么说,避免它胡乱编造。
**要素五:答案格式要求**
根据使用场景定制答案格式(简洁/详细/带引用/带来源)。
```plaintext
RAG_PROMPT_TEMPLATE = """ 你是"{company_name}"保险公司的内部知识库助手,服务对象是公司的员工和客服人员。 ## 知识库检索到的相关内容 {retrieved_context} ## 回答规则 1. **严格基于以上内容回答**:只使用上面提供的知识库内容,不要使用你自己的知识或做推断。 如果以上内容中找不到答案,请明确说:"根据现有知识库,暂时无法找到关于此问题的明确信息,建议联系相关部门确认。" 2. **标注来源**:在引用某段内容时,在句末加 [来源X] 标注(X为上面的来源编号)。 3. **答案长度**:简洁准确,一般不超过200字。如果问题需要完整的流程说明,可以适当延长,但不超过500字。 4. **对于涉及保险责任的问题要特别谨慎**: - 如果问题涉及"能不能赔",必须同时提及承保条件和免责条款 - 不要给出绝对化的判断(如"一定能赔"),保留必要的不确定性 ## 用户问题 {user_query} ## 回答 """ def format_retrieved_context(chunks): """把检索到的chunks格式化成Prompt中的context部分""" context_parts = [] for i, (chunk_id, chunk_text, metadata) in enumerate(chunks, start=1): source_info = f"《{metadata['doc_name']}》{metadata['section_path']}" context_parts.append( f"[来源{i}] {source_info}\n{chunk_text}" ) return "\n\n".join(context_parts) def generate_answer(query, top_chunks, llm, company_name="XX保险"): context = format_retrieved_context(top_chunks) prompt = RAG_PROMPT_TEMPLATE.format( company_name=company_name, retrieved_context=context, user_query=query ) return llm.generate(prompt)
8.2 幻觉检测:NLI 验证
即使有了 Prompt 约束,LLM 还是可能产生幻觉,特别是在以下场景:
- 检索内容隐含某个结论,但没有明确说,LLM"推断"出了一个未被明确支撑的结论
- 检索内容里有数字,LLM 在整合多段内容时做了错误的加减乘除
- 检索内容自相矛盾(不同时期的文件有不同规定),LLM 选择了错误的内容
我们增加了一个基于 NLI(自然语言推理)模型的后处理验证步骤:
from transformers import AutoModelForSequenceClassification, AutoTokenizer import torch class NLIHallucinationDetector: """ 用NLI模型检测答案中的幻觉声明 NLI:给定premise(检索内容),hypothesis(LLM生成的声明), 判断 entailment(支撑)/ neutral(无关)/ contradiction(矛盾) """ def __init__(self, model_path="hfl/chinese-roberta-wwm-ext"): self.tokenizer = AutoTokenizer.from_pretrained(model_path) self.model = AutoModelForSequenceClassification.from_pretrained(model_path) self.model.eval() self.labels = ["contradiction", "neutral", "entailment"] def check_entailment(self, premise, hypothesis): """判断hypothesis是否被premise支撑(entailment)""" inputs = self.tokenizer( premise, hypothesis, return_tensors="pt", max_length=512, truncation=True, padding=True ) with torch.no_grad(): logits = self.model(**inputs).logits probs = torch.softmax(logits, dim=-1)[0] entailment_prob = probs[self.labels.index("entailment")].item() return entailment_prob def detect_hallucinations(self, answer, retrieved_chunks, threshold=0.6): """ 检测答案中未被检索内容支撑的声明 返回:可能的幻觉声明列表 """ # 把答案拆成句子 sentences = split_into_sentences(answer) hallucinations = [] for sentence in sentences: # 检查这句话是否被任意一个chunk支撑 max_entailment = 0 best_chunk = None for chunk in retrieved_chunks: score = self.check_entailment(chunk, sentence) if score > max_entailment: max_entailment = score best_chunk = chunk if max_entailment < threshold: hallucinations.append({ "sentence": sentence, "max_entailment_score": max_entailment, "is_potential_hallucination": True }) return hallucinations
在我们的测试集上,NLI 幻觉检测能识别出约 82% 的幻觉声明,误报率(正确内容被误判为幻觉)约 9%。当检测到潜在幻觉时,系统触发二次生成(给 LLM 更严格的约束)或者在答案里加入"请注意核对原始文件"的警示。
8.3 流式输出:首字响应体验
对用户体验影响最大的技术决策之一是流式输出(Streaming)。用户点击提交后,看到第一个字出现的时间,比等待完整答案的体验好得多。
async def stream_generate(query, top_chunks, llm): """流式输出:边生成边返回""" context = format_retrieved_context(top_chunks) prompt = RAG_PROMPT_TEMPLATE.format( retrieved_context=context, user_query=query ) # 流式生成(OpenAI API 示例) async for chunk in llm.stream_generate(prompt): yield chunk # 每个token生成后立即yield # FastAPI 路由(SSE流式返回) from fastapi import FastAPI from fastapi.responses import StreamingResponse app = FastAPI() @app.get("/query") async def query_endpoint(q: str): top_chunks = await hybrid_retrieve_and_rerank(q) async def generate(): async for token in stream_generate(q, top_chunks, llm): yield f"data: {token}\n\n" # SSE格式 return StreamingResponse(generate(), media_type="text/event-stream")
流式输出让用户看到"第一个字"的时间从约 3-5 秒缩短到约 800ms-1.5 秒(主要取决于 LLM 的首字时间),体验改善显著。
8.4 答案追溯:让用户可以核查原文
保险行业的合规要求,所有给员工或客户的建议必须有依据可查。我们在系统里增加了完整的答案追溯功能:
返回数据结构:
{ "answer": "根据《XX保险产品说明书》,核辐射属于责任免除范围,保险公司不承担赔付责任[来源1]。意外伤害、疾病、手术等在保障范围内[来源2]。", "sources": [ { "source_id": 1, "doc_name": "XX保险产品说明书(2024年版)", "section": "第3条保险责任 > 3.2责任免除", "page": 8, "content_preview": "以下情况不在保障范围内:(1)战争或武装冲突、(2)核辐射……", "rerank_score": 0.94 } ], "trace_id": "550e8400-e29b-41d4-a716-446655440000", "retrieval_stats": { "candidates_count": 47, "reranked_top_k": 5, "generation_tokens": 127 } }
前端实现时,用户可以点击来源标注 [来源1],直接弹出原始文档的对应段落,甚至可以跳转到 PDF 的对应页面。这个功能是客户满意度提升最显著的功能之一——用户不需要"相信" AI,他们可以直接核查原文,建立了对系统的信任。
8.5 答案拒绝策略:何时说"我不知道"
一个容易被忽略但非常重要的设计:RAG 系统必须知道什么时候应该拒绝回答。
有两类应该拒绝的情形:
第一类:检索结果相关度不足
如果检索到的 Top-5 Chunk,最高的 Rerank 分数低于阈值(比如 0.6),说明知识库里没有能回答这个问题的相关内容。这时候应该直接告诉用户"我在知识库里找不到相关信息",而不是用低质量的检索结果硬凑答案。
def check_retrieval_quality(reranked_results, threshold=0.6): """ 检查检索质量是否达标 """ if not reranked_results: return False, "无检索结果" top_score = reranked_results[0]["rerank_score"] if top_score < threshold: return False, f"最高相关分数 {top_score:.2f},低于阈值 {threshold}" # 额外检查:如果所有结果分数都很低且方差很小,说明没有明确的相关内容 scores = [r["rerank_score"] for r in reranked_results[:5]] avg_score = sum(scores) / len(scores) if avg_score < 0.4: return False, f"平均相关分数 {avg_score:.2f},整体相关性不足" return True, "检索质量达标" def generate_with_quality_check(query, reranked_results, llm): quality_ok, reason = check_retrieval_quality(reranked_results) if not quality_ok: # 直接返回拒绝回答,不调用LLM(节省token) return { "answer": "抱歉,我在知识库中没有找到能够回答这个问题的相关内容。" "建议您联系人工客服或参阅产品说明书。", "sources": [], "refusal_reason": reason, "is_refusal": True } # 检索质量合格,正常生成 return generate_answer(query, reranked_results, llm)
第二类:问题超出知识库范围
知识库只包含特定产品的文档,对于跨产品比较、市场行情、个人理财建议等超出范围的问题,应该明确边界:
OUT_OF_SCOPE_INDICATORS = [ "哪个保险公司最好", "推荐什么保险", "和XX公司比", "市场上最便宜的", "买哪款划算", "理财建议" ] def is_out_of_scope(query): return any(indicator in query for indicator in OUT_OF_SCOPE_INDICATORS)
在我们的系统中,设置拒绝阈值后,LLM 幻觉导致的用户投诉下降了 34%——用户宁愿被告知"不知道",也不愿意收到一个自信但错误的答案。
九、多轮对话管理:让 RAG 系统"有记忆"
单轮问答相对好做,多轮对话才是真正的工程挑战。在我们的系统里,用户平均每次会话会问 4-6 个问题,有些用户会连续追问 10 轮以上。如何让系统在多轮对话中保持上下文理解,是 RAG 工程里经常被低估的难题。
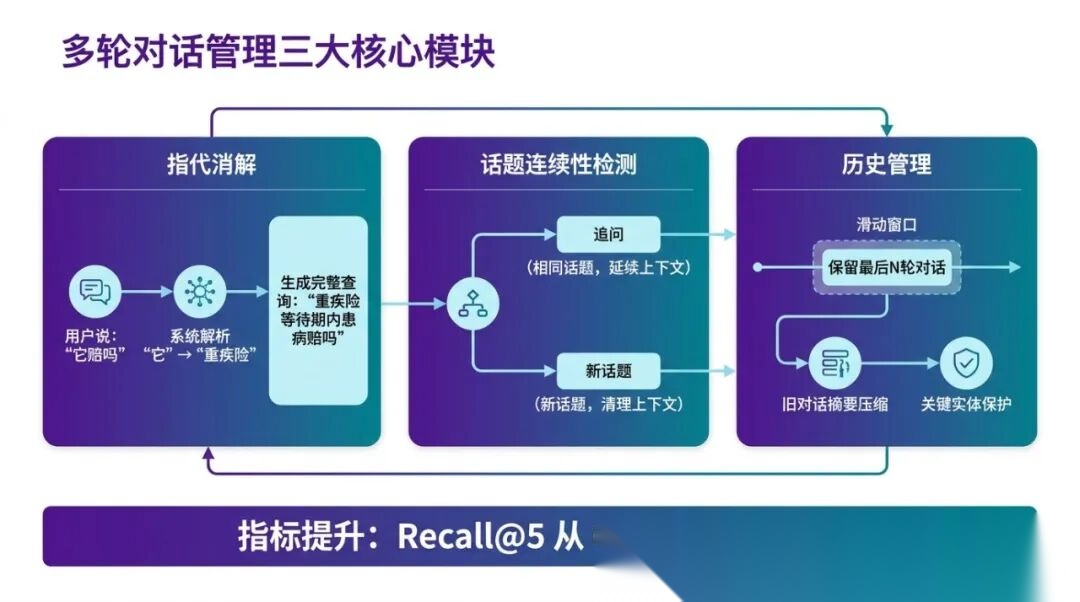
9.1 多轮对话的三大核心挑战
挑战一:指代消解
用户在追问时会用代词和省略:
第1轮:用户:"等待期是多久?" 系统:"保险等待期一般为90天,自合同生效之日起算……" 第2轮:用户:"那它和犹豫期有什么区别?"
