
什么是检索增强生成,它如何赋能于生成式人工智能?
在当前人工智能领域,检索增强生成Retrieval-Augmented Generation(RAG)正成为热议话题。得益于RAG,用户在使用Github Copilot时更智能、更便捷、输出信息与互联网信息更同步。欢迎阅读本文,了解RAG及其功能。如需了解更多Copilot信息,敬请关注创实信息。
在当前人工智能领域,检索增强生成Retrieval-Augmented Generation(RAG)正成为热议话题。
RAG是一种利用多种数据源提高人工智能模型输出质量和相关性的方法。它使得AI工具能够获取专有数据,而无需耗费精力和费用进行自定义模型训练。使用RAG还能确保模型保持最新状态,让模型利用包含更新信息的私有数据库做出更明智的响应。
得益于RAG,用户在使用Github Copilot时更智能、更便捷、输出信息与互联网信息更同步。
欢迎阅读本文,了解RAG及其功能。如需了解更多Copilot信息,敬请关注创实信息——我们是Github的中国官方授权合作伙伴,提供GitHub Copilot的咨询、销售、实施、培训及技术支持服务,帮助您更好地使用GitHub Copilot,获取更好的AI编码体验,提升编码速度。
为什么每个人都在谈论RAG
您始终需要验证生成式人工智能工具输出内容的原因之一是:它的训练数据有知识截止日期。虽然模型能够根据定制的请求来生成输出,但它们只能参考训练时存在的信息。但通过 RAG,人工智能工具可以使用模型训练数据之外的数据源来生成输出。
RAG和微调的区别
大多数组织目前不训练自己的人工智能模型。相反,他们通常使用 RAG 或微调来根据自己的特定需求定制预训练模型。以下内容快速分析了这两种策略的不同点。
微调需要调整模型的权重,从而产生擅长特定任务的高度定制模型。对于那些依赖用专门语言编写的代码库的组织来说,这是不错的选择,特别是当该语言在模型的原始训练数据中没有得到很好的体现时。
另一方面,RAG不需要权重调整。相反,它从各种数据源检索和收集信息以增强提示,从而使人工智能模型为最终用户生成与上下文更相关的响应。
一些组织从RAG开始,然后微调其模型以完成更具体的任务。另一些组织发现RAG本身就足以用于AI定制。
AI 模型如何运用上下文
为了让人工智能工具产生有用的响应,它需要正确的上下文。这与我们作为人类在做出决定或解决问题时面临的困境相同。当您没有正确的信息来采取行动时,这很难做到。
那么,让我们在生成式AI的语境中更多地讨论上下文:
当今的生成式人工智能应用程序由大型语言模型(LLM)提供支持,这些模型被构造为Transformer,并且所有Transformer LLM都有一个上下文窗口——单个提示中可以接受的数据量。尽管上下文窗口的大小有限,但随着更强大的模型的发布,它们可以且将变得更大。
输入数据将根据人工智能工具的功能而有所不同。例如,当涉及IDE中的 GitHub Copilot时,输入数据包含您当前正在处理的文件中的所有代码。这是因为我们的中间填充(FIM)范例使 GitHub Copilot能够识别光标之前(前缀)和光标之后(后缀)的代码。
GitHub Copilot还会处理其他打开的选项卡中的代码(我们把这个处理过程称为相邻选项卡),以潜在地查找相关信息并将其添加到提示中。当有很多打开的选项卡时,GitHub Copilot将扫描最近查看的选项卡。
由于上下文窗口的大小有限,机器学习工程师面临的挑战是弄清楚要添加到提示中的输入数据以及以什么顺序从人工智能模型生成最相关的建议。这项任务被称为提示工程。
RAG 如何增强 AI 模型的上下文理解
借助 RAG,大语言模型可以超越训练数据,从各种数据源(包括定制数据源)检索信息。
当涉及GitHub.com和 IDE 中的 GitHub Copilot Chat时,无论是代码还是自然语言,通过一个称为上下文学习的过程,输入数据可以包括您与聊天助手的对话,还可以包括来自索引存储库(公共或私有)的数据、跨存储库的 Markdown文档集合(我们称为知识库)以及来自集成搜索引擎的结果。 RAG将从这些其他来源恢复附加数据以增强初始提示。因此,它可以生成更相关的响应。
GitHub Copilot使用的输入数据类型取决于您使用的GitHub Copilot 计划。
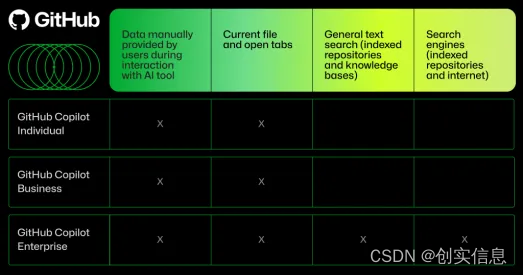
RAG 和语义搜索
与关键字搜索或布尔搜索运算符不同,机器学习驱动的语义搜索系统使用其训练数据来理解关键字之间的关系。因此,语义搜索系统不会像在关键字搜索中那样将“猫”和“小猫”视为独立的术语,而是可以通过训练来理解这些单词通常与可爱的动物视频有关。因此,搜索“猫和小猫”可能会将可爱的动物视频列为热门搜索结果。
语义搜索如何提高 RAG 检索的质量?当使用定制数据库或搜索引擎作为RAG 数据源时,语义搜索可以改善添加到提示中的上下文以及 AI 生成输出的整体相关性。