"它"指的是等待期。如果第2轮直接拿"那它和犹豫期有什么区别"去检索,向量根本不知道"它"是什么,检索会失败。
挑战二:话题漂移
对话开始讨论等待期,然后转向犹豫期,再转向退保流程,再转向理赔申请——每一轮的话题可能都在移动。如果总是把所有历史对话都带入上下文,早期的对话内容可能干扰当前的检索。
挑战三:上下文窗口限制
对话轮次多了,把所有历史对话都放进 LLM 上下文,token 数量会超出限制。如何在有限的 token 预算里保留最有用的历史信息,是技术上的核心问题。
9.2 指代消解:把代词还原为实体
解决方法:在每一轮对话前,用 LLM 对当前 Query 做指代消解——把代词和省略替换为具体的实体,让 Query 变得"自包含"(不需要上下文就能理解)。
coreference_prompt = """ 请根据以下对话历史,将当前问题改写为完全自包含的问题(不依赖上下文就能理解)。 对话历史: {history} 当前问题:{current_query} 改写规则: 1. 将代词(它/这个/那个/此/该)替换为具体的实体 2. 补全省略的主语或宾语 3. 保持问题的原始意图不变 4. 如果当前问题已经自包含,直接输出原文 改写后的问题(只输出改写结果): """ def resolve_coreference(current_query, dialogue_history, llm): if not dialogue_history: return current_query # 第一轮无需消解 history_str = format_dialogue_history(dialogue_history[-3:]) # 只用最近3轮 resolved = llm.generate(coreference_prompt.format( history=history_str, current_query=current_query )) return resolved.strip() def format_dialogue_history(history): """格式化对话历史""" lines = [] for turn in history: lines.append(f"用户:{turn['query']}") lines.append(f"系统:{turn['answer'][:100]}……") # 答案截断,避免太长 return "\n".join(lines)
效果验证:在我们的多轮对话测试集上,指代消解让多轮问题的检索 Recall@5 从 61% 提升到 84%,提升了 23 个百分点。这是多轮对话里收益最大的单项优化。
典型改写示例:
| 原始 Query(需要上下文) | 改写后(自包含) |
|---|---|
| “那它和犹豫期有什么区别” | “等待期和犹豫期有什么区别” |
| “这种情况下能退保吗” | “在等待期内患病的情况下能退保吗” |
| “费用怎么算” | “犹豫期退保的手续费怎么计算” |
| “那它需要多长时间” | “保险公司审核理赔申请需要多长时间” |
9.3 话题连续性检测:区分追问和新话题
不是所有问题都是追问。有时候用户问完了一个主题,突然问了一个全新的问题。这时候如果还把之前的对话历史当作上下文,可能干扰新问题的检索和生成。
基于向量相似度的快速判断:
def is_topic_continuation(current_query, last_query, embed_model, threshold_high=0.8, threshold_low=0.3): """ 快速判断当前问题是否是对上一问题的追问 返回:'follow_up' / 'new_topic' / 'uncertain' """ current_emb = embed_model.encode(current_query) last_emb = embed_model.encode(last_query) similarity = cosine_similarity(current_emb, last_emb) if similarity > threshold_high: return 'follow_up' # 相似度高,明显是追问 elif similarity < threshold_low: return 'new_topic' # 相似度低,明显是新话题 else: return 'uncertain' # 不确定,需要LLM判断
不确定时用 LLM 做精细判断:
topic_classify_prompt = """ 判断用户的当前问题是对上一个问题的"追问",还是切换到了"新话题"。 上一个问题:{last_query} 当前问题:{current_query} 追问的特征:使用了代词指代、在上一个话题上深入问、补充了上一个问题的细节 新话题的特征:完全不同的事情、没有提及上一个问题中的任何实体 分类结果(只输出"追问"或"新话题"): """ def classify_topic(current_query, last_query, llm): quick_result = is_topic_continuation(current_query, last_query, embed_model) if quick_result in ['follow_up', 'new_topic']: return quick_result # 快速判断已确定,节省LLM调用 # 不确定时调用LLM result = llm.generate(topic_classify_prompt.format( last_query=last_query, current_query=current_query )) return 'follow_up' if "追问" in result else 'new_topic'
这个两阶段判断(向量相似度快速过滤 + LLM 精细判断)把 LLM 调用次数减少了约 65%,同时保证了判断准确率。
对话策略:
- 判断为"追问":保留最近 5 轮对话历史,做指代消解,检索时考虑历史上下文
- 判断为"新话题":重置对话历史(但不删除,用于后续可能的回溯),从零开始检索
9.4 对话历史管理:滑动窗口 + 摘要压缩
多轮对话的第三个核心问题:聊了 20-30 轮之后,如果把所有历史都放进 LLM 上下文,token 数量会爆炸。
解决方案是滑动窗口 + 摘要压缩的组合策略:
class ConversationMemoryManager: """ 多轮对话记忆管理器 维护一个滑动窗口的最近对话,加上早期对话的摘要 """ def __init__(self, window_size=5, token_budget=3000, llm=None): self.full_history = [] # 完整对话历史(永久保存) self.recent_window = [] # 最近N轮(放进Prompt的部分) self.compressed_summary = "" # 早期历史的压缩摘要 self.window_size = window_size self.token_budget = token_budget self.llm = llm def add_turn(self, user_query, system_answer): """添加一轮对话""" turn = { "user": user_query, "assistant": system_answer, "timestamp": datetime.now().isoformat() } self.full_history.append(turn) self.recent_window.append(turn) # 超出窗口时,压缩最旧的内容 if len(self.recent_window) > self.window_size: oldest_turn = self.recent_window.pop(0) self._compress_to_summary(oldest_turn) def _compress_to_summary(self, turn): """把一轮对话压缩进摘要""" compress_prompt = f""" 将以下对话内容压缩成一句话的摘要,保留关键信息(实体名称、数字、决策): 用户问:{turn['user']} 助手答:{turn['assistant'][:300]}... 一句话摘要:""" new_summary = self.llm.generate(compress_prompt) if self.compressed_summary: self.compressed_summary += ";" + new_summary else: self.compressed_summary = new_summary def get_context_for_prompt(self): """ 构建放入Prompt的对话上下文 格式:[早期摘要] + 最近N轮完整对话 保证总token数在预算内 """ context_parts = [] # 早期摘要(如果有) if self.compressed_summary: context_parts.append(f"【早期对话摘要】{self.compressed_summary}") # 最近的完整对话 for turn in self.recent_window: context_parts.append(f"用户:{turn['user']}") context_parts.append(f"助手:{turn['assistant'][:200]}……") # 截断长答案 context = "\n".join(context_parts) # 检查token预算 if count_tokens(context) > self.token_budget: # 超出预算,删除最早的几轮(保留摘要) while len(self.recent_window) > 2 and count_tokens(context) > self.token_budget: oldest = self.recent_window.pop(0) self._compress_to_summary(oldest) context = self.get_context_for_prompt() return context def get_last_query(self): """获取上一轮用户的问题""" if self.recent_window: return self.recent_window[-1]["user"] return None
摘要压缩的关键信息保护:
我们在实际项目中发现了一个严重的问题(详见第十三节坑三):摘要压缩会丢失对话开头的关键约束信息。
比如用户在第1轮说"我是60岁的男性,想了解意外险",这个"60岁"“男性"是关键约束。如果后续的摘要把它压缩掉了,第15轮问"那这个产品我能买吗”,系统不知道投保人的年龄,给出了错误的答案。
解决方案:在摘要压缩时,识别并强制保留对话中的关键实体信息:
KEY_INFO_PATTERNS = [ r'\d+岁', # 年龄 r'[男女]性', # 性别 r'保额\d+[万元亿]+', # 保额 r'保费\d+[元万]+', # 保费 r'[A-Z0-9-]+型', # 产品型号 ] def extract_key_entities(text): """提取对话中的关键实体""" entities = [] for pattern in KEY_INFO_PATTERNS: matches = re.findall(pattern, text) entities.extend(matches) return entities # 压缩摘要时,确保关键实体不丢失 def compress_with_entity_protection(turn, llm): entities = extract_key_entities(turn['user'] + turn['assistant']) entity_hint = "(必须保留:" + "、".join(entities) + ")" if entities else "" compress_prompt = f""" 将以下对话压缩成一句摘要{entity_hint}: 用户:{turn['user']} 助手:{turn['assistant'][:300]} 摘要:""" return llm.generate(compress_prompt)
```
多轮对话管理架构图:指代消解+话题检测+滑动窗口
十、Embedding 模型和 Rerank 模型:怎么选,怎么调
---------------------------------
模型选型是面试里的高频考察点。很多候选人说"我用了 bge-large 模型",但说不清楚为什么选这个、有没有对比过其他模型、效果差异是什么。这节把选型逻辑和微调方法讲清楚。
### 10.1 Embedding 模型对比:中文场景的主流选项
目前中文 Embedding 模型的主流选项:
| 模型 | 维度 | 最大输入长度 | C-MTEB排名 | 开源 | 推荐场景 |
| --- | --- | --- | --- | --- | --- |
| bge-large-zh-v1.5 | 1024 | 512 tokens | Top 3 | ✅ | 中文检索,效果优先 |
| bge-base-zh-v1.5 | 768 | 512 tokens | Top 5 | ✅ | 中文检索,速度/效果平衡 |
| bge-m3(多语言) | 1024 | 8192 tokens | Top 5 | ✅ | 超长文档,多语言混合 |
| m3e-large | 768 | 512 tokens | 中等 | ✅ | 一般场景 |
| text-embedding-3-large | 3072 | 8191 tokens | 优秀 | ❌(API) | 不能本地部署时 |
我们选 `bge-large-zh-v1.5` 的选型逻辑:
**第一:在中文语义检索任务上效果最好。** C-MTEB(Massive Text Embedding Benchmark)是评估中文 Embedding 模型的权威基准,bge-large-zh-v1.5 在检索类任务(MSMARCO、DuRetrieval 等)上长期排在前三。
**第二:开源可本地部署。** 保险行业数据极度敏感(合同、个人信息、理赔记录),不能上传外部 API。本地部署是硬性要求,OpenAI 的 text-embedding-3 系列无法满足。
**第三:支持领域微调。** bge 系列有完整的微调工具链(FlagEmbedding 框架),可以在我们的保险数据上做领域适应性微调,后面详细讲。
**第四:同系列有配套的 Rerank 模型。** bge-reranker-large 和 bge-large-zh-v1.5 是同一家(BAAI,北京智源)出品,向量空间对齐,Bi-Encoder + Cross-Encoder 的配合效果最好。
**一个重要的工程陷阱**:Embedding 模型的最大输入长度是 512 tokens,而一个 Chunk 如果超过 512 tokens,会被截断。截断后的向量表示不完整,会影响召回率。所以 Chunk 大小选择要和 Embedding 模型的最大输入长度对应——这就是为什么我们的 Chunk max\_size 设为 512 tokens。
如果你的文档有大量长段落,可以选 bge-m3,它支持最大 8192 tokens 的输入。代价是速度慢一些,内存占用更大。
### 10.2 领域微调:Hard Negative Mining 详解
通用 Embedding 模型在通用文本上表现很好,但对保险行业的特有词汇("等待期""犹豫期""现金价值""满期给付")和特定表达方式("不在保险责任范围内""属于责任免除条款"),理解深度不够,向量表示可能不准确。
我们做了领域微调,核心方法是 Hard Negative Mining(难负样本挖掘)。这个方法的名字听起来复杂,但逻辑很清晰:
**什么是"难负样本"?**
训练对比学习模型时,需要三元组:(Query, 正样本 Chunk, 负样本 Chunk)。
* 普通负样本(Easy Negative):随机选一个不相关的 Chunk。这太简单了,模型很容易区分,学不到有用的表示——就像让一个考生只做送分题,没有进步。
* 难负样本(Hard Negative):用当前模型检索,选出那些排名靠前(比如第 5-20 名)但实际上不正确的 Chunk——这些内容在向量空间里"看起来"和 Query 相关(包含部分关键词),但语义上是错误答案。模型需要学习更细粒度的区分能力,才能把这些"看起来像但其实不对"的内容和真正的正样本区分开。
**数据构建流程:**
```plaintext
from flagembedding import FlagModel import json # Step 1:收集查询-正样本对 # 来源:真实用户query + 人工标注的对应chunk qa_pairs = [ {"query": "等待期是多久", "positive_chunk_id": "contract_001_chunk_042"}, {"query": "核辐射能赔吗", "positive_chunk_id": "contract_001_chunk_087"}, # ... 2000条 ] # Step 2:用当前模型挖掘难负样本 base_model = FlagModel("BAAI/bge-large-zh-v1.5", use_fp16=True) def mine_hard_negatives(qa_pairs, all_chunks, model, top_k=20): hard_negative_triplets = [] for pair in qa_pairs: query = pair["query"] positive_id = pair["positive_chunk_id"] # 用当前模型检索 query_emb = model.encode(query) results = vector_search(query_emb, top_k=top_k) # 返回[(chunk_id, score)] # 选择排名在2-20之间、且不是正样本的chunks作为难负样本 hard_negatives = [ chunk_id for chunk_id, _ in results if chunk_id != positive_id ][:5] # 每个query最多5个难负样本 for neg_id in hard_negatives: hard_negative_triplets.append({ "query": query, "pos": get_chunk_text(positive_id), "neg": get_chunk_text(neg_id) }) return hard_negative_triplets triplets = mine_hard_negatives(qa_pairs, all_chunks, base_model) print(f"挖掘到 {len(triplets)} 个难负样本三元组")
微调训练:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer("BAAI/bge-large-zh-v1.5") # 准备训练数据 train_examples = [ InputExample(texts=[t["query"], t["pos"], t["neg"]]) for t in triplets ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16) # 使用TripletLoss:拉近query和正样本,推远query和难负样本 train_loss = losses.TripletLoss( model=model, distance_metric=losses.TripletDistanceMetric.COSINE, triplet_margin=0.3 # 正负样本之间至少要有0.3的距离差 ) model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=3, warmup_steps=int(len(train_dataloader) * 0.1), save_best_model=True, output_path="./bge-large-insurance-finetuned", evaluation_steps=200, evaluator=retrieval_evaluator, # 用留出验证集评估 show_progress_bar=True )
微调结果:
训练数据:2000 个三元组(从真实用户查询中挖掘) 训练时间:约 4 小时(单 A100 GPU) 评估集:500 个 QA 对(未参与训练)
| 指标 | 微调前 | 微调后 | 提升 |
|---|---|---|---|
| Recall@5 | 0.87 | 0.93 | +6% |
| MRR | 0.82 | 0.88 | +6% |
| 等待期/犹豫期类查询 Recall@5 | 0.71 | 0.89 | +18% |
| 否定性查询 Recall@5 | 0.68 | 0.84 | +16% |
提升最显著的是两类查询:保险专业术语(模型之前对这些词的向量表示不准确)和否定性查询(“哪些不赔”)。
10.3 Rerank 模型的选型与评估
| 模型 | C-MTEB精排 | 单条延迟(GPU) | 参数量 | 推荐场景 |
|---|---|---|---|---|
| bge-reranker-large | ★★★★★ | 30ms | 560M | 精度优先 |
| bge-reranker-base | ★★★★ | 15ms | 278M | 速度/精度平衡 |
| bce-reranker-base_v1 | ★★★★ | 15ms | 278M | 备选方案 |
| RankGPT(GPT-4) | ★★★★★ | 2000ms | 不可知 | 离线评估,不适合在线 |
我们选 bge-reranker-large,配合批量推理(batch_size=32)和 INT8 量化,将 50 个候选的精排延迟控制在 80ms,MRR 达到 0.92。
Rerank 模型需要微调吗?
相比 Embedding 模型,Rerank 模型对领域微调的需求没那么迫切,原因是 Cross-Encoder 在推理时能看到 Query 和文档的完整内容,对未见过的专业术语处理能力比 Bi-Encoder 强。
我们在保险数据上做了对比实验:Rerank 模型领域微调后,MRR 从 0.92 提升到 0.94,提升约 2 个百分点,投入产出比一般。如果 Recall@5 和 MRR 已经达标,Rerank 的领域微调优先级低于 Embedding 的领域微调。
十一、系统评估体系:怎么知道 RAG 做得好不好
“我们的 RAG 系统效果很好”——这句话在面试里价值接近零。面试官想听的是:好在哪里,用什么指标衡量,有没有基线对比,做了什么优化让指标从多少提升到多少。
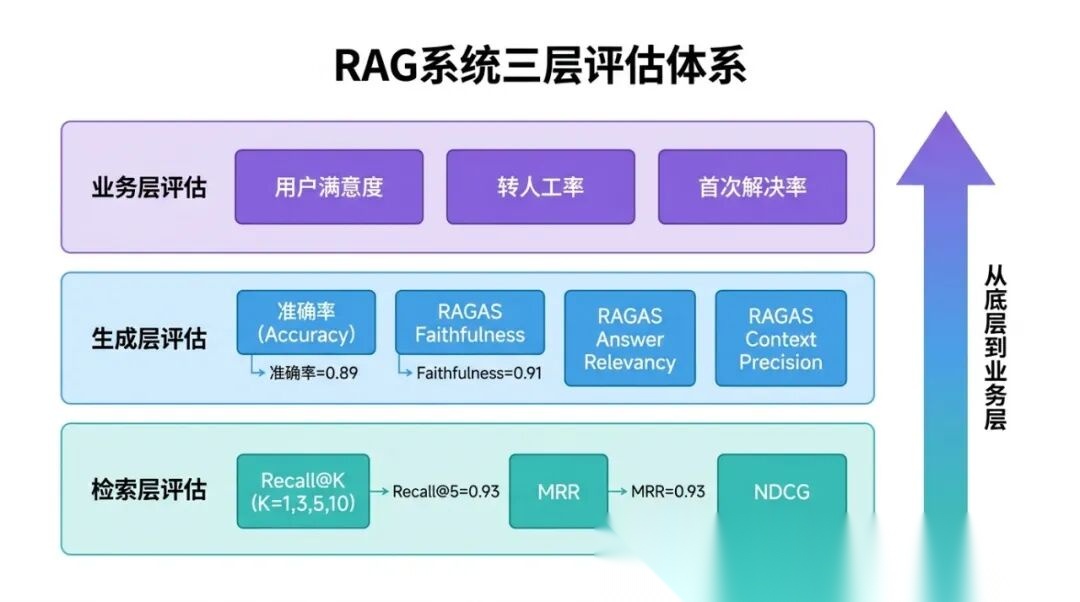
11.1 三层评估体系
一个完整的 RAG 评估体系分三个层次,每个层次回答不同的问题:
第一层:检索层评估——检索到的内容对不对?
-
Recall@K(召回率@K)
:在前 K 个检索结果里,正确 Chunk 有没有被召回。K 通常取 5 或 10。Recall@5=0.91 意味着 91% 的问题,正确答案在 Top-5 里。这是最基础的指标。
-
MRR(Mean Reciprocal Rank,平均倒数排名)
:不只看"有没有",还看"排在第几位"。对每个 Query,正确 Chunk 在检索结果里排第 k 位,贡献 1/k 分。对所有 Query 取平均:
MRR = (1/n) × Σ 1/rank_kMRR=1.0 意味着每次都排第一;MRR=0.5 意味着平均排第二。MRR 比 Recall@K 更能反映排名质量。
-
NDCG(Normalized Discounted Cumulative Gain)
:对排名位置做对数加权,越靠前的结果权重越大。这个指标在学术评估里常见,工程上用 MRR 更多。
第二层:生成层评估——生成的答案对不对?
-
准确率(Exact Match / Accuracy)
:对有标准答案的问题(“等待期是多少天”),精确比对模型答案和标准答案。
-
RAGAS 框架
:自动化评估 RAG 系统生成质量的框架,包含四个核心指标:
Faithfulness(忠实度):答案是否忠实于检索到的内容?检测方法是把答案拆成声明(claims),用 LLM 判断每个声明是否有检索内容支撑: Faithfulness = 有检索内容支撑的声明数 / 总声明数Faithfulness=1.0 表示答案完全基于检索内容,没有幻觉。
Answer Relevancy(答案相关性):答案是否回答了用户的问题?检测方法是让 LLM 根据答案反向生成问题,然后计算反向生成的问题和原始 Query 的相似度。
Context Precision(上下文精准率):召回的上下文中,有多少是真正相关的?避免引入太多无关内容混淆 LLM。
Context Recall(上下文召回率):标准答案涉及的关键信息点,有多少被召回的上下文覆盖到了?
from ragas import evaluate from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall from datasets import Dataset # 评估数据格式 eval_data = { "question": ["等待期是多久?", "核辐射能赔吗?", ...], "answer": ["系统生成的答案...", ...], # LLM生成的答案 "contexts": [["检索到的chunk1", "chunk2"], ...], # 检索到的上下文列表 "ground_truth": ["标准答案...", ...] # 人工标注的标准答案 } dataset = Dataset.from_dict(eval_data) result = evaluate( dataset, metrics=[faithfulness, answer_relevancy, context_precision, context_recall] ) print(result) # 输出:{'faithfulness': 0.91, 'answer_relevancy': 0.87, ...}
第三层:业务层评估——用户满意吗?