语义搜索过程是检索的核心。
开发人员可以使用 GitHub.com 上的 Copilot Chat 以自然语言提出问题并接收有关代码库的答案,或者显示相关文档和现有解决方案。
RAG 数据源:RAG 在何处使用语义搜索
您可能已经阅读过数十篇讨论 RAG、向量数据库和嵌入的文章(包括我们自己的一些文章)。即使您还没有,您也应该了解:RAG 不需要嵌入或向量数据库。
RAG 系统可以使用语义搜索来检索相关文档,无论是来自基于嵌入的检索系统、传统数据库还是搜索引擎。然后,这些文档中的片段将被格式化为模型的提示。我们将快速回顾矢量数据库,然后使用 GitHub Copilot Enterprise 作为示例,介绍RAG 如何从各种来源检索数据。
向量数据库
向量数据库针对存储库代码和文档的嵌入进行了优化。它们允许我们使用新颖的搜索参数来查找相似向量之间的匹配。
为了从向量数据库中检索数据,代码和文档被转换为嵌入向量(一种高维向量),以便 RAG 系统可以搜索它们。
以下是 RAG 从向量数据库检索数据的方式:当您在 IDE 中编码时,算法会为代码片段创建嵌入向量,这些代码片段存储在向量数据库中。然后,人工智能编码工具可以通过嵌入向量来计算相似度,以此搜索该数据库,以从代码库中查找与您当前正在编写的代码相关的片段,并生成编码建议。这些片段通常与上下文高度相关,使人工智能编码助手能够生成与上下文更相关的编码建议。GitHub Copilot Chat 在 IDE 和 GitHub.com 中使用嵌入相似性,因此它可以找到与您的查询相关的代码和文档片段。
嵌入向量计算相似度非常强大,因为它可以识别与您正在编辑的代码有微妙关系的代码。
嵌入向量计算相似度可能会显示使用相同 API 的代码,或者执行与您的任务类似但位于代码库的另一部分的代码。当这些示例被添加到提示中时,该模型就准备好生成模仿您的代码库中固有的习惯用法和技术的响应,即使该模型没有根据您的代码进行过训练。
通用文本搜索和搜索引擎
通过通用文本搜索,您希望 AI 模型访问的任何文档都会提前建立索引并存储以供日后检索。例如,GitHub Copilot Enterprise 中的 RAG 可以从索引存储库中的文件和跨存储库的 Markdown 文件检索数据。
RAG 还可以从外部和内部搜索引擎检索信息。当与外部搜索引擎集成时,RAG 可以从整个互联网搜索和检索信息。当与内部搜索引擎集成时,它还可以访问组织内部的信息,例如内部网站或平台。集成这两种搜索引擎增强了 RAG 提供相关响应的能力。
例如,GitHub Copilot Enterprise 将外部搜索引擎 Bing 和GitHub 构建的内部搜索引擎集成到 GitHub.com 上的 Copilot Chat 中。Bing 集成允许 GitHub Copilot Chat 进行网络搜索并检索最新信息,例如有关最新 Java 版本的信息。但如果没有搜索引擎进行内部搜索,GitHub.com 上的 Copilot Chat 就无法回答有关您的私人代码库的问题,除非您自己提供特定的代码参考。
这在实践中是如何运作的。当开发人员向 GitHub.com 中的GitHub Copilot Chat 询问有关存储库的问题时,Copilot Enterprise中的RAG 使用内部搜索引擎从索引文件中查找相关代码或文本来回答该问题。为此,内部搜索引擎通过分析索引存储库中的文档内容来进行语义搜索,然后根据相关性对这些文档进行排名。然后,GitHub Copilot Chat使用 RAG(再进行语义搜索)从排名靠前的文档中查找和检索最相关的片段。这些片段将添加到提示中,以便 GitHub Copilot Chat可以为开发人员生成相关响应。
关于 RAG 的要点
RAG 提供了一种定制 AI 模型的有效方法,有助于确保输出的信息与组织知识和最佳实践以及与互联网上的最新信息保持同步。
GitHub Copilot 使用多种方法来提高输入数据的质量并将初始提示置于上下文中,并且通过 RAG 增强了这种能力。此外,GitHub Copilot Enterprise中的RAG 检索方法超越了向量数据库,还包括通用文本搜索和搜索引擎集成等数据源,从而提供更具成本效益的检索。
想要充分利用人工智能工具,上下文就是一切。为了提高生成式人工智能输出的相关性和质量,您需要提高输入的相关性和质量。
作者:Nicole Choi
文章来源:https://github.blog/2024-04-04-what-is-retrieval-augmented-generation-and-what-does-it-do-for-generative-ai/

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)