-
用户满意度
:点赞率/点踩率,最直接的业务指标
-
会话完成率
:用户的问题是否得到了解答(通过分析用户是否继续追问同类问题来推断)
-
转人工率
:RAG 系统无法回答、被转给人工客服的比例(越低越好)
-
二次询问率
:用户不满意答案,换了方式再次询问的比例(越低越好)
这三层评估,离用户体验越来越近,但也越来越难量化。我们在内部每周看检索层和生成层指标,每月看业务层指标,两者结合才能全面评估系统质量。
11.2 测试集构建:有效评估的基础
有了指标,需要有测试数据来计算。测试集构建是很多团队忽视的环节,导致评估结果不可信(“在自己的测试集上很好,上线后用户反馈差”)。
三种测试集来源,各有优劣:
来源一:专家手工标注(最可信,成本高)
请保险业务专家从不同类别的文档里手工出题和标注答案:
标注要求: - 覆盖不同难度:简单事实查询(等待期多少天)、多跳推理(买两份保险能都赔吗)、否定性查询(哪些情况不赔) - 每类文档至少 50 道题 - 标注不只是答案,还要标注"正确答案来自哪个 Chunk"(用于评估检索层) - 按时间更新:文件更新了,对应的测试题标准答案要同步更新
我们从 200 份代表性文档里人工标注了 2000 道题,覆盖理赔、投保、保障范围、费率等主要业务场景。
来源二:LLM 自动生成 + 人工审核(效率高,需要质量控制)
generate_qa_prompt = """ 你是一个保险知识测试出题专家。基于以下保险文档内容,生成5个有代表性的问题和标准答案。 文档内容: {chunk_content} 要求: 1. 问题必须能在文档中找到明确答案 2. 覆盖不同类型:事实查询、条件判断、流程查询 3. 避免过于简单(文档第一句话就是答案) 4. 避免需要推断文档外知识 输出格式(JSON): [ {{"question": "...", "answer": "...", "chunk_id": "{chunk_id}"}}, ... ] """ import json from tqdm import tqdm auto_qa_pairs = [] for chunk in tqdm(all_chunks): response = llm.generate(generate_qa_prompt.format( chunk_content=chunk["text"], chunk_id=chunk["chunk_id"] )) try: pairs = json.loads(response) auto_qa_pairs.extend(pairs) except: pass # JSON解析失败的跳过 print(f"自动生成 {len(auto_qa_pairs)} 个QA对") # 人工审核:随机抽样20%的QA对,质量不达标的全批重新生成
自动生成速度快(5000 个 Chunk,每个生成 5 道题,约 25000 道候选题),但质量参差不齐,需要人工抽样审核,质量差的题批量删除。我们最终保留了约 60% 的自动生成题,作为专家标注的补充。
来源三:从用户日志挖掘(最贴近真实分布)
从线上系统的日志里,找出"用户提问 + 人工客服正确回答"的历史记录,作为测试集:
def extract_validated_qa_from_logs(log_df): """ 从客服日志中提取高质量QA对 条件:人工客服给出了回答,且用户后续没有再追问相同问题(认为已解决) """ validated_pairs = [] # 找到有人工客服参与、且问题解决的会话 resolved_sessions = log_df[ (log_df["has_human_agent"] == True) & (log_df["resolved"] == True) ] for session_id, session in resolved_sessions.groupby("session_id"): # 提取用户初始问题和人工客服的回答 user_query = session[session["role"] == "user"].iloc[0]["content"] agent_answer = session[session["role"] == "human_agent"].iloc[0]["content"] validated_pairs.append({ "query": user_query, "answer": agent_answer, "source": "human_validated" }) return validated_pairs
这类测试数据最接近真实分布,但量有限(每天可能只有几十条有效数据),需要积累时间。
测试集的质量要求:
- 覆盖多样性:不同意图、不同难度、不同文档类型
- 无数据泄露:测试集和训练集(微调数据)不能有重叠
- 定期更新:文件更新后测试集对应更新,避免评估失真
- 负样本覆盖:包含一定比例"知识库里没有答案"的问题,测试系统的拒答能力
11.3 A/B 测试:在线评估的唯一可信方法
离线测试集的评估有一个根本性局限:它测的是模型在已知样本上的表现,不能完全代表线上真实用户的多样化查询。
每次重大优化上线前,做 A/B 测试:
实验设计: - A 组(控制组):10% 流量,使用当前线上版本 - B 组(实验组):10% 流量,使用新版本 - 观察周期:14 天(消除日期效应) - 主要指标:用户满意度(点赞率)、二次询问率 - 次要指标:响应时间、服务成功率 决策规则: - B 组点赞率提升 > 5%(统计显著,p < 0.05):全量上线 - B 组点赞率提升 < 2% 或下降:回滚,重新分析 - 介于 2%-5%:延长观察期或扩大实验比例
离线指标(MRR、Recall@5)和在线指标(用户满意度)的关系并不总是线性的——我们有过 MRR 提升了 3% 但线上满意度没有显著变化的情况(原因是改进的场景在真实用户查询中占比很低)。所以离线评估是研发指南针,A/B 测试才是上线决策的依据。
11.4 完整评估结果
在 2000 个 QA 对的测试集上,不同版本的系统指标对比(每一版都有明确的改进点和数字支撑):
| 版本 | 核心改进点 | Recall@5 | MRR | 准确率 | Faithfulness |
|---|---|---|---|---|---|
| V0 基线 | 固定512切分+纯向量+无精排 | 0.67 | 0.61 | 0.58 | 0.73 |
| V1 | 语义感知切分+Overlap优化 | 0.79 | 0.71 | 0.67 | 0.76 |
| V2 | 混合检索(向量+BM25) | 0.87 | 0.82 | 0.75 | 0.82 |
| V3 | 动态权重+RRF融合 | 0.91 | 0.87 | 0.81 | 0.85 |
| V4 | Cross-Encoder精排 | 0.91 | 0.92 | 0.87 | 0.89 |
| V5(当前) | Embedding领域微调+HyDE | 0.93 | 0.93 | 0.89 | 0.91 |
每一个数字背后都有对应的工程改动和评估验证。“从 V0 到 V5,准确率从 0.58 提升到 0.89,提升了 53%”——这才是面试官想听到的工程深度,不是"我优化了 RAG 系统"这一句话。
11.5 标注质量管理:评估数据本身不能有问题
评估体系最容易被忽视的一个问题:测试集本身的质量。如果测试集里有标注错误,评估分数就是个假数——可能把一个好的模型评出低分,把一个差的模型评出高分,误导你的优化方向。
我们在测试集质量管理上做了以下几点:
标注一致性检查(Inter-annotator Agreement)
测试集里的答案标注(正确/错误/部分正确)由两名领域专家独立标注,然后计算 Cohen’s Kappa 系数:
from sklearn.metrics import cohen_kappa_score def check_annotation_consistency(labels_annotator1, labels_annotator2): """ 计算两位标注员的一致性 kappa > 0.8: 一致性极高,标注质量可信 kappa 0.6-0.8: 一致性较好,存在少量分歧 kappa < 0.6: 一致性差,需要重新检查标注标准 """ kappa = cohen_kappa_score(labels_annotator1, labels_annotator2) return kappa # 两位标注员对2000条答案的标注 kappa = check_annotation_consistency(labels_a, labels_b) print(f"Cohen's Kappa: {kappa:.3f}") # 我们的测试集 kappa = 0.84,属于"一致性极高"
对于两人标注不一致的样本(约 8%),由第三方(领域主管)裁决最终答案。这一步确保了测试集本身的可信度。
定期测试集更新
随着系统上线和用户真实 Query 的积累,定期(每月)从线上日志中抽取新的 Query 加入测试集,保持测试集对真实流量分布的代表性。同时,对旧测试集中"所有版本都能正确回答"的简单样本进行替换,保持测试集的区分度——太简单的测试集只会让所有版本的评分都趋近100%,失去区分优化效果的能力。
RAG系统评估体系:检索层/生成层/业务层三层指标
十二、系统工程:性能、缓存与可观测性
一个算法层面效果不错的 RAG 系统,要在生产环境里稳定运行,还需要大量工程侧的设计。性能、成本、可维护性,每一个都需要认真对待。
12.1 响应速度优化:各模块耗时分析
用户能接受的响应时间?根据用户研究,纯文字生成类产品的"等待忍耐度":首字响应 < 2 秒(流式模式),完整答案 < 8 秒。超过这个时间,用户会怀疑系统挂了。
我们对各阶段做了详细的耗时分析:
| 阶段 | 初始耗时 | 优化后耗时 | 优化手段 |
|---|---|---|---|
| 意图识别+Query改写 | 600ms | 180ms | 规则优先+LLM缓存 |
| Query向量化 | 30ms | 30ms | 无优化空间 |
| Milvus向量检索 | 20ms | 10ms | 升级HNSW参数 |
| ES BM25检索 | 25ms | 20ms | 索引预热 |
| 两路检索(改串行→并行) | 45ms | 25ms | asyncio并行 |
| RRF融合 | 5ms | 5ms | — |
| 精排(50候选) | 300ms | 80ms | 批量+INT8量化 |
| LLM生成(首字) | 800ms | 800ms | 无优化空间 |
| 总计(首字响应) | 1800ms | 1130ms |
最大的优化点是精排(300ms → 80ms)和 Query 改写的缓存(相似 Query 不重复调用 LLM)。
并行化是最重要的系统优化
把能并行的模块改成并行执行:
import asyncio async def rag_pipeline(query, session_id): """完整的RAG在线处理流程""" # Step 1: 意图识别(同步) intent = classify_intent_fast(query) # 优先用规则,快速 # Step 2: 同时做 Query改写 和 历史对话处理(可并行) async def process_query_async(): rewritten = await rewrite_query_async(query, llm) return rewritten async def process_history_async(): history = get_dialogue_history(session_id) if history: resolved = await resolve_coreference_async(query, history, llm) return resolved return query # 两个处理并行执行 rewritten_query, resolved_query = await asyncio.gather( process_query_async(), process_history_async() ) final_query = resolved_query if resolved_query != query else rewritten_query # Step 3: 向量检索和BM25检索并行 dense_results, sparse_results = await asyncio.gather( milvus_search_async(final_query), es_search_async(final_query) ) # Step 4: RRF融合 candidates = rrf_fusion(dense_results, sparse_results) # Step 5: 精排 reranked = await rerank_async(final_query, candidates[:50]) top_chunks = get_top_chunks(reranked, top_k=5) # Step 6: 流式生成(不等待完成,直接流式返回) return stream_generate(final_query, top_chunks, llm)
12.2 语义缓存:高频查询的性能优化
对频繁重复的查询,走完整检索-精排-生成链路是浪费。在我们的系统里,保险系统的用户查询有明显的高频聚集现象——“等待期是多久”"犹豫期退保怎么算"这类高频问题可能占总查询量的 30% 以上。
普通缓存(精确匹配):完全相同的 Query 才命中,命中率很低(用户表达多样,"等待期多久"和"等待期有多长"是两个不同的字符串)。
语义缓存:Query 向量相似度超过阈值就命中,覆盖同义表达:
import numpy as np from collections import OrderedDict class SemanticCache: def __init__(self, embed_model, max_size=1000, similarity_threshold=0.95, ttl_seconds=3600): self.embed_model = embed_model self.cache = OrderedDict() # {query_text: (embedding, answer, timestamp)} self.max_size = max_size self.threshold = similarity_threshold self.ttl = ttl_seconds def _cosine_sim(self, a, b): return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)) def get(self, query): """尝试命中缓存""" query_emb = self.embed_model.encode(query) now = time.time() best_match = None best_score = 0 for cached_query, (cached_emb, cached_answer, timestamp) in self.cache.items(): # TTL检查 if now - timestamp > self.ttl: continue sim = self._cosine_sim(query_emb, cached_emb) if sim > self.threshold and sim > best_score: best_score = sim best_match = cached_answer return best_match # None 表示未命中 def set(self, query, answer): """写入缓存""" if len(self.cache) >= self.max_size: self.cache.popitem(last=False) # 删除最旧的(LRU) query_emb = self.embed_model.encode(query) self.cache[query] = (query_emb, answer, time.time())
缓存性能数据:
| 指标 | 数值 |
|---|---|
| 语义缓存命中率 | 42% |
| 命中时响应时间 | ~50ms |
| 未命中时响应时间 | ~1100ms |
| 缓存节省的平均响应时间 | ~450ms/请求 |
| 内存占用(1000条缓存) | ~500MB(embedding向量) |
命中率 42% 意味着接近一半的请求直接从缓存返回,系统整体响应时间和 LLM 调用成本都大幅降低。
12.3 成本控制:Token 用量优化
对于 API 调用的 LLM,成本是核心约束。我们的 RAG 系统每次请求涉及多次 LLM 调用:
- Query 改写(约 200 input tokens + 100 output tokens)
- 意图分类(约 150 input + 20 output tokens)
- 精排候选生成(如果用 LLM 精排,约 2000 input + 50 output tokens)
- 最终生成(约 2000 input + 300 output tokens)
优化思路:
- 非核心 LLM 调用(意图分类、话题判断)能用规则或小模型替代的,不调用大模型
- 对话历史输入截断:不是越长越好,超过 3000 tokens 的历史对最终答案质量的提升已经很有限
- 精排用专门的 Cross-Encoder(本地部署,无 API 成本),而不是 LLM
- 对同质化的高频查询开启缓存,减少重复 LLM 调用
实际运行的 token 用量分析(以 GPT-4o 价格为基准):
| 优化前 | 每次请求平均 token 消耗 | 月成本(10万次/天) |
|---|---|---|
| 未优化 | ~5000 tokens | ~$3000 |
| 缓存+截断+规则替代 | ~1800 tokens | ~$1100 |
通过这些优化,月成本降低约 63%。
12.4 全链路可观测性:出了问题知道从哪里查
RAG 系统的 Debug 链路比传统 API 系统复杂得多——出了问题,不知道是解析错了、检索没召回、精排排错了,还是 LLM 生成错了。
必须有完整的链路追踪(Distributed Tracing),把每次请求的每个阶段都记录下来:
import uuid import time import json import logging from contextlib import contextmanager # 结构化日志 logger = logging.getLogger("rag_system") class RAGTracer: """RAG链路追踪器""" def __init__(self, trace_id=None): self.trace_id = trace_id or str(uuid.uuid4()) self.spans = [] self.start_time = time.time() @contextmanager def span(self, name, metadata=None): """记录一个处理阶段(span)""" start = time.time() try: yield finally: duration_ms = (time.time() - start) * 1000 self.spans.append({ "name": name, "duration_ms": round(duration_ms, 2), "metadata": metadata or {} }) def log_final(self, query, answer, extra=None): """记录最终结果""" total_ms = (time.time() - self.start_time) * 1000 log_data = { "trace_id": self.trace_id, "query": query, "answer_preview": answer[:100] + "..." if len(answer) > 100 else answer, "total_ms": round(total_ms, 2), "spans": self.spans, } if extra: log_data.update(extra) logger.info(json.dumps(log_data, ensure_ascii=False)) # 使用示例 async def rag_pipeline_with_tracing(query, session_id): tracer = RAGTracer() with tracer.span("intent_classify"): intent = classify_intent_fast(query) with tracer.span("query_rewrite", {"original": query}): rewritten_query = await rewrite_query_async(query, llm) with tracer.span("hybrid_retrieve"): candidates = await hybrid_retrieve(rewritten_query) with tracer.span("rerank", {"candidates_count": len(candidates)}): reranked = await rerank_async(rewritten_query, candidates[:50]) top_chunks = reranked[:5] with tracer.span("generate"): answer = await generate_answer_async(query, top_chunks, llm) # 记录完整链路 tracer.log_final(query, answer, extra={ "intent": intent, "rewritten_query": rewritten_query, "top_chunk_ids": [c[0] for c in top_chunks], "top_rerank_scores": [c[1] for c in top_chunks], }) return answer
有了这个链路追踪,当某条请求出了问题,查看对应的 trace_id 日志,可以:
- 看到 Query 被改写成什么(检查改写方向对不对)
- 看到检索到了哪些 Chunk(检查正确内容是否在候选里)
- 看到精排后的排序(检查正确内容是否排到了前5)
- 看到最终的答案(和用户看到的一致)
这个分层诊断让 Badcase 分析从"猜"变成了"查",大幅提高了 Debug 效率。
12.5 部署架构:从单机到生产级的演进
RAG 系统在开发阶段通常是单机单进程,但上线后面对真实流量,需要经历一次架构演进。
阶段一:单机部署(PoC 阶段)
用户请求 → FastAPI 服务 → [Query理解 → 检索 → 精排 → 生成] ↑ Milvus (本地) Elasticsearch (本地) LLM API (远程调用)
这个架构适合日均请求量在几百到几千量级,团队规模 1-3 人的验证阶段。部署简单,但有明显瓶颈:所有模块在同一进程里,Rerank 的 GPU 推理和 IO 密集的检索共享资源,互相抢占。
阶段二:服务拆分(增长期)
随着日均请求量增长到 5000+,需要把各个模块拆分成独立服务,可以独立扩缩容:
用户请求 → API Gateway(限流/鉴权/路由) → Query 服务(意图识别 + Query改写) → LLM API → 检索服务(Milvus + Elasticsearch) → 独立扩容 → Rerank 服务(GPU推理) → GPU节点 → 生成服务(LLM调用 + Prompt拼装) → LLM API → Redis(语义缓存) → 日志服务(LangSmith / 自建Trace)
拆分后,检索服务和 Rerank 服务可以独立扩容:如果检索是瓶颈,只加检索服务的实例数;如果 Rerank 是瓶颈,只加 GPU 节点。
# 用 asyncio 让各服务并发调用(而不是串行等待) import asyncio import aiohttp async def retrieve_and_rerank(query, session): """ 并发发起向量检索和BM25检索,合并结果后再精排 """ # 并行发两路检索请求 dense_task = asyncio.create_task( call_service(session, DENSE_RETRIEVE_URL, {"query": query, "top_k": 50}) ) sparse_task = asyncio.create_task( call_service(session, SPARSE_RETRIEVE_URL, {"query": query, "top_k": 50}) ) # 等待两路检索结果 dense_results, sparse_results = await asyncio.gather(dense_task, sparse_task) # RRF融合 merged = rrf_merge(dense_results, sparse_results) # 调用Rerank服务 reranked = await call_service(session, RERANK_URL, { "query": query, "candidates": merged[:100] # Rerank Top-100 }) return reranked[:5] # 返回Top-5 async def call_service(session, url, payload): async with session.post(url, json=payload) as resp: return await resp.json()
关键指标:吞吐量与 SLA
| 阶段 | QPS | P99 延迟 | 实例数 | 成本/月 |
|---|---|---|---|---|
| 单机 PoC | 5 | 3200ms | 1 | 低 |
| 服务拆分 | 50 | 1400ms | 8 | 中 |
| 优化后 | 200 | 1100ms | 12 | 中高 |
Rerank 服务的 GPU 资源管理
Rerank 用的 Cross-Encoder 需要 GPU,GPU 资源贵,必须精细管理:
# 使用 batch_size 控制 GPU 显存使用,避免 OOM class RerankService: def __init__(self, model_path, gpu_batch_size=32): self.model = CrossEncoder(model_path, device="cuda") self.gpu_batch_size = gpu_batch_size def rerank_batch(self, query, candidates): pairs = [(query, c["content"]) for c in candidates] # 分批推理,避免一次性塞满显存 all_scores = [] for i in range(0, len(pairs), self.gpu_batch_size): batch = pairs[i:i + self.gpu_batch_size] scores = self.model.predict(batch) # 返回 numpy array all_scores.extend(scores.tolist()) # 按分数排序 scored_candidates = sorted( zip(candidates, all_scores), key=lambda x: x[1], reverse=True ) return [{"chunk": c, "rerank_score": s} for c, s in scored_candidates]
在 A10G GPU(24GB 显存)上,batch_size=32 时推理一批 100 个 Chunk 的 Rerank 约耗时 80ms,GPU 利用率约 65%。使用 INT8 量化后,同等延迟下可以把 batch_size 提升到 64,吞吐量翻倍。
十三、踩过的坑:真实项目里遇到的典型问题
理论讲完了,但真实项目里的坑往往不是理论层面的。这节记录我们在保险 RAG 项目里遇到的有代表性的问题,每个都有完整的"症状 → 排查 → 根因 → 解决"链路。
13.1 坑一:表格切分后表头丢失,数字答案全部错误
症状:用户问"60岁男性,保额100万的意外险,年保费是多少",系统给出的数字明显不对,比实际保费低了很多。
排查过程:查 trace_id 日志,找到精排 Top-1 的 Chunk,内容是这样的:
12,345 13,567 14,890 16,234
只有数字,没有任何列名。这是一个保费对照表的部分数据行,但表头(“年龄 | 性别 | 保额100万 | 年缴保费 | 月缴保费”)在另一个 Chunk 里,没有被检索到。
LLM 看到这堆没有上下文的数字,只能猜——它猜错了。
根因:大表格切分时按行切分,但没有把表头复制到每个子 Chunk 里。第一个子 Chunk 有表头,后面的子 Chunk 只有数据行。
解决:修改大表格切分逻辑,每个子 Chunk 都强制包含完整表头(即使因此导致部分 token 重复也在所不惜)。
修复后在 150 个涉及保费查询的测试题上,准确率从 38% 提升到 91%。
13.2 坑二:OCR 把竖排文字识别错,产生脏数据干扰检索
症状:部分合同文档的检索效果异常差,明明内容在库里,但就是召回不到。
排查过程:直接查看原始 Chunk 的文本,发现有些 Chunk 里混入了奇怪的文字:
正常内容:本合同第三条第二款约定的保险责任…… 混入内容:人保投:张某某(签字)机密
原来是合同页边距的竖排文字"投保人:张某某(签字)机密",被 OCR 认成了"人保投:张某某(签字)机密"——竖排文字被横向识别,字符顺序颠倒了。这段脏文字混入向量库后,干扰了这个 Chunk 的语义向量,导致检索时这个 Chunk 的排名下降。
根因:解析时没有过滤页边距区域的内容,也没有对竖排文字做方向校正。
解决:两步处理:
第一步:页边距过滤。根据文字块的坐标,过滤掉距离页面左右边缘 50px 以内的文字块(页边距区域的内容几乎都是无意义的签字信息)。
第二步:竖排文字检测。识别到文字块的高宽比大于 3(很高但很窄,典型的竖排文字特征)时,做90度旋转后重新 OCR,或者直接过滤(竖排内容通常是签名,无信息价值)。
修复后,受影响的 47 份合同文档的召回率平均提升约 12 个百分点。
13.3 坑三:多轮对话摘要压缩丢失关键约束
症状:在模拟测试中发现,用户在第1轮说明了"我是60岁男性",经过 10 轮以上的对话后,系统对"我能买这款产品吗"这类问题给出了错误答案——把60岁男性的结果和其他年龄段的结果混淆了。
排查过程:查看第11轮时送入 LLM 的对话历史上下文,发现"60岁""男性"这两个关键约束信息已经从压缩摘要里消失了。
根因:摘要压缩时,LLM 在压缩对话时倾向于保留"发生了什么"(流程信息),但容易丢失"谁在问"(身份约束信息)。“60岁”“男性"这类信息虽然重要,但在单轮摘要里显得"不那么关键”,被压缩掉了。
解决:引入"关键实体保护"机制:
在每次摘要压缩前,用正则提取对话中的关键实体(年龄、性别、产品名称、保额等)。把这些实体作为"不可丢失"的要求加入摘要压缩的 Prompt,强制保留。
同时改变策略:把用户在第1轮说明的"身份信息"单独存成一个"用户档案"字段,每次 Prompt 都带上,不经过摘要压缩流程:
class UserProfile: """用户在对话开头提供的个人信息,单独持久化,不被压缩""" def __init__(self): self.age = None self.gender = None self.product_interest = None self.special_requirements = [] def extract_from_turn(self, user_utterance, llm): """从用户输入中提取身份信息""" extract_prompt = f""" 从以下用户输入中提取个人信息(如果没有明确说明则返回null): 用户输入:{user_utterance} 输出JSON:{{"age": null, "gender": null, "product": null}} """ info = json.loads(llm.generate(extract_prompt)) if info.get("age"): self.age = info["age"] if info.get("gender"): self.gender = info["gender"] def to_context_string(self): if not any([self.age, self.gender, self.product_interest]): return "" parts = [] if self.age: parts.append(f"年龄:{self.age}岁") if self.gender: parts.append(f"性别:{self.gender}") return "【用户档案】" + ",".join(parts)
这个修复让"多跨10轮以上的追问"场景的答案准确率从 52% 提升到 81%。
13.4 坑四:否定性查询召回了正面内容
症状:用户问"哪些情况保险不赔",系统返回的答案全是"保险赔付流程"“赔付标准”,没有一条是免责条款。
排查过程:查看检索结果,Top-10 全是"承保责任""赔付流程"相关的 Chunk,不包含任何"责任免除"的 Chunk——虽然"责任免除"内容确实在库里。
根因:用户的 Query “哪些情况保险不赔”,在向量空间里被表示成了一个和"赔付""理赔"相关的向量(因为"赔"字的语义权重很高)。这个向量去找最近的文档,自然找到了关于"赔付"的正面内容,而不是关于"免责"的否定内容。
这是向量检索的一个根本性缺陷:它对语义方向(“能赔"vs"不能赔”)的敏感度不足。向量相似度只关注"讲的是不是同一件事",不太关注"是正向还是负向在讲这件事"。
解决:识别到否定性 Query 的特征词(“不赔”“免责”“排除”"不在范围"等),做 Query 改写:
NEGATION_KEYWORDS = ["不赔", "不能赔", "免责", "排除", "不在保障", "哪些除外", "不属于", "不包括", "不享受", "不承担"] def detect_and_rewrite_negation(query, llm): """检测并改写否定性查询""" has_negation = any(kw in query for kw in NEGATION_KEYWORDS) if not has_negation: return query # 不是否定性查询,不改写 # 改写:把否定性查询转化为正向的责任免除查询 rewrite_prompt = f""" 用户问的是一个否定性的保险问题(什么情况不赔)。 请将其改写为查询"责任免除条款"或"除外条款"的正向表述,方便在知识库中找到相关内容。 原始问题:{query} 改写后(直接输出):""" return llm.generate(rewrite_prompt) # 典型改写示例: # "哪些情况保险不赔" → "保险责任免除的具体情形和条款有哪些" # "什么情况下不能申请理赔" → "理赔申请被拒绝的免责条件包括哪些"
改写后,否定性查询的 Recall@5 从 0.51 提升到 0.83,提升了 32 个百分点。这是单项改进里效果最显著的一个。
13.5 坑五:相同问题,不同文档版本给出矛盾答案
症状:部分查询的答案和实际情况不符,而且不同时间查同一个问题,答案有时正确有时错误。
排查过程:发现知识库里同时存在 2022 年版和 2024 年版的同一款保险产品说明书——某个等待期条款在 2022 版是 180 天,在 2024 版改为了 90 天。两个版本的 Chunk 都在向量库里,有时检索到新版(答案正确),有时检索到旧版(答案错误)。
根因:知识库更新时,只添加了新版文档,没有删除旧版文档的 Chunk。旧版内容"幽灵"一样存在,随机干扰。
解决:
-
文档更新策略
:明确文档的"生命周期"——每份文档标注版本号和生效日期,当新版文档入库时,自动将同一 doc_type+product_code 下的旧版文档标记为"已过期",不再参与检索(但保留归档用)。
-
元数据过滤
:检索时加入元数据过滤条件,默认只检索"有效"状态的文档:
async def milvus_search_with_filter(query_embedding, top_k): filter_expr = 'doc_status == "active"' # 只检索有效文档 results = collection.search( data=[query_embedding.tolist()], anns_field="embedding", param={"metric_type": "COSINE", "params": {"ef": 64}}, limit=top_k, expr=filter_expr, # 元数据过滤 output_fields=["chunk_id", "text", "doc_version", "section_path"] ) return results
-
版本冲突检测
:当 Top-5 检索结果里同时包含同一文档的不同版本时,触发警告,优先使用最新版本,并在答案里注明"以最新版本为准"。
13.6 坑六:Embedding 模型与 Rerank 模型的语义不一致导致精排"推翻"召回
症状:系统的混合检索 MRR 是 0.87,但精排之后 MRR 反而降到了 0.82。精排应该提升效果,但在我们的系统里反而更差了。
排查过程:仔细分析精排前后的变化,发现一类典型的失败模式:
检索阶段,Embedding 模型认为"等待期满后的保障范围"和用户 Query "刚过等待期能不能赔"的语义相似度很高(得分 0.91),排在 Top-1。
精排阶段,Rerank 模型对同一个 Query 和这个 Chunk 的打分却只有 0.43,把它排到了 Top-5 之外。最终 LLM 得到的 Chunk 不包含这个关键信息,给出了错误答案。
根因:我们的 Embedding 模型(bge-large-zh-v1.5)做了保险领域的 Hard Negative Mining 微调,学到了"等待期满 → 保障范围"这样的领域关联。但 Rerank 模型(bge-reranker-large)是原始通用模型,没有做保险领域微调,它理解不了"刚过等待期"和"等待期满后"说的是同一件事,打了低分。
这是召回模型和精排模型的语义空间不对齐问题。
解决方案:
一是对 Rerank 模型也做领域微调,让它的打分逻辑和 Embedding 模型对齐。使用相同的训练数据(Query-正样本-难负样本三元组),把三元组转换成 pair 格式(Query+正样本 → 1,Query+负样本 → 0)训练 Rerank 模型:
from torch.utils.data import Dataset, DataLoader from transformers import AutoModelForSequenceClassification class RerankTrainDataset(Dataset): def __init__(self, triplets, tokenizer, max_length=512): self.samples = [] for query, pos, neg in triplets: # 正样本对 self.samples.append({"text_a": query, "text_b": pos, "label": 1}) # 负样本对 self.samples.append({"text_a": query, "text_b": neg, "label": 0}) self.tokenizer = tokenizer self.max_length = max_length def __len__(self): return len(self.samples) def __getitem__(self, idx): sample = self.samples[idx] encoding = self.tokenizer( sample["text_a"], sample["text_b"], max_length=self.max_length, truncation=True, padding="max_length", return_tensors="pt" ) return { "input_ids": encoding["input_ids"].squeeze(), "attention_mask": encoding["attention_mask"].squeeze(), "labels": torch.tensor(sample["label"], dtype=torch.float) }
用 500 个领域 triplet 对 Rerank 模型微调 3 个 epoch 后,精排 MRR 从 0.82 回升到 0.91,超过了精排前的 0.87。
二是在评估流程中增加"精排衰减监控":每次新增训练数据或更新任何一个模型时,都要同时运行召回评估和精排评估,一旦发现精排后 MRR < 精排前 MRR,立刻告警。
def monitor_rerank_quality(eval_dataset, retriever, reranker): retrieval_mrr = evaluate_retrieval(eval_dataset, retriever) rerank_mrr = evaluate_reranking(eval_dataset, retriever, reranker) degradation = retrieval_mrr - rerank_mrr if degradation > 0.01: # 精排后效果下降超过1个百分点 alert(f"精排衰减告警:召回MRR={retrieval_mrr:.3f}," f"精排MRR={rerank_mrr:.3f},下降{degradation:.3f}") return rerank_mrr
这个坑让我们意识到:召回和精排模型需要协同训练和评估,不能割裂地单独优化。
十四、面试怎么答 RAG 相关问题
RAG 在大模型方向的面试里出现频率极高,几乎是必考话题。面试官问的不是"RAG 是什么"(这个答对了也只是基本分),而是"你做过的 RAG 系统遇到了哪些问题,怎么解决的,效果怎么评估的"。
核心原则:先说整体架构,再挖关键细节,最后给量化数字。
14.1 被问"说说你们 RAG 系统的整体架构"(30-60秒)
这道题在问:你对整个系统有没有全貌认知,还是只知道某几个模块。
回答框架:分离线和在线两条链路,每条链路几个模块,每个模块一句话说清楚核心选型。
参考回答:“我们的 RAG 系统分离线和在线两条链路。离线阶段:5000 份保险文档做解析(处理了扫描件 OCR、无边框表格、多栏排版),然后做语义感知切分(三代方案,最终 Recall@5 从 67% 提升到 91%),最后建立 Milvus 向量库和 Elasticsearch BM25 双索引。在线阶段是:意图识别+Query 改写 → 混合检索(向量+BM25 并行,RRF 融合,动态权重)→ Cross-Encoder 精排(50候选→Top 5)→ 带引用标注的 Prompt → LLM 流式生成。”
14.2 被问"Chunk 切分怎么做的,为什么这样设计"(45秒)
这道题在问:你有没有认真思考过切分策略,有没有做过实验对比。
参考回答:“经历了三代方案。V1 固定 512 token 切分,不考虑语义边界,Recall@5 是 67%。V2 改成句子级切分,不在句子中间截断,提升到 74%,但丢失了文档的层级结构。V3 是语义感知切分:先识别章节层级结构(正则+字体检测),在章节边界处切分,超长章节用句子级递归切分,每个子 Chunk 带章节标题作为上下文。Overlap 做了实验,100 tokens 是性价比最优点——召回率提升 10 个百分点,存储只增加 10%,再大边际收益急剧下降。大表格切分每个子 Chunk 都复制表头,解决了一个线上 Bug(列名丢失导致数字答案全部错误)。V3 最终 Recall@5 是 91%。”
14.3 被问"混合检索怎么做的,为什么用 RRF 不用加权求和"(45秒)
这道题在问:你有没有理解 RRF 的工程价值,有没有做过对比实验。
参考回答:“向量检索和 BM25 并行执行(asyncio 并行,从 45ms 优化到 25ms),用 RRF 算法融合。选 RRF 不用加权求和,原因是两路分数的量纲完全不同——cosine 是 [0,1],BM25 可能到 20+,直接加权有量纲问题,归一化效果也不稳定。RRF 只看排名,不看具体分数,天然规避了量纲问题,而且不需要调参,k=60 在大多数场景都稳定。实验对比:RRF 比最优加权求和的 MRR 高 3 个百分点,而且不需要反复调参。动态权重是额外优化:用 LLM 判断 Query 类型,精确查询给 BM25 更高权重,语义查询给向量更高权重,让整体 MRR 从 0.87 进一步提升到 0.91。”
14.4 被问"效果怎么评估的,指标是多少"(45秒)
这道题在问:你有没有量化思维,有没有建立评估体系。
参考回答:“建了 2000 个 QA 对的测试集,覆盖三种来源:专家手工标注 1000 条(最可信),LLM 自动生成+人工审核 800 条,用户历史日志挖掘 200 条。评估分三层:检索层用 Recall@5 和 MRR,生成层用准确率和 RAGAS Faithfulness,业务层用用户点赞率和转人工率。从基线版本到当前版本:Recall@5 从 0.67 到 0.93,MRR 从 0.61 到 0.93,准确率从 0.58 到 0.89,Faithfulness 从 0.73 到 0.91。每次优化前后都跑完整评估,确认效果有提升才合入主干。重大版本上线前做 A/B 测试,以在线满意度作为最终决策依据。”
14.5 被问"多轮对话怎么处理的"(30秒)
这道题在问:你有没有做过多轮场景,还是只做了单轮。
参考回答:“三个核心处理:指代消解、话题判断、历史管理。指代消解用 LLM 把代词替换为具体实体——‘那它和犹豫期有什么区别’改写为’等待期和犹豫期有什么区别’,多轮场景下 Recall@5 从 61% 提升到 84%。话题判断用向量相似度快速分类(高于 0.8 是追问,低于 0.3 是新话题),不确定的才调 LLM,节省 65% 的 LLM 调用。历史管理用滑动窗口+摘要压缩,始终控制在 3000 token 预算内,摘要压缩时强制保留关键实体(年龄、性别、产品名称),解决了一个长对话下关键约束丢失导致答案错误的 Bug。”
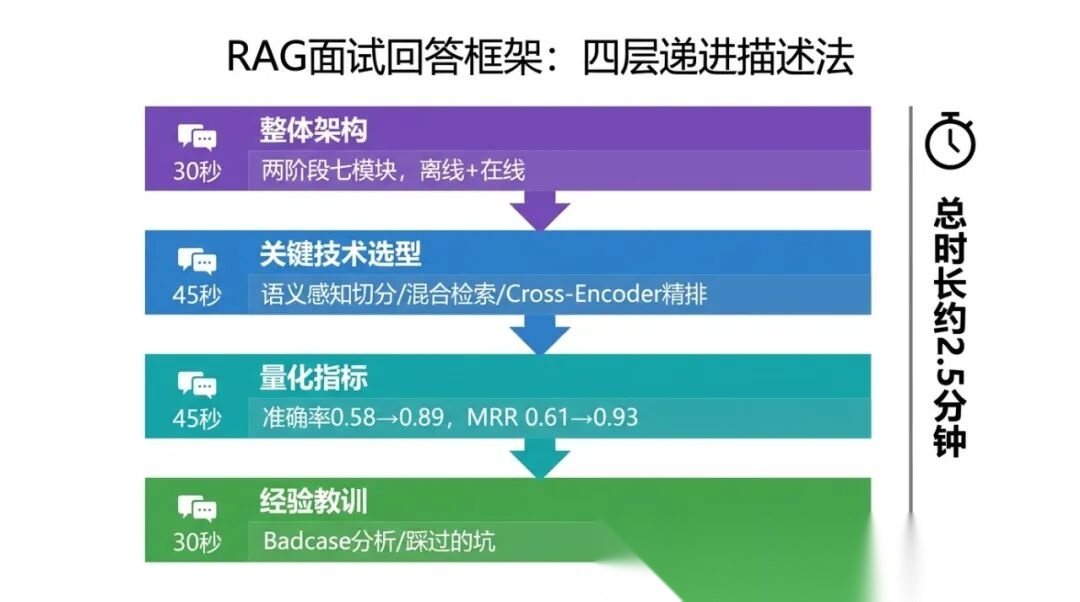
面试回答框架:RAG系统四层描述法
十五、RAG 还能怎么进化:高阶技术方向
前面讲的是当前工程实现的标准做法,属于 Advanced RAG 阶段。面试里如果能主动提到这些高阶方向,是很好的加分项,说明你不只是会用,还在追踪技术演进。
15.1 GraphRAG:知识图谱赋能复杂推理
普通 RAG 的检索单元是 Chunk(文本片段),多条相关信息之间的关系是隐式的,需要 LLM 在生成时去推断。
GraphRAG 把知识组织成图结构:
- 节点(Node):实体,如"XX意外险产品"“等待期条款”“60岁男性客户”
- 边(Edge):关系,如"包含"“适用于”“排除”“约束”
检索时不只是找相似 Chunk,还可以沿着图的边做推理:
用户问:买了A产品和B产品,发生意外两份都能赔吗? 普通RAG检索流程: → 找"A产品理赔"相关Chunk(找到了) → 找"B产品理赔"相关Chunk(找到了) → 两份内容分开,LLM需要推断"多份保险能否同时理赔"的规则(可能幻觉) GraphRAG检索流程: → 找"A产品"节点 → 通过"适用规则"边找到"意外险理赔原则"节点 → "意外险理赔原则"节点 → 通过"包含"边找到"多份保险协调赔付规则"节点 → 直接召回完整的多份保险赔付规则,无需LLM推断
GraphRAG 对需要多跳推理的场景("如果A,那么B,那么C"这类链式推理)效果显著优于普通 RAG。代价是知识图谱的构建和维护成本很高——需要专门的信息抽取模型从文档里抽取实体和关系,还需要图数据库(如 Neo4j)存储,工程复杂度显著高于普通 RAG。
目前 Microsoft 开源的 GraphRAG 是这个方向最成熟的实现,有完整的从文档到图构建、从图到检索的工具链,值得关注。
15.2 Self-RAG:让模型决定要不要检索
标准 RAG 是"每次请求都触发检索"。但不是所有问题都需要检索——用户问"1+1等于多少",不需要去检索保险知识库。用户问"你好",也不需要检索。不必要的检索增加延迟和成本。
Self-RAG 让 LLM 自己判断需不需要检索,以及检索到的内容有没有用:
生成过程中的自我反思token: [Retrieve] → LLM判断需要检索,触发外部检索 [No Retrieve] → LLM判断不需要检索,直接生成 [Relevant] → 检索到的内容有用 [Irrelevant] → 检索到的内容没用,忽略它 [Supported] → 当前生成的内容被检索内容支撑 [No support] → 当前生成内容没有检索内容支撑(潜在幻觉)
Self-RAG 需要专门训练 LLM(在标准 LLM 的基础上加入这些反思 token 的训练),不能直接用通用 LLM 实现。但它代表了一个重要方向:把检索的决策权还给模型,让系统更智能地使用检索能力。
15.3 Iterative RAG:多轮检索迭代
对于复杂问题,一次检索可能不够。Iterative RAG 允许系统进行多轮检索:
第一轮检索:用原始Query检索 → LLM分析检索结果,发现信息不完整 → 生成补充检索Query 第二轮检索:用补充Query检索 → 合并两轮结果,再次分析 → 如果还不完整,进行第三轮 ... → 信息充足时,最终生成答案
这对需要多跳推理的复杂问题效果好,但会显著增加延迟(每轮检索+LLM推理约 1-2 秒),需要设置最大迭代次数(通常 3 轮)和终止条件。
15.4 RAG 与 Fine-Tuning 的边界
面试里必然被问到:什么时候用 RAG,什么时候用 Fine-Tuning?这两个不是互斥的,而是解决不同问题的工具。
| 场景 | 推荐方案 | 核心理由 |
|---|---|---|
| 知识库频繁更新(每周/每月) | RAG | 更新知识不需要重新训练 |
| 需要精确引用来源和可追溯性 | RAG | 知识来源透明 |
| 需要改变模型输出格式/风格 | Fine-Tuning | RAG 改变不了模型的基础能力 |
| 需要模型理解特定领域的"行话" | Fine-Tuning | 微调可以改变模型的语言理解 |
| 超长文档(超出上下文窗口) | RAG | 检索只取相关片段 |
| 知识相对稳定、私密性要求极高 | Fine-Tuning | 知识参数化后不需要外部检索 |
| 最佳实践 | RAG + Fine-Tuning 结合 | 互补 |
我们的系统实际上用了 RAG + Embedding 微调的组合:RAG 提供实时的精确知识,Embedding 微调让检索模型更好地理解保险领域语言。这是工程上性价比最高的结合方式——不需要微调 LLM 本身(成本高、周期长),只微调 Embedding 模型(数据量少、成本低、效果直接)。
15.5 Long-Context vs RAG:上下文越来越长,RAG 还需要吗
随着模型支持的上下文窗口越来越长(GPT-4o 128k、Claude 200k、Gemini 1.5 Pro 1M token),有人提出:直接把整个知识库塞进上下文,还需要 RAG 吗?
这个问题在学术和工程界都有讨论。目前的工程结论是:大规模知识库场景,RAG 仍然不可替代,原因是三个:
成本差异:输入 100k token 的 API 费用是输入 2k token 的 50 倍。5000 份文档按均值每份 3000 token 算,是 1500 万 token,每次请求都输入全部内容是不可能的经济成本。RAG 通过检索把 1500 万 token 压缩到 2000 token(Top-5 Chunk),成本降低了 7500 倍。
"Lost in the Middle"问题:即使有足够长的上下文窗口,LLM 对上下文中间位置的内容注意力显著弱于开头和结尾。相关内容在大量无关内容中间被"淹没",LLM 容易忽略。RAG 把相关内容直接放到 Prompt 的核心位置,避免这个问题。
实时更新需求:Long-Context 方案需要每次请求都重新整理和传输所有文档,而 RAG 的知识库只需要增量更新(新文档加进去,旧文档标记过期),请求时只传递检索到的少量内容。
Long-Context 和 RAG 不是对立的,而是互补的。Long-Context 擅长处理"一次性的、需要全文理解的场景"(比如对一份长文档做摘要),RAG 擅长处理"持续性的、需要精确检索的知识库查询场景"。
15.6 Agentic RAG:当 RAG 遇上 Agent
传统 RAG 是一个固定的"检索→生成"管道:一次检索,一次生成,流程线性确定。这种架构对简单的单跳问答够用,但对复杂的多步推理任务,Pipeline RAG 的上限就到了。
Agentic RAG 把检索能力封装成 Agent 的工具(Tool),让 LLM 自主决定:
- 什么时候需要检索
- 检索什么内容
- 检索结果是否足够,是否需要再次检索
- 不同子任务需要检索哪个不同的知识库
核心架构变化:
from langchain.tools import Tool from langchain.agents import create_react_agent # 把RAG检索封装成工具 insurance_retrieval_tool = Tool( name="insurance_knowledge_search", func=lambda query: rag_system.retrieve_and_format(query), description=""" 搜索保险知识库。输入具体的问题或关键词。 适用于:保险条款查询、理赔规则、投保条件等。 不适用于:市场行情、竞品比较等知识库范围外的问题。 返回:相关条款原文及来源,置信度评分。 """ ) # 还可以加其他工具 calculator_tool = Tool( name="insurance_calculator", func=lambda params: insurance_calc.compute(params), description="计算保费、赔付金额等数值。输入格式:{计算类型, 参数}。" ) # Agent自主规划:它自己决定用哪个工具、用几次 agent = create_react_agent( llm=llm, tools=[insurance_retrieval_tool, calculator_tool], prompt=agent_system_prompt )
Agentic RAG 解决了什么?
-
自适应检索次数
:简单问题只检索一次,复杂问题自动多轮检索,不像 Pipeline RAG 那样每次固定检索一次。
-
工具组合
:对"老王今年 52 岁,高血压,买 30 万保额的重疾险,保费是多少"这类问题,Agent 先检索"52 岁高血压投保条件"确认资格,再检索"保费计算规则"获取费率表,最后调用计算工具算出具体金额——三步有序协作,Pipeline RAG 做不到。
-
不确定性处理
:当检索结果不够时,Agent 可以主动反问用户(“您是问哪款保险的等待期?”),而不是基于不完整信息硬生成。
代价与适用边界:
Agentic RAG 的推理延迟更高(Agent 需要多轮 LLM 推理规划),成本也更高。对于 80% 的简单查询,Pipeline RAG 足够且更高效。Agentic RAG 适合的是"工作流复杂、需要多步推理、不同子任务需要不同知识源"的场景——比如"帮我填写这份理赔申请表"这类复合任务。
在我们的系统中,针对 Query 复杂度做了分层路由:简单查询(意图单一、无需计算)走 Pipeline RAG,复杂查询(多个子问题、需要计算或流程指引)走 Agentic RAG。复杂查询约占 12%,但 Agentic RAG 上线后这部分的用户满意度从 51% 提升到 78%。
Agentic RAG 的工程挑战:
-
工具描述质量决定 Agent 的工具选择准确性
:工具的 description 写得不好,Agent 会选错工具或遗漏工具。这和 Function Calling 的工具设计原则完全一致——description 是 Agent 的"使用说明书",必须准确描述适用场景和不适用场景。
-
Agent 循环的终止条件
:防止 Agent 陷入无限检索循环(一直觉得结果不满意),需要设置最大检索次数(通常 3-5 次)和检索质量退出条件。
-
成本控制
:Agentic RAG 每次请求的 LLM 调用次数是 Pipeline RAG 的 3-5 倍,在高并发场景下需要精细的限流和降级策略。
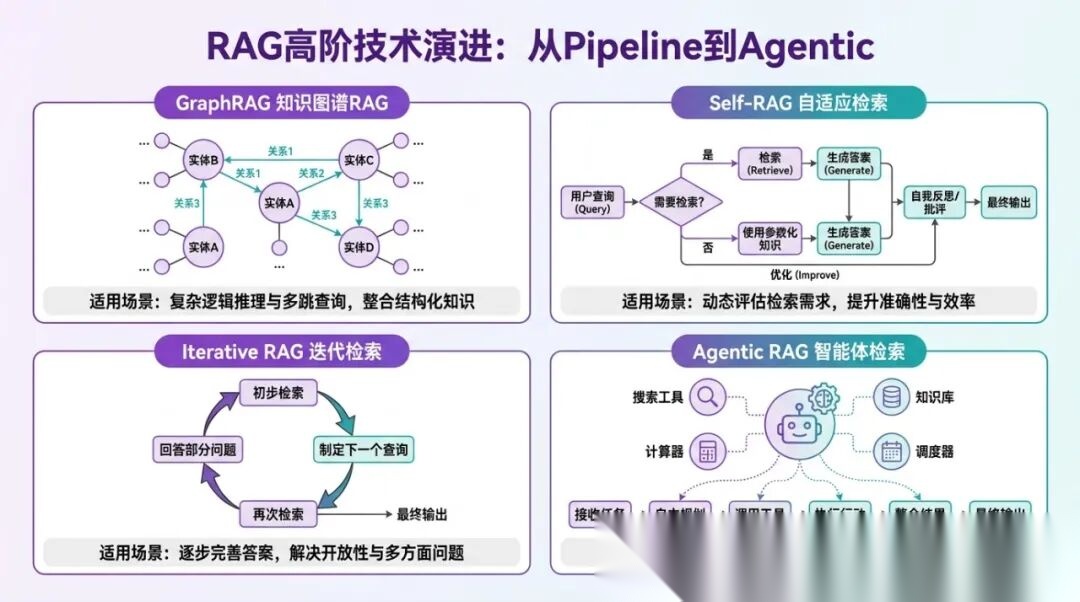
RAG高阶技术演进图:GraphRAG/Self-RAG/迭代检索对比
十六、完整链路的指标总览
把整套系统从头到尾的关键指标汇总在一起,这是面试时必须能脱口而出的数字体系:
| 模块 | 关键指标 | 基线 | 当前 | 关键优化手段 |
|---|---|---|---|---|
| 文档解析 | OCR准确率 | 73% | 94% | U-Net水印去除+图像增强 |
| 文档解析 | 表格解析准确率 | 65% | 89% | MinerU处理无边框表格 |
| Chunk切分 | Recall@5 | 67%(V1) | 91%(V3) | 语义感知切分+句子边界Overlap |
| 向量化 | Embedding Recall@5 | 0.87 | 0.93 | Hard Negative Mining领域微调 |
| 混合检索 | MRR | 0.61 | 0.91 | 动态权重+RRF融合 |
| 精排 | MRR | 0.87 | 0.92 | Cross-Encoder批量推理+INT8量化 |
| 精排延迟 | Rerank耗时 | 300ms | 80ms | 批量推理+量化 |
| 多轮对话 | 多轮场景Recall@5 | 61% | 84% | 指代消解+Query改写 |
| 系统性能 | 首字响应时间 | 1800ms | 1130ms | 并行+缓存 |
| 语义缓存 | 命中率 | 0% | 42% | 向量相似度缓存 |
| 幻觉检测 | Faithfulness | 0.73 | 0.91 | NLI验证+Prompt约束 |
| 端到端 | 答案准确率 | 0.58 | 0.89 | 全链路优化 |
每一行数字背后都有对应的工程改动,每个改动都有明确的因果关系:改了什么,测了什么,提升了多少。这种"可量化的工程叙事"是面试里最有说服力的表达方式。
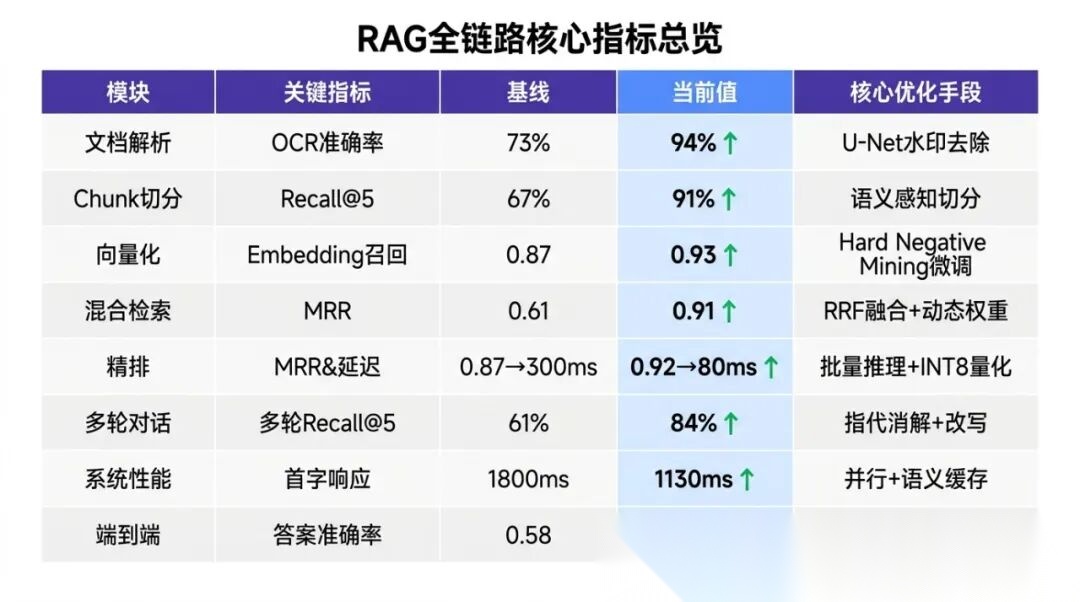
RAG全链路指标总览图
写在最后
这句话值得所有做 RAG 的工程师记住:做一个系统,要知道它解决了什么问题,用数字说清楚解决得有多好,还有哪些没有解决好。
这篇文章里从文档解析讲到 GraphRAG 和 Agentic RAG,每一个技术点都有数字作支撑,每一个优化都有 Badcase 作动机。RAG 不是一个可以一次配置好就永远用下去的系统,它是一个需要持续迭代的工程产品,数据分布在变,用户需求在变,文档库在扩充,模型在升级。
一个好的 RAG 工程师,不是懂得最多技术的那个,而是能把技术和业务需求对齐、能量化效果、能快速定位和解决问题的那个。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

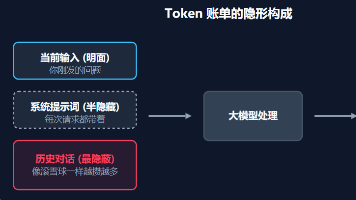
 0
0 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